Lecture 5와 6을 통해 배운 Quantization 내용 중에 K-means Quantization과 Linear Quantization에 대해 실습하며 배워보는 Lab2에 대한 풀이와 설명에 대한 포스팅이다. 기존의 실습 노트는 Original 강의의 링크를, 한국어 번역과 Solution은 이 링크를 참고하면 됩니다. 아래 Colaboratory 버튼을 누르면 실습노트를 바로 실행시키는 Colab Notebook을 실행시킬 수 있습니다.
Lab 2: Quantization
Goals
이번 실습에서는 모델 크기와 지연 시간을 줄이기 위해 클래식한 neural network model을 quantizing하는 연습을 할 것입니다. 이 실습의 목표는 다음과 같습니다:
Quantization의 기본 개념을 이해합니다.
k-means quantization을 구현하고 적용합니다.
k-means quantization에 대해 quantization-aware training을 구현하고 적용합니다.
linear quantization을 구현하고 적용합니다.
linear quantization에 대해 integer-only inference를 구현하고 적용합니다.
Quantization에서의 성능 개선(예: 속도 향상)에 대한 기본적인 이해를 얻습니다.
이러한 quantization 접근 방식 사이의 차이점과 트레이드오프를 이해합니다.
Contents
주요 섹션은 K-Means Quantization 과 Linear Quantization 2가지로 구성되어 있습니다.
이번 실습 노트에서 총 10개의 질문을 통해 학습하게 됩니다.:
K-Means Quantization에 대해서는 3개의 질문이 있습니다 (Question 1-3).
Linear Quantization에 대해서는 6개의 질문이 있습니다 (Question 4-9).
Question 10은 k-means quantization과 linear quantization을 비교합니다.
실습노트에 대한 설정 부분(Setup)은 Colaboratory Note를 열면 확인하실 수 있습니다. 포스팅에서는 보다 실습내용에 집중할 수 있도록 생략되어 있습니다.
먼저 FP32 Model의 정확도와 모델 크기를 평가해봅시다
fp32_model_accuracy = evaluate(model, dataloader['test'])fp32_model_size = get_model_size(model)print(f"fp32 model has accuracy={fp32_model_accuracy:.2f}%")print(f"fp32 model has size={fp32_model_size/MiB:.2f} MiB")
fp32 model has accuracy=92.95%
fp32 model has size=35.20 MiB
K-Means Quantization
Network quantization은 deep network를 표현하는 데 필요한 가중치 당 비트(bits per weight) 수를 줄여 네트워크를 압축합니다. quantized network는 하드웨어 지원이 있을 경우 더 빠른 추론 속도를 가질 수 있습니다.
\(n\)-bit k-means quantization은 시냅스를 \(2^n\) 개의 클러스터로 나누고, 동일한 클러스터 내의 시냅스는 동일한 가중치 값을 공유하게 됩니다.
따라서, k-means quantization은 다음과 같은 codebook을 생성합니다: * centroids: \(2^n\) fp32 클러스터 중심. * labels: 원래 fp32 가중치 텐서와 동일한 #elements를 가진 \(n\)-bit 정수 텐서. 각 정수는 해당 클러스터가 어디에 속하는지를 나타냅니다.
from collections import namedtupleCodebook = namedtuple('Codebook', ['centroids', 'labels'])
Question 1 (10 pts)
아래의 K-Means quantization function을 완성하세요.
from fast_pytorch_kmeans import KMeansdef k_means_quantize(fp32_tensor: torch.Tensor, bitwidth=4, codebook=None):""" quantize tensor using k-means clustering :param fp32_tensor: :param bitwidth: [int] quantization bit width, default=4 :param codebook: [Codebook] (the cluster centroids, the cluster label tensor) :return: [Codebook = (centroids, labels)] centroids: [torch.(cuda.)FloatTensor] the cluster centroids labels: [torch.(cuda.)LongTensor] cluster label tensor """if codebook isNone:############### YOUR CODE STARTS HERE ################ get number of clusters based on the quantization precision n_clusters =2** bitwidth # Calculate number of clusters as 2^bitwidth############### YOUR CODE ENDS HERE ################## use k-means to get the quantization centroids kmeans = KMeans(n_clusters=n_clusters, mode='euclidean', verbose=0) labels = kmeans.fit_predict(fp32_tensor.view(-1, 1)).to(torch.long) centroids = kmeans.centroids.to(torch.float).view(-1) codebook = Codebook(centroids, labels)############### YOUR CODE STARTS HERE ################ decode the codebook into k-means quantized tensor for inference# hint: one line of code quantized_tensor = codebook.centroids[codebook.labels].view_as(fp32_tensor)############### YOUR CODE ENDS HERE ################# fp32_tensor.set_(quantized_tensor.view_as(fp32_tensor))return codebook
위에서 작성한 k-means quantization function을 더미 텐서에 적용하여 확인해봅시다.
test_k_means_quantize()
tensor([[-0.3747, 0.0874, 0.3200, -0.4868, 0.4404],
[-0.0402, 0.2322, -0.2024, -0.4986, 0.1814],
[ 0.3102, -0.3942, -0.2030, 0.0883, -0.4741],
[-0.1592, -0.0777, -0.3946, -0.2128, 0.2675],
[ 0.0611, -0.1933, -0.4350, 0.2928, -0.1087]])
* Test k_means_quantize()
target bitwidth: 2 bits
num unique values before k-means quantization: 25
num unique values after k-means quantization: 4
* Test passed.
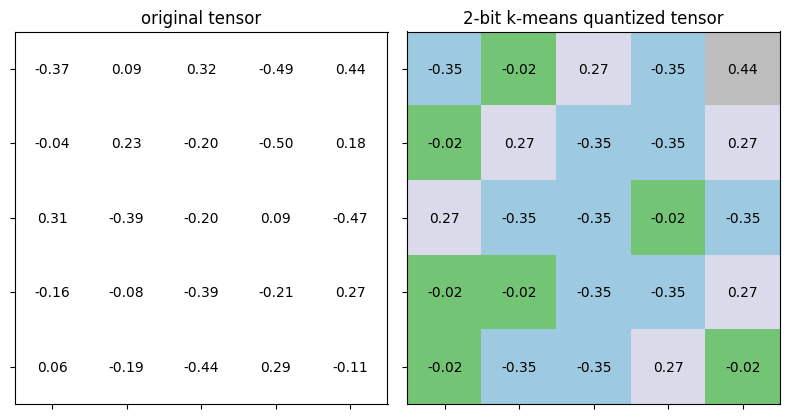
Question 2 (10 pts)
마지막 코드 셀은 2비트 k-means quantization을 수행하고 quantization 전후의 텐서를 플롯합니다. 각 클러스터는 고유한 색상으로 렌더링되며, quantized 텐서들이 4(\(2^2\))가지 고유한 색상으로 표시됩니다.
이러한 현상을 관찰한 것을 바탕으로 질문들에 답하세요.
Question 2.1 (5 pts)
4비트로 k-means quantization이 수행되면, quantized 텐서에는 몇 개의 고유한 색상이 렌더링될까요?
Your Answer:
4비트 k-means quantization이 수행되면, quantized 텐서에 \((2^4 = 16)\)개의 고유한 색상이 렌더링됩니다. 이는 4비트로 0000부터 1111까지의 16가지 다른 상태나 조합을 나타낼 수 있으며, 이는 텐서 값이 그룹화될 수 있는 16개의 고유한 클러스터에 해당합니다.
Question 2.2 (5 pts)
n-비트 k-means quantization이 수행되면, quantized 텐서에 몇 개의 고유한 색상이 렌더링될까요?
Your Answer:
n-비트 k-means quantization이 수행되면, quantized 텐서에는 \((2^n)\)개의 고유한 색상이 렌더링 됩니다. 이는 n비트를 사용하여 \((2^n)\)개의 다른 상태나 조합을 나타낼 수 있으며, 이는 텐서 값이 그룹화될 수 있는 \((2^n)\)개의 고유한 클러스터에 해당합니다.
K-Means Quantization on Whole Model
lab 1에서 했던 것과 유사하게, 이제 전체 모델을 quantizing하기 위해 k-means quantization 함수를 클래스로 래핑합니다. KMeansQuantizer 클래스에서는 모델 가중치가 변경될 때마다 codebooks(i.e., centroids와 labels)을 적용하거나 업데이트할 수 있도록 codebooks의 변화를 기록해야 합니다.
from torch.nn import parameterclass KMeansQuantizer:def__init__(self, model : nn.Module, bitwidth=4):self.codebook = KMeansQuantizer.quantize(model, bitwidth)@torch.no_grad()defapply(self, model, update_centroids):for name, param in model.named_parameters():if name inself.codebook:if update_centroids: update_codebook(param, codebook=self.codebook[name])self.codebook[name] = k_means_quantize( param, codebook=self.codebook[name])@staticmethod@torch.no_grad()def quantize(model: nn.Module, bitwidth=4): codebook =dict()ifisinstance(bitwidth, dict):for name, param in model.named_parameters():if name in bitwidth: codebook[name] = k_means_quantize(param, bitwidth=bitwidth[name])else:for name, param in model.named_parameters():if param.dim() >1: codebook[name] = k_means_quantize(param, bitwidth=bitwidth)return codebook
이제 K-Means Quantization을 사용하여 모델을 8비트, 4비트, 2비트로 quantize해봅시다. 모델 크기를 계산할 때 codebooks의 저장 공간은 무시한다는 점을 유의하세요.
print('Note that the storage for codebooks is ignored when calculating the model size.')quantizers =dict()for bitwidth in [8, 4, 2]: recover_model()print(f'k-means quantizing model into {bitwidth} bits') quantizer = KMeansQuantizer(model, bitwidth) quantized_model_size = get_model_size(model, bitwidth)print(f" {bitwidth}-bit k-means quantized model has size={quantized_model_size/MiB:.2f} MiB") quantized_model_accuracy = evaluate(model, dataloader['test'])print(f" {bitwidth}-bit k-means quantized model has accuracy={quantized_model_accuracy:.2f}%") quantizers[bitwidth] = quantizer
Note that the storage for codebooks is ignored when calculating the model size.
k-means quantizing model into 8 bits
8-bit k-means quantized model has size=8.80 MiB
8-bit k-means quantized model has accuracy=92.76%
k-means quantizing model into 4 bits
4-bit k-means quantized model has size=4.40 MiB
4-bit k-means quantized model has accuracy=79.07%
k-means quantizing model into 2 bits
2-bit k-means quantized model has size=2.20 MiB
2-bit k-means quantized model has accuracy=10.00%
Trained K-Means Quantization
마지막 셀의 결과에서 볼 수 있듯이, 모델을 적은 비트로 quantize할 때 정확도가 크게 떨어집니다. 따라서, 정확도를 회복하기 위해 quantization-aware training을 해야 합니다.
위의 centroids를 업데이트하는 방정식은 실제로 동일한 클러스터에 있는 가중치의 평균(mean)을 업데이트된 centroid 값으로 사용하고 있습니다.
def update_codebook(fp32_tensor: torch.Tensor, codebook: Codebook):""" update the centroids in the codebook using updated fp32_tensor :param fp32_tensor: [torch.(cuda.)Tensor] :param codebook: [Codebook] (the cluster centroids, the cluster label tensor) """ n_clusters = codebook.centroids.numel() fp32_tensor = fp32_tensor.view(-1)for k inrange(n_clusters):############### YOUR CODE STARTS HERE ############### codebook.centroids[k] = fp32_tensor[codebook.labels == k].mean()############### YOUR CODE ENDS HERE #################
이제 다음 코드 셀을 실행하여 k-means quantized 모델을 finetuning하여 정확도를 회복해봅시다. 정확도 하락이 0.5보다 작으면 finetuning을 중단합니다.
accuracy_drop_threshold =0.5quantizers_before_finetune = copy.deepcopy(quantizers)quantizers_after_finetune = quantizersfor bitwidth in [8, 4, 2]: recover_model() quantizer = quantizers[bitwidth]print(f'k-means quantizing model into {bitwidth} bits') quantizer.apply(model, update_centroids=False) quantized_model_size = get_model_size(model, bitwidth)print(f" {bitwidth}-bit k-means quantized model has size={quantized_model_size/MiB:.2f} MiB") quantized_model_accuracy = evaluate(model, dataloader['test'])print(f" {bitwidth}-bit k-means quantized model has accuracy={quantized_model_accuracy:.2f}% before quantization-aware training ") accuracy_drop = fp32_model_accuracy - quantized_model_accuracyif accuracy_drop > accuracy_drop_threshold:print(f" Quantization-aware training due to accuracy drop={accuracy_drop:.2f}% is larger than threshold={accuracy_drop_threshold:.2f}%") num_finetune_epochs =5 optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9) scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, num_finetune_epochs) criterion = nn.CrossEntropyLoss() best_accuracy =0 epoch = num_finetune_epochswhile accuracy_drop > accuracy_drop_threshold and epoch >0: train(model, dataloader['train'], criterion, optimizer, scheduler, callbacks=[lambda: quantizer.apply(model, update_centroids=True)]) model_accuracy = evaluate(model, dataloader['test']) is_best = model_accuracy > best_accuracy best_accuracy =max(model_accuracy, best_accuracy)print(f' Epoch {num_finetune_epochs-epoch} Accuracy {model_accuracy:.2f}% / Best Accuracy: {best_accuracy:.2f}%') accuracy_drop = fp32_model_accuracy - best_accuracy epoch -=1else:print(f" No need for quantization-aware training since accuracy drop={accuracy_drop:.2f}% is smaller than threshold={accuracy_drop_threshold:.2f}%")
k-means quantizing model into 8 bits
8-bit k-means quantized model has size=8.80 MiB
8-bit k-means quantized model has accuracy=92.76% before quantization-aware training
No need for quantization-aware training since accuracy drop=0.19% is smaller than threshold=0.50%
k-means quantizing model into 4 bits
4-bit k-means quantized model has size=4.40 MiB
4-bit k-means quantized model has accuracy=79.07% before quantization-aware training
Quantization-aware training due to accuracy drop=13.88% is larger than threshold=0.50%
Epoch 0 Accuracy 92.47% / Best Accuracy: 92.47%
k-means quantizing model into 2 bits
2-bit k-means quantized model has size=2.20 MiB
2-bit k-means quantized model has accuracy=10.00% before quantization-aware training
Quantization-aware training due to accuracy drop=82.95% is larger than threshold=0.50%
Epoch 0 Accuracy 90.21% / Best Accuracy: 90.21%
Epoch 1 Accuracy 90.82% / Best Accuracy: 90.82%
Epoch 2 Accuracy 91.00% / Best Accuracy: 91.00%
Epoch 3 Accuracy 91.12% / Best Accuracy: 91.12%
Epoch 4 Accuracy 91.17% / Best Accuracy: 91.17%
Linear Quantization
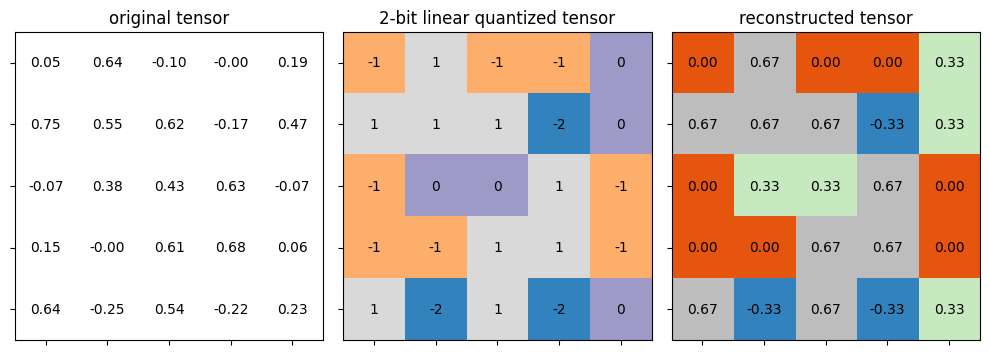
이 섹션에서는 linear quantization을 구현하고 수행합니다.
Linear quantization은 range truncation 과 scaling 과정을 거친 후 부동 소수점 값을 가장 가까운 양자화된 정수로 직접 반올림합니다.
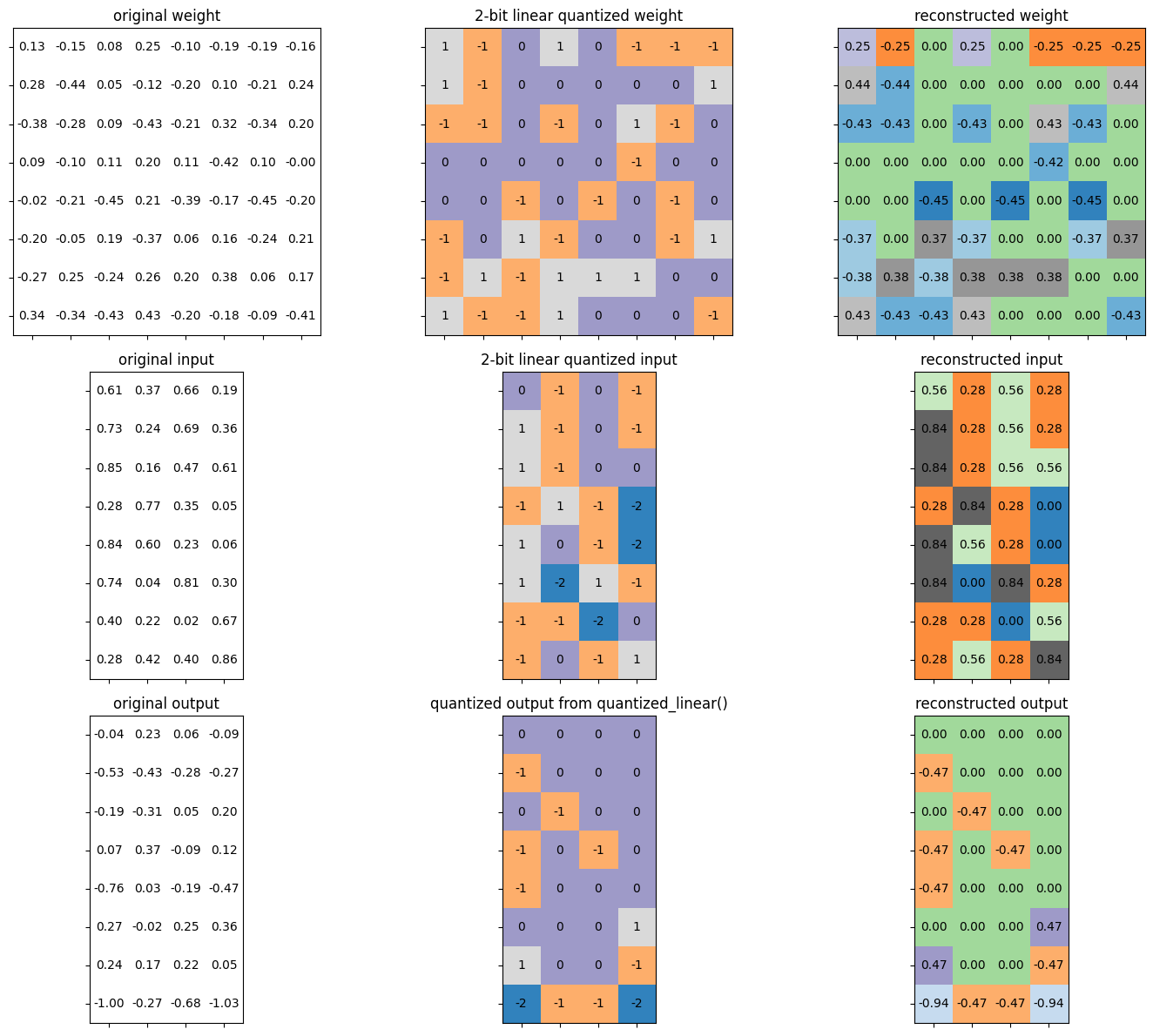
def linear_quantize(fp_tensor, bitwidth, scale, zero_point, dtype=torch.int8) -> torch.Tensor:""" linear quantization for single fp_tensor from fp_tensor = (quantized_tensor - zero_point) * scale we have, quantized_tensor = int(round(fp_tensor / scale)) + zero_point :param tensor: [torch.(cuda.)FloatTensor] floating tensor to be quantized :param bitwidth: [int] quantization bit width :param scale: [torch.(cuda.)FloatTensor] scaling factor :param zero_point: [torch.(cuda.)IntTensor] the desired centroid of tensor values :return: [torch.(cuda.)FloatTensor] quantized tensor whose values are integers """assert(fp_tensor.dtype == torch.float)assert(isinstance(scale, float) or (scale.dtype == torch.floatand scale.dim() == fp_tensor.dim()))assert(isinstance(zero_point, int) or (zero_point.dtype == dtype and zero_point.dim() == fp_tensor.dim()))############### YOUR CODE STARTS HERE ################ Step 1: scale the fp_tensor scaled_tensor = fp_tensor / scale# Step 2: round the floating value to integer value rounded_tensor = torch.round(scaled_tensor)############### YOUR CODE ENDS HERE ################# rounded_tensor = rounded_tensor.to(dtype)############### YOUR CODE STARTS HERE ################ Step 3: shift the rounded_tensor to make zero_point 0 shifted_tensor = rounded_tensor + zero_point############### YOUR CODE ENDS HERE ################## Step 4: clamp the shifted_tensor to lie in bitwidth-bit range quantized_min, quantized_max = get_quantized_range(bitwidth) quantized_tensor = shifted_tensor.clamp_(quantized_min, quantized_max)return quantized_tensor
위에서 작성한 linear quantization 기능을 더미 텐서에 적용하여 기능을 검증해봅시다.
test_linear_quantize()
* Test linear_quantize()
target bitwidth: 2 bits
scale: 0.3333333333333333
zero point: -1
* Test passed.
Question 5 (10 pts)
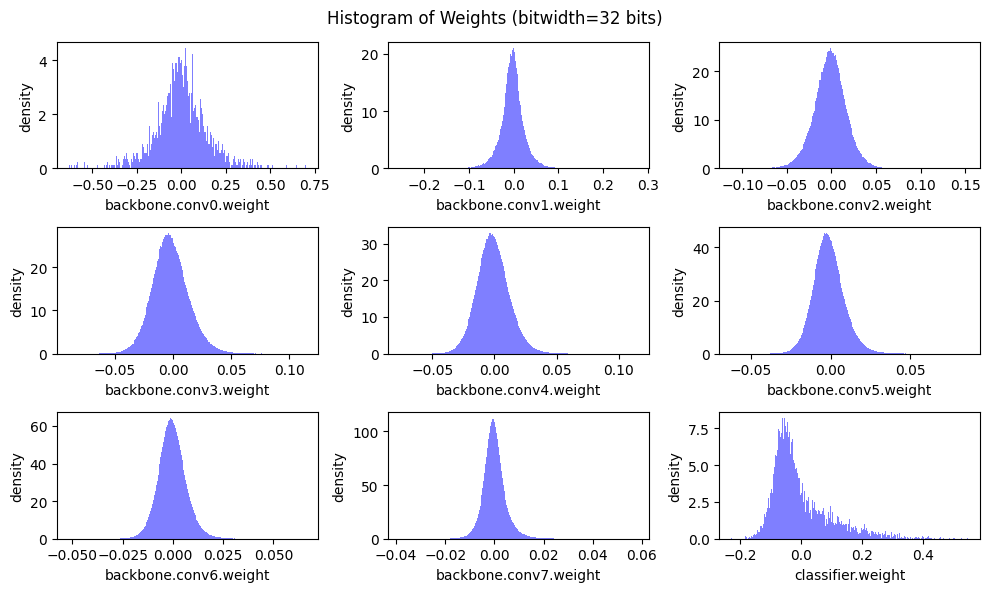
이제 linear quantization을 위한 스케일링 인자 \(S\)와 제로 포인트 \(Z\)를 결정해야 합니다.
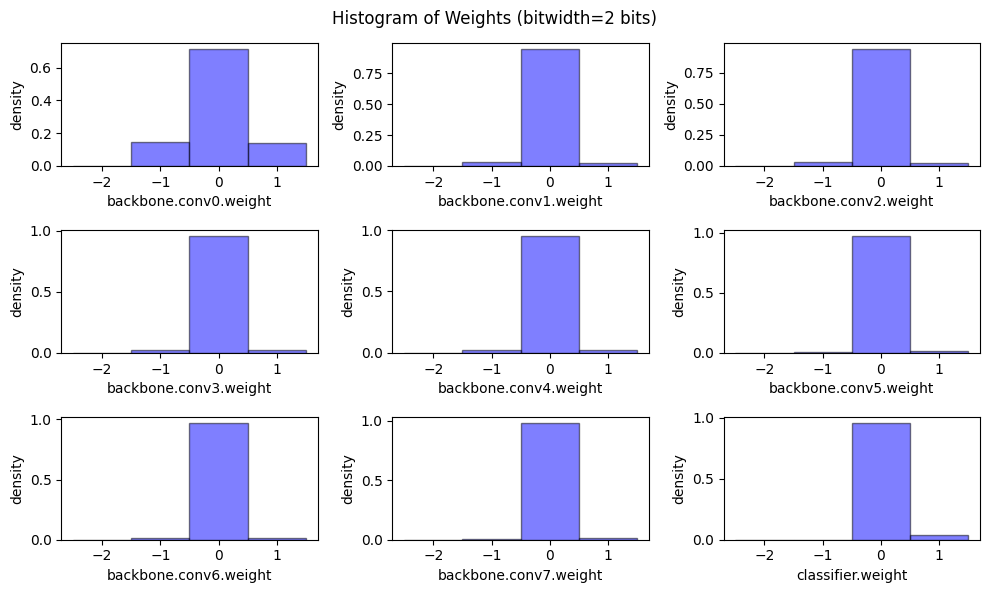
위의 히스토그램에서 볼 수 있듯이, 가중치 값의 분포는 (이 경우에는 classifier를 제외하고) 거의 0을 중심으로 대칭적입니다 . 따라서 가중치를 양자화할 때 보통 제로 포인트 \(Z=0\)으로 설정합니다.
\(r = S(q-Z)\)에서,
\(r_{\mathrm{max}} = S \cdot q_{\mathrm{max}}\)
\(S = r_{\mathrm{max}} / q_{\mathrm{max}}\)
가중치 값의 최대 절댓값을 \(r_{\mathrm{max}}\)로 이용합니다.
def get_quantization_scale_for_weight(weight, bitwidth):""" get quantization scale for single tensor of weight :param weight: [torch.(cuda.)Tensor] floating weight to be quantized :param bitwidth: [integer] quantization bit width :return: [floating scalar] scale """# we just assume values in weight are symmetric# we also always make zero_point 0 for weight fp_max =max(weight.abs().max().item(), 5e-7) _, quantized_max = get_quantized_range(bitwidth)return fp_max / quantized_max
Per-channel Linear Quantization
2D convolution의 경우, 가중치 텐서는 (num_output_channels, num_input_channels, kernel_height, kernel_width) 모양의 4차원 텐서입니다.
많은 실험들을 통해, 서로 다른 출력 채널에 대해 서로 다른 스케일링 인자 \(S\)와 제로 포인트 \(Z\)를 사용하는 것이 더 나은 성능을 발휘한다는 것을 알 수 있었습니다. 따라서 각 출력 채널의 서브텐서에 대한 스케일링 인자 \(S\)와 제로 포인트 \(Z\)를 독립적으로 정해야 합니다.
def linear_quantize_weight_per_channel(tensor, bitwidth):""" linear quantization for weight tensor using different scales and zero_points for different output channels :param tensor: [torch.(cuda.)Tensor] floating weight to be quantized :param bitwidth: [int] quantization bit width :return: [torch.(cuda.)Tensor] quantized tensor [torch.(cuda.)Tensor] scale tensor [int] zero point (which is always 0) """ dim_output_channels =0 num_output_channels = tensor.shape[dim_output_channels] scale = torch.zeros(num_output_channels, device=tensor.device)for oc inrange(num_output_channels): _subtensor = tensor.select(dim_output_channels, oc) _scale = get_quantization_scale_for_weight(_subtensor, bitwidth) scale[oc] = _scale scale_shape = [1] * tensor.dim() scale_shape[dim_output_channels] =-1 scale = scale.view(scale_shape) quantized_tensor = linear_quantize(tensor, bitwidth, scale, zero_point=0)return quantized_tensor, scale, 0
A Quick Peek at Linear Quantization on Weights
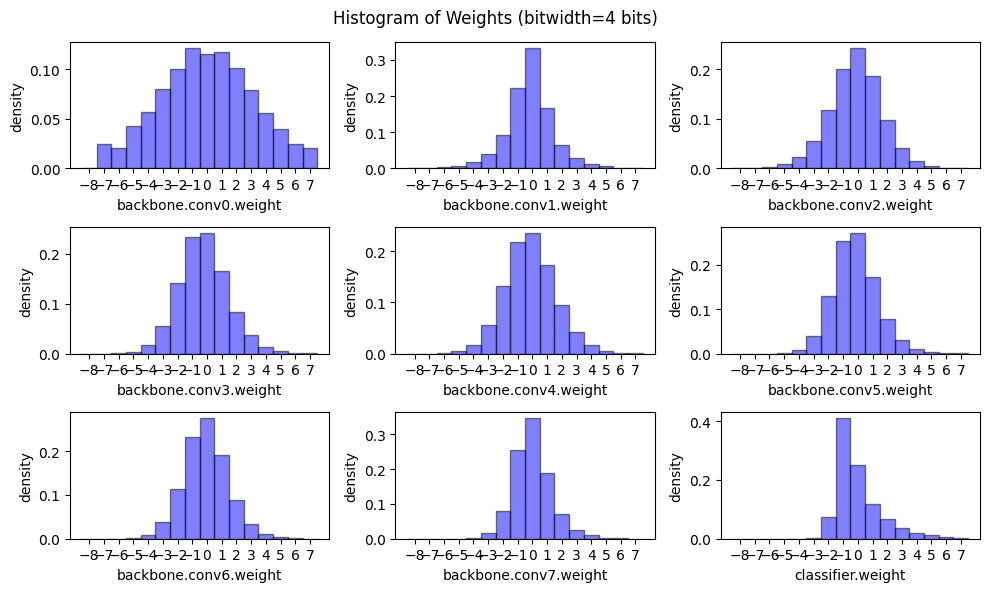
이제 가중치에 대해 linear quantization를 적용할 때 가중치 분포와 모델 크기를 서로 다른 bitwidths로 살펴보겠습니다.
def quantized_linear(input, weight, bias, feature_bitwidth, weight_bitwidth, input_zero_point, output_zero_point, input_scale, weight_scale, output_scale):""" quantized fully-connected layer :param input: [torch.CharTensor] quantized input (torch.int8) :param weight: [torch.CharTensor] quantized weight (torch.int8) :param bias: [torch.IntTensor] shifted quantized bias or None (torch.int32) :param feature_bitwidth: [int] quantization bit width of input and output :param weight_bitwidth: [int] quantization bit width of weight :param input_zero_point: [int] input zero point :param output_zero_point: [int] output zero point :param input_scale: [float] input feature scale :param weight_scale: [torch.FloatTensor] weight per-channel scale :param output_scale: [float] output feature scale :return: [torch.CharIntTensor] quantized output feature (torch.int8) """assert(input.dtype == torch.int8)assert(weight.dtype ==input.dtype)assert(bias isNoneor bias.dtype == torch.int32)assert(isinstance(input_zero_point, int))assert(isinstance(output_zero_point, int))assert(isinstance(input_scale, float))assert(isinstance(output_scale, float))assert(weight_scale.dtype == torch.float)# Step 1: integer-based fully-connected (8-bit multiplication with 32-bit accumulation)if'cpu'ininput.device.type:# use 32-b MAC for simplicity output = torch.nn.functional.linear(input.to(torch.int32), weight.to(torch.int32), bias)else:# current version pytorch does not yet support integer-based linear() on GPUs output = torch.nn.functional.linear(input.float(), weight.float(), bias.float())############### YOUR CODE STARTS HERE ################ Step 2: scale the output# hint: 1. scales are floating numbers, we need to convert output to float as well# 2. the shape of weight scale is [oc, 1, 1, 1] while the shape of output is [batch_size, oc] real_scale = input_scale * weight_scale.view(-1) / output_scale output = output.float() * real_scale# Step 3: Shift output by output_zero_point output += output_zero_point############### YOUR CODE STARTS HERE ################ Make sure all value lies in the bitwidth-bit range output = output.round().clamp(*get_quantized_range(feature_bitwidth)).to(torch.int8)return output
Let’s verify the functionality of defined quantized fully connected layer.
test_quantized_fc()
* Test quantized_fc()
target bitwidth: 2 bits
batch size: 4
input channels: 8
output channels: 8
* Test passed.
Quantized Convolution
양자화된 컨볼루션 레이어의 경우, 먼저 \(Q_{\mathrm{bias}}\)를 계산합니다. \(Q_{\mathrm{bias}} = q_{\mathrm{bias}} - \mathrm{CONV}[Z_{\mathrm{input}}, q_{\mathrm{weight}}]\)를 기억하세요.
def quantized_conv2d(input, weight, bias, feature_bitwidth, weight_bitwidth, input_zero_point, output_zero_point, input_scale, weight_scale, output_scale, stride, padding, dilation, groups):""" quantized 2d convolution :param input: [torch.CharTensor] quantized input (torch.int8) :param weight: [torch.CharTensor] quantized weight (torch.int8) :param bias: [torch.IntTensor] shifted quantized bias or None (torch.int32) :param feature_bitwidth: [int] quantization bit width of input and output :param weight_bitwidth: [int] quantization bit width of weight :param input_zero_point: [int] input zero point :param output_zero_point: [int] output zero point :param input_scale: [float] input feature scale :param weight_scale: [torch.FloatTensor] weight per-channel scale :param output_scale: [float] output feature scale :return: [torch.(cuda.)CharTensor] quantized output feature """assert(len(padding) ==4)assert(input.dtype == torch.int8)assert(weight.dtype ==input.dtype)assert(bias isNoneor bias.dtype == torch.int32)assert(isinstance(input_zero_point, int))assert(isinstance(output_zero_point, int))assert(isinstance(input_scale, float))assert(isinstance(output_scale, float))assert(weight_scale.dtype == torch.float)# Step 1: calculate integer-based 2d convolution (8-bit multiplication with 32-bit accumulation)input= torch.nn.functional.pad(input, padding, 'constant', input_zero_point)if'cpu'ininput.device.type:# use 32-b MAC for simplicity output = torch.nn.functional.conv2d(input.to(torch.int32), weight.to(torch.int32), None, stride, 0, dilation, groups)else:# current version pytorch does not yet support integer-based conv2d() on GPUs output = torch.nn.functional.conv2d(input.float(), weight.float(), None, stride, 0, dilation, groups) output = output.round().to(torch.int32)if bias isnotNone: output = output + bias.view(1, -1, 1, 1)############### YOUR CODE STARTS HERE ################ hint: this code block should be the very similar to quantized_linear()# Step 2: scale the output# hint: 1. scales are floating numbers, we need to convert output to float as well# 2. the shape of weight scale is [oc, 1, 1, 1] while the shape of output is [batch_size, oc, height, width] real_scale = input_scale * weight_scale.view(-1) / output_scale output = output.float() * real_scale.unsqueeze(1).unsqueeze(2)# Step 3: shift output by output_zero_point# hint: one line of code output += output_zero_point############### YOUR CODE STARTS HERE ################ Make sure all value lies in the bitwidth-bit range output = output.round().clamp(*get_quantized_range(feature_bitwidth)).to(torch.int8)return output
Question 9 (10 pts)
마지막으로 모든 것을 종합하여 모델에 대한 훈련 후 int8 양자화를 수행합니다. 모델의 컨볼루션 레이어와 선형 레이어를 하나씩 양자화된 버전으로 변환합니다.
먼저, BatchNorm 계층을 이전 convolutional layer에 융합할 것이며, 이는 양자화 전에 하는 표준 관행입니다. BatchNorm을 융합하면 추론 중에 추가 곱셈이 줄어듭니다.
융합 모델인 model_fused가 원래 모델과 동일한 정확도를 갖는지도 검증할 예정입니다(BN fusion은 네트워크 기능을 변경하지 않는 동등한 변환입니다).
def fuse_conv_bn(conv, bn):# modified from https://mmcv.readthedocs.io/en/latest/_modules/mmcv/cnn/utils/fuse_conv_bn.htmlassert conv.bias isNone factor = bn.weight.data / torch.sqrt(bn.running_var.data + bn.eps) conv.weight.data = conv.weight.data * factor.reshape(-1, 1, 1, 1) conv.bias = nn.Parameter(- bn.running_mean.data * factor + bn.bias.data)return convprint('Before conv-bn fusion: backbone length', len(model.backbone))# fuse the batchnorm into conv layersrecover_model()model_fused = copy.deepcopy(model)fused_backbone = []ptr =0while ptr <len(model_fused.backbone):ifisinstance(model_fused.backbone[ptr], nn.Conv2d) and\isinstance(model_fused.backbone[ptr +1], nn.BatchNorm2d): fused_backbone.append(fuse_conv_bn( model_fused.backbone[ptr], model_fused.backbone[ptr+1])) ptr +=2else: fused_backbone.append(model_fused.backbone[ptr]) ptr +=1model_fused.backbone = nn.Sequential(*fused_backbone)print('After conv-bn fusion: backbone length', len(model_fused.backbone))# sanity check, no BN anymorefor m in model_fused.modules():assertnotisinstance(m, nn.BatchNorm2d)# the accuracy will remain the same after fusionfused_acc = evaluate(model_fused, dataloader['test'])print(f'Accuracy of the fused model={fused_acc:.2f}%')
Before conv-bn fusion: backbone length 29
After conv-bn fusion: backbone length 21
Accuracy of the fused model=92.95%
각 특징 맵의 범위를 얻기 위해 일부 샘플 데이터로 모델을 실행하여 특징 맵의 범위를 얻고, 해당 스케일링 팩터와 제로 포인트를 계산할 수 있습니다.
# add hook to record the min max value of the activationinput_activation = {}output_activation = {}def add_range_recoder_hook(model):import functoolsdef _record_range(self, x, y, module_name): x = x[0] input_activation[module_name] = x.detach() output_activation[module_name] = y.detach() all_hooks = []for name, m in model.named_modules():ifisinstance(m, (nn.Conv2d, nn.Linear, nn.ReLU)): all_hooks.append(m.register_forward_hook( functools.partial(_record_range, module_name=name)))return all_hookshooks = add_range_recoder_hook(model_fused)sample_data =iter(dataloader['train']).__next__()[0]model_fused(sample_data.cuda())# remove hooksfor h in hooks: h.remove()
마지막으로 모델 양자화를 해보겠습니다. 다음과 같은 매핑으로 모델을 변환합니다.
nn.Conv2d: QuantizedConv2d,nn.Linear: QuantizedLinear,# the following twos are just wrappers, as current# torch modules do not support int8 data format;# we will temporarily convert them to fp32 for computationnn.MaxPool2d: QuantizedMaxPool2d,nn.AvgPool2d: QuantizedAvgPool2d,
class QuantizedConv2d(nn.Module):def__init__(self, weight, bias, input_zero_point, output_zero_point, input_scale, weight_scale, output_scale, stride, padding, dilation, groups, feature_bitwidth=8, weight_bitwidth=8):super().__init__()# current version Pytorch does not support IntTensor as nn.Parameterself.register_buffer('weight', weight)self.register_buffer('bias', bias)self.input_zero_point = input_zero_pointself.output_zero_point = output_zero_pointself.input_scale = input_scaleself.register_buffer('weight_scale', weight_scale)self.output_scale = output_scaleself.stride = strideself.padding = (padding[1], padding[1], padding[0], padding[0])self.dilation = dilationself.groups = groupsself.feature_bitwidth = feature_bitwidthself.weight_bitwidth = weight_bitwidthdef forward(self, x):return quantized_conv2d( x, self.weight, self.bias,self.feature_bitwidth, self.weight_bitwidth,self.input_zero_point, self.output_zero_point,self.input_scale, self.weight_scale, self.output_scale,self.stride, self.padding, self.dilation, self.groups )class QuantizedLinear(nn.Module):def__init__(self, weight, bias, input_zero_point, output_zero_point, input_scale, weight_scale, output_scale, feature_bitwidth=8, weight_bitwidth=8):super().__init__()# current version Pytorch does not support IntTensor as nn.Parameterself.register_buffer('weight', weight)self.register_buffer('bias', bias)self.input_zero_point = input_zero_pointself.output_zero_point = output_zero_pointself.input_scale = input_scaleself.register_buffer('weight_scale', weight_scale)self.output_scale = output_scaleself.feature_bitwidth = feature_bitwidthself.weight_bitwidth = weight_bitwidthdef forward(self, x):return quantized_linear( x, self.weight, self.bias,self.feature_bitwidth, self.weight_bitwidth,self.input_zero_point, self.output_zero_point,self.input_scale, self.weight_scale, self.output_scale )class QuantizedMaxPool2d(nn.MaxPool2d):def forward(self, x):# current version PyTorch does not support integer-based MaxPoolreturnsuper().forward(x.float()).to(torch.int8)class QuantizedAvgPool2d(nn.AvgPool2d):def forward(self, x):# current version PyTorch does not support integer-based AvgPoolreturnsuper().forward(x.float()).to(torch.int8)# we use int8 quantization, which is quite popularfeature_bitwidth = weight_bitwidth =8quantized_model = copy.deepcopy(model_fused)quantized_backbone = []ptr =0while ptr <len(quantized_model.backbone):ifisinstance(quantized_model.backbone[ptr], nn.Conv2d) and\isinstance(quantized_model.backbone[ptr +1], nn.ReLU): conv = quantized_model.backbone[ptr] conv_name =f'backbone.{ptr}' relu = quantized_model.backbone[ptr +1] relu_name =f'backbone.{ptr +1}' input_scale, input_zero_point =\ get_quantization_scale_and_zero_point( input_activation[conv_name], feature_bitwidth) output_scale, output_zero_point =\ get_quantization_scale_and_zero_point( output_activation[relu_name], feature_bitwidth) quantized_weight, weight_scale, weight_zero_point =\ linear_quantize_weight_per_channel(conv.weight.data, weight_bitwidth) quantized_bias, bias_scale, bias_zero_point =\ linear_quantize_bias_per_output_channel( conv.bias.data, weight_scale, input_scale) shifted_quantized_bias =\ shift_quantized_conv2d_bias(quantized_bias, quantized_weight, input_zero_point) quantized_conv = QuantizedConv2d( quantized_weight, shifted_quantized_bias, input_zero_point, output_zero_point, input_scale, weight_scale, output_scale, conv.stride, conv.padding, conv.dilation, conv.groups, feature_bitwidth=feature_bitwidth, weight_bitwidth=weight_bitwidth ) quantized_backbone.append(quantized_conv) ptr +=2elifisinstance(quantized_model.backbone[ptr], nn.MaxPool2d): quantized_backbone.append(QuantizedMaxPool2d( kernel_size=quantized_model.backbone[ptr].kernel_size, stride=quantized_model.backbone[ptr].stride )) ptr +=1elifisinstance(quantized_model.backbone[ptr], nn.AvgPool2d): quantized_backbone.append(QuantizedAvgPool2d( kernel_size=quantized_model.backbone[ptr].kernel_size, stride=quantized_model.backbone[ptr].stride )) ptr +=1else:raiseNotImplementedError(type(quantized_model.backbone[ptr])) # should not happenquantized_model.backbone = nn.Sequential(*quantized_backbone)# finally, quantized the classifierfc_name ='classifier'fc = model.classifierinput_scale, input_zero_point =\ get_quantization_scale_and_zero_point( input_activation[fc_name], feature_bitwidth)output_scale, output_zero_point =\ get_quantization_scale_and_zero_point( output_activation[fc_name], feature_bitwidth)quantized_weight, weight_scale, weight_zero_point =\ linear_quantize_weight_per_channel(fc.weight.data, weight_bitwidth)quantized_bias, bias_scale, bias_zero_point =\ linear_quantize_bias_per_output_channel( fc.bias.data, weight_scale, input_scale)shifted_quantized_bias =\ shift_quantized_linear_bias(quantized_bias, quantized_weight, input_zero_point)quantized_model.classifier = QuantizedLinear( quantized_weight, shifted_quantized_bias, input_zero_point, output_zero_point, input_scale, weight_scale, output_scale, feature_bitwidth=feature_bitwidth, weight_bitwidth=weight_bitwidth)
양자화 과정이 완료되었습니다! 모델 아키텍처를 인쇄하고 시각화하며 양자화된 모델의 정확성도 검증해 보겠습니다.
Question 9.1 (5 pts)
양자화된 모델을 실행하기 위해서는 (0, 1) 범위의 입력 데이터를 (-128, 127) 범위의 int8 범위로 매핑하는 추가적인 전처리가 필요합니다. 이 전처리를 진행하는 아래 코드를 완성하세요.
Hint: 양자화된 모델은 fp32 모델과 거의 동일한 정확도를 가지고 있습니다.
print(quantized_model)def extra_preprocess(x):# hint: you need to convert the original fp32 input of range (0, 1)# into int8 format of range (-128, 127)############### YOUR CODE STARTS HERE ############### x_scaled = x *255 x_shifted = x_scaled -128return x_shifted.clamp(-128, 127).to(torch.int8)############### YOUR CODE ENDS HERE #################int8_model_accuracy = evaluate(quantized_model, dataloader['test'], extra_preprocess=[extra_preprocess])print(f"int8 model has accuracy={int8_model_accuracy:.2f}%")
선형(Linear) 양자화 모델에서 ReLU(Rectified Linear Unit) 층이 없는 이유는 주로 양자화 과정에서의 데이터 표현 방식과 연산의 효율성과 관련이 있습니다. 양자화는 모델의 가중치나 활성화를 고정된 비트 너비(예: 8비트)의 정수로 제한하여 저장하고 계산하는 기술입니다. 이러한 제한은 모델의 크기를 줄이고, 계산 속도를 향상시키며, 저전력 장치에서의 실행을 용이하게 합니다. 그러나 이 과정에서 데이터의 정밀도가 손실될 수 있으며, 이는 모델 성능에 영향을 미칠 수 있습니다.
ReLU 활성화 함수는 입력이 양수일 경우 그대로 출력하고, 음수일 경우 0으로 만드는 간단하고 효율적인 비선형 함수입니다. ReLU는 딥러닝 모델에서 널리 사용되며, 특히 은닉층에서 비선형성을 추가하여 모델의 표현력을 향상시키는 데 중요한 역할을 합니다.
선형 양자화 모델에서 ReLU 층이 없는 주된 이유는 다음과 같습니다:
양자화된 데이터의 범위 제한: 정수 양자화 과정에서는 데이터가 특정 범위 내의 값으로 제한됩니다. 예를 들어, 8비트 양자화에서는 값이 -128부터 127까지의 정수 범위를 가집니다. 이러한 범위 내에서 ReLU를 적용하면 음수 값이 모두 0으로 변환되어, 양수 값만 남게 됩니다. 이 과정에서 데이터의 범위가 더욱 제한되어, 양자화된 모델의 표현력이 더욱 감소할 수 있습니다.
효율성: 양자화된 모델은 가능한 한 계산을 간단하게 유지하여 빠른 추론 속도와 낮은 전력 소모를 달성하려고 합니다. ReLU와 같은 비선형 함수를 추가하면, 추론 과정에서 추가적인 계산이 필요하게 됩니다. 어떤 경우에는 모델의 구조나 목적에 따라 이러한 추가 계산 없이도 충분한 성능을 달성할 수 있으므로, ReLU 층을 생략할 수 있습니다.
모델 설계와 목적: 특정 양자화 모델에서는 성능 유지를 위해 ReLU 대신 다른 기법이나 활성화 함수를 사용할 수 있습니다. 예를 들어, 양자화 전 모델에서 ReLU를 사용하는 대신, 양자화 과정에서 최적화된 활성화 함수를 선택하거나, ReLU의 효과를 모방할 수 있는 다른 방법을 모색할 수 있습니다.
결론적으로, 선형 양자화 모델에서 ReLU 층의 부재는 데이터의 범위 제한, 계산 효율성, 그리고 특정 모델 설계와 목적에 기인할 수 있습니다. 모델의 설계자는 성능, 속도, 크기 등의 요구 사항을 균형 있게 고려하여 최적의 모델 구조를 결정해야 합니다.
Question 10 (5 pts)
k-means 기반 양자화와 선형 양자화의 장단점을 비교해 보시기 바랍니다. 정확도, 지연 시간, 하드웨어 지원 등의 관점에서 생각해보세요.
Your Answer:
K-means 기반 양자화와 선형 양자화는 데이터의 정밀도를 줄이거나 크기를 축소하는 데 사용되는 두 가지 기술입니다. 이들 기술은 특정 응용 프로그램에 더 적합한 다양한 특성을 가지고 있습니다. 여기에서 정확도, 지연 시간 및 하드웨어 지원의 관점에서 비교해 보겠습니다:
정확도:
K-means 기반 양자화: 주어진 클러스터 수에 대해 양자화 오류를 최소화하기 때문에 일반적으로 선형 양자화보다 더 높은 정확도를 제공합니다. K-means 양자화는 비슷한 값을 함께 클러스터링하여 데이터 분포에 적응하므로, 특히 데이터가 균일하지 않은 분포를 따를 때 더 많은 정보를 보존합니다.
선형 양자화: 이 방법은 데이터 값의 전체 범위에 걸쳐 균일한 스케일을 적용합니다. 더 단순하지만, K-means만큼 데이터 분포를 효과적으로 포착하지 못할 수 있으며, 특히 데이터가 균일 분포를 따르지 않는 경우에는 양자화 오류가 더 클 수 있습니다.
지연 시간:
K-means 기반 양자화: 최적의 클러스터를 찾는 과정은 계산이 많이 필요하고 특히 큰 데이터셋이나 높은 차원에서 더 느릴 수 있습니다. 이는 K-means 양자화가 선형 양자화에 비해 양자화 과정에서 더 많은 지연 시간을 도입할 수 있음을 의미합니다.
선형 양자화: 단순성으로 인해, 선형 양자화는 K-means 기반 양자화보다 일반적으로 계산 속도가 더 빠릅니다. 이는 단순한 산술 연산만을 포함하기 때문에, 낮은 지연 시간이 중요한 시나리오에서 더 적합합니다.
하드웨어 지원:
K-means 기반 양자화: 클러스터링 알고리즘에 대한 전용 지원 없이 K-means 기반 양자화를 효율적으로 구현하는 것은 어려울 수 있습니다. 현대의 GPU와 전문 가속기(예: TPU)는 이러한 작업을 더 효율적으로 수행할 수 있지만, K-means 알고리즘의 복잡성은 여전히 낮은 전력 또는 임베디드 장치에서 사용을 제한할 수 있습니다.
선형 양자화: 그 단순함으로 인해 선형 양자화는 저전력 및 임베디드 장치를 포함한 다양한 하드웨어에서 더 쉽게 구현될 수 있습니다. 클러스터링에 관련된 복잡한 연산이 필요하지 않기 때문에, 제한된 계산 리소스를 가진 장치에서 구현하기 더 쉽습니다.
요약:
K-means 기반 양자화는 기본 데이터 분포에 더 적응할 수 있어, 계산 복잡성과 지연 시간이 증가하는 대신 더 높은 정확도를 제공할 수 있습니다. 이는 데이터의 고도의 정확성을 유지하는 것이 중요하고 계산 자원이 주요 제약 조건이 아닌 응용 프로그램에 가장 적합합니다.
선형 양자화는 단순성, 속도 및 광범위한 하드웨어 호환성의 균형을 제공하여, 복잡하거나 균일하지 않은 데이터 분포에 대해 동일한 수준의 정확도를 항상 달성할 수는 없지만 실시간 처리와 처리 능력이 제한된 장치에 적합합니다.
응용 프로그램의 특정 요구 사항에 따라 K-means 기반 양자화와 선형 양자화 사이에서 선택해야 하며, 정확성, 처리 지연 시간 및 사용 가능한 계산 리소스의 중요성을 고려해야 합니다.