🧑🏫 Lecture 12-13
이번 글에서는 현대 NLP의 핵심 도구인 transformer와 LLM, 그리고 이들을 최적화하는 여러 방법에 대해서 소개한다. transformer를 최적화 하기 위한 방법으로 positional embedding의 변화나 llama2에 사용된 grouped-query-attention등을 다룬다. 더 나아가, LLMs의 효율적인 추론(inference)와 조정(fine-tuning) 알고리즘과 시스템에 대해서도 다룬다. inference에 대해서는 vLLM, StreamingLLM, fine-tuning은 LoRA, QLoRA, Adapter기법 등을 소개한다.
1. Transformer basics
강의에서는 transformer 구조의 tokenizer, encoding, attention등에 대해 간략히 소개하고 있지만 이 글은 transformer/LLM의 최적화에 대해 다루고 있고, transformer 자체의 구조를 다루면 글이 너무 길어질 것 같아서 자세한 구조는 아래의 두 링크를 참고 부탁드립니다
https://wikidocs.net/31379
https://blogs.nvidia.co.kr/blog/what-is-a-transformer-model/
2. Transformer design variants
이번 장에서는 원본 transformer(attention is all you need) 이후에 transformer를 발전시킨 여러 기법에 대해 다룬다.
Absolute positional encoding -> Relative positional encoding
원본 transformer 모델에서는 positional embedding으로 sinusoid embedding을 사용한다. 이는 position마다 독립적이면서도 연속적인 embedding vector를 만들어낸다. 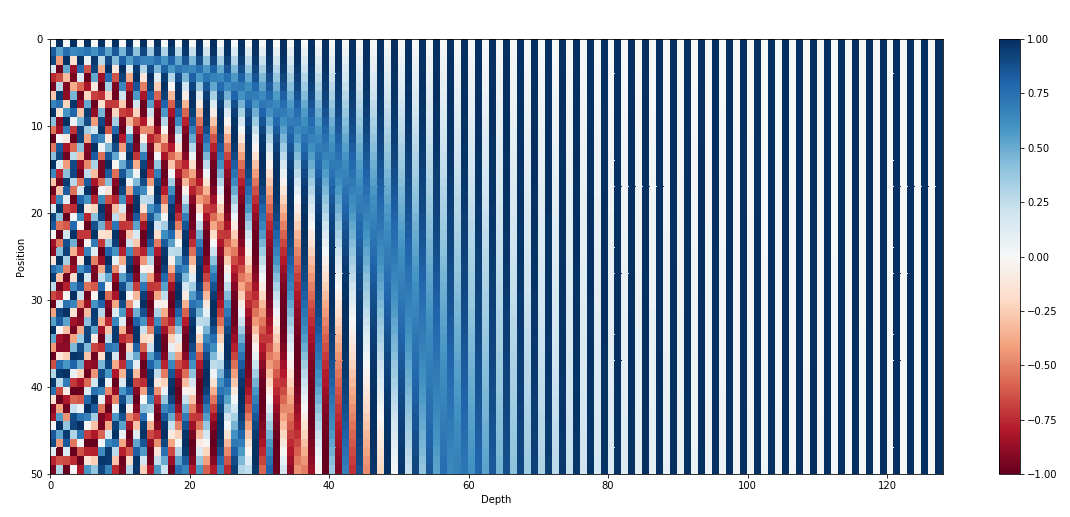
그러나 이런 index에 의존적인 absolute positional encoding 방식에는, training중에 보지 못한 길이를 대응하기 어렵다는 문제점이 있다. 예를 들어, 250 token까지만 학습했는데 251 token의 데이터가 들어오는 상황 말이다.
Relative positional encoding을 사용하면 train short, test long을 달성할 수 있다. 이외에도 absolute positional encoding은 위치 정보를 input embedding에 더해 Q/K/V 전체에 영향을 미치지만, relative positional encoding은 Q,K에 bias를 더하는 방식으로 attention score에 영향을 준다(V에는 영향을 미치지 않는다)
Attention with Linear Biases (ALiBi)
가장 간단한 방법으로는 ALiBi가 있다. 이 방법은 단순히 attention matrix에 query와 key의 거리에 대한 offset을 더해준다. 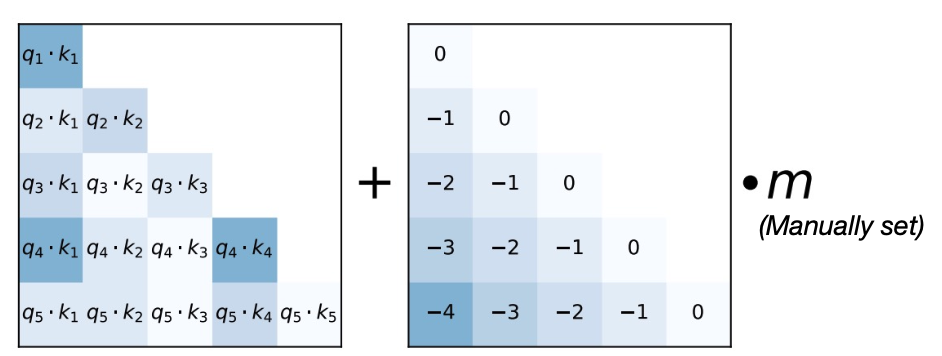
Rotary Positional Embedding (RoPE)
다른 방법으로는 llama2에도 사용될 정도로 널리 사용되고 있는 RoPE이다. RoPE의 아이디어는 입력 데이터의 위치 정보를 회전(rotation)을 통해 인코딩하는 것이다. d차원의 word embedding으로 d/2개의 짝을 만들고, 각각의 pair를 2d 좌표로 가정하고, position에 따라 회전시키는 것이다. 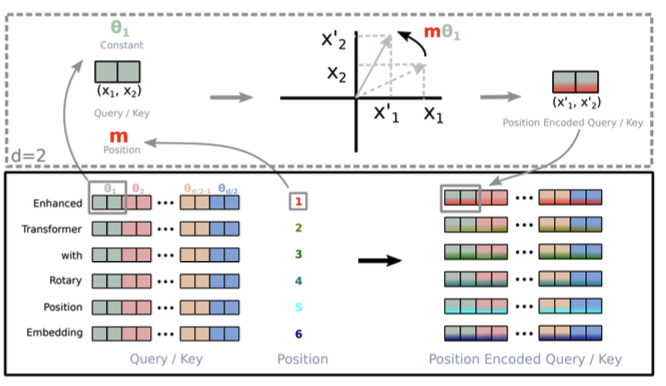 위 그림에서 x1,x2에 m * theta를 곱해서 회전시키고 있다.
위 그림에서 x1,x2에 m * theta를 곱해서 회전시키고 있다.  RoPE를 수식으로 나타내면 위와 같다
RoPE를 수식으로 나타내면 위와 같다
LLM은 보통 학습할 때 context 길이에 제한이 있다. 예를들어 llama는 2k, llama2는 4k로 제한된 데이터로 학습한다. 그러나 RoPE 방식 덕에 더 큰 context 길이도 다룰 수 있다. 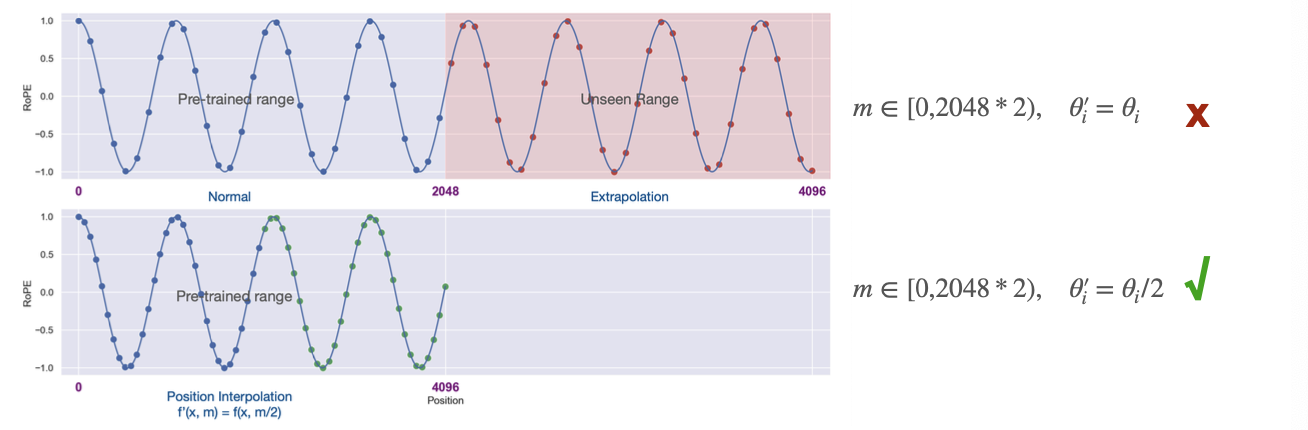 더 작은 theta를 사용하면, 더 촘촘하게 interpolate 하면서 context길이를 늘릴 수 있다. 위 그림에서 단순히 4096 context 길이는 unseen이라 실패하지만, theta를 절반으로 줄인 아래 그래프에서는 원래 context 길이 안에 들어오기 때문에 성공하는 모습을 볼 수 있다.
더 작은 theta를 사용하면, 더 촘촘하게 interpolate 하면서 context길이를 늘릴 수 있다. 위 그림에서 단순히 4096 context 길이는 unseen이라 실패하지만, theta를 절반으로 줄인 아래 그래프에서는 원래 context 길이 안에 들어오기 때문에 성공하는 모습을 볼 수 있다.
KV cache optimizations(Multi-Head Attention (MHA) -> Multi-Query Attention (MQA) -> Grouped-Query Attention(GQA)
KV cache란 attention 매커니즘의 Key, Value를 저장해놓는 것을 말한다. transfomer를 decode(gpt-style. decoder 모델 사용해 생성하는 것을 의미함)할 때는 지금 시점 토큰의 attention을 계산하기 위해 이전 토큰들의 Key, Value값을 모두 저장하고 있어야 한다. 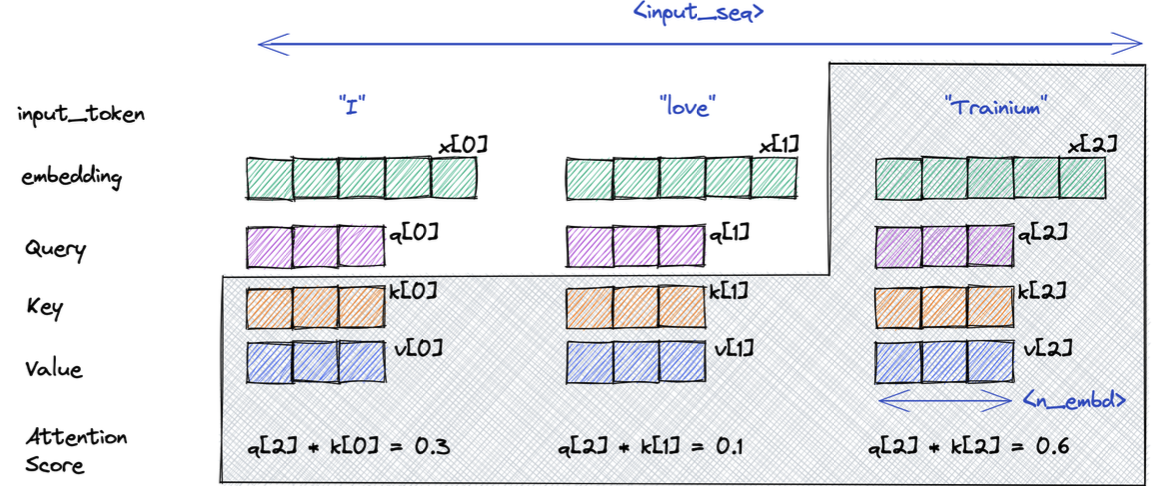 위 그림에서 “trainium” 토큰을 생성하기 위해선 이전 “I”, “love”의 K,V가 필요하다(Query는 필요하지 않음) 단순히 상상해봐도, KV cache를 저장하기 위해 사용되는 메모리가 너무 많이 필요하다. llama2-7b 모델에서 KV cache 크기는 batch_size * 32(layers) * 128(n_emd) * N(length) * 2(K,V니까 2개) * 2byte(fp16) = 512KB * BS * N 만큼 필요하다. llama2-70B 모델을 이런 식으로 계산해보면, batch size 16일 때 4096번째 token을 처리할 때 KV cache의 용량은 160GB에 달한다.
위 그림에서 “trainium” 토큰을 생성하기 위해선 이전 “I”, “love”의 K,V가 필요하다(Query는 필요하지 않음) 단순히 상상해봐도, KV cache를 저장하기 위해 사용되는 메모리가 너무 많이 필요하다. llama2-7b 모델에서 KV cache 크기는 batch_size * 32(layers) * 128(n_emd) * N(length) * 2(K,V니까 2개) * 2byte(fp16) = 512KB * BS * N 만큼 필요하다. llama2-70B 모델을 이런 식으로 계산해보면, batch size 16일 때 4096번째 token을 처리할 때 KV cache의 용량은 160GB에 달한다. 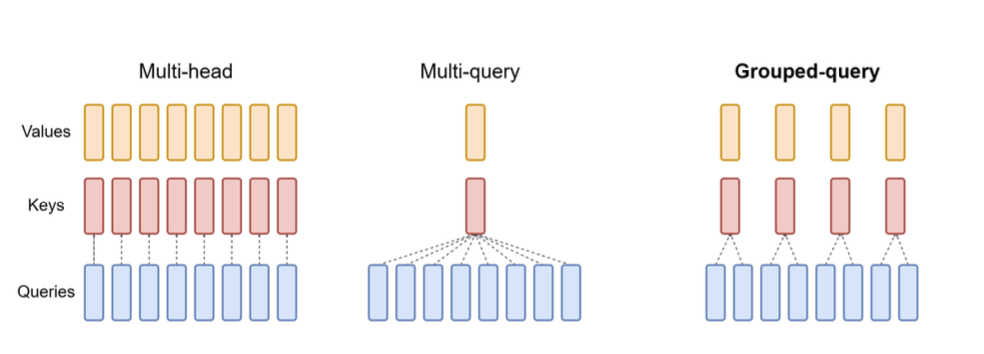 따라서 KV cache의 사이즈를 줄일 필요가 있고, 그 방법이 multi-query-attention(MQA), grouped-query-attention(GQA)이다. 이중 GQA는 llama2에도 적용될 정도로 많이 사용되는 방식이다. 각각의 방식을 살펴보면
따라서 KV cache의 사이즈를 줄일 필요가 있고, 그 방법이 multi-query-attention(MQA), grouped-query-attention(GQA)이다. 이중 GQA는 llama2에도 적용될 정도로 많이 사용되는 방식이다. 각각의 방식을 살펴보면
MQA : 모든 value와 key를 하나로 평균낸다
GQA : 모든 value와 key를 G개로 평균낸다(보통 G는 N/8)
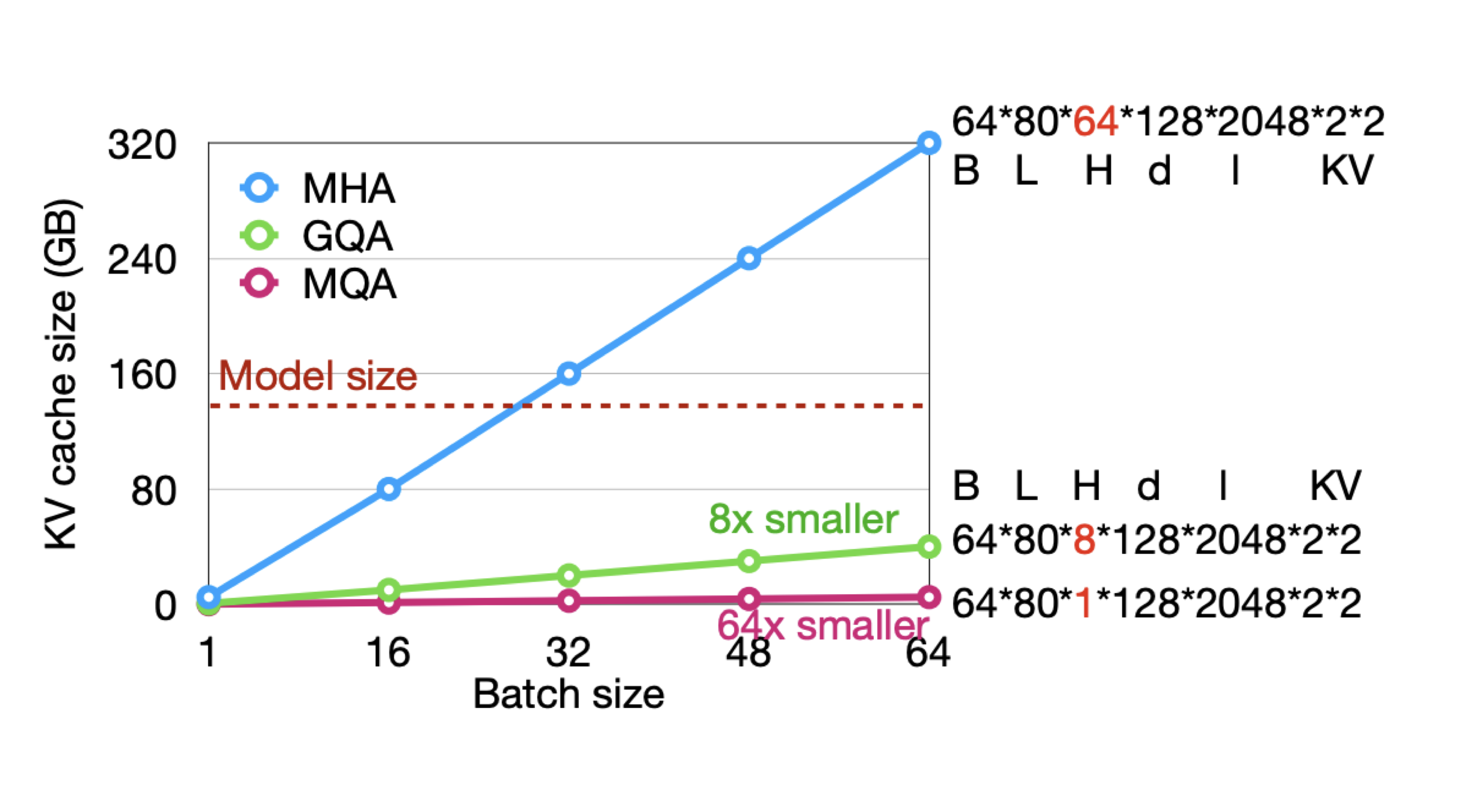 위 그림처럼 MQA, GQA를 사용하면 KV cache 크기를 많이 줄일 수 있다.
위 그림처럼 MQA, GQA를 사용하면 KV cache 크기를 많이 줄일 수 있다.
FFN->GLU
inverted bottleneck, relu를 사용하던 기존 FFN 계층을, GLU(Gated Linear Unit)과 swish 활성화 함수를 사용하면 성능이 더 나아진다고 한다. 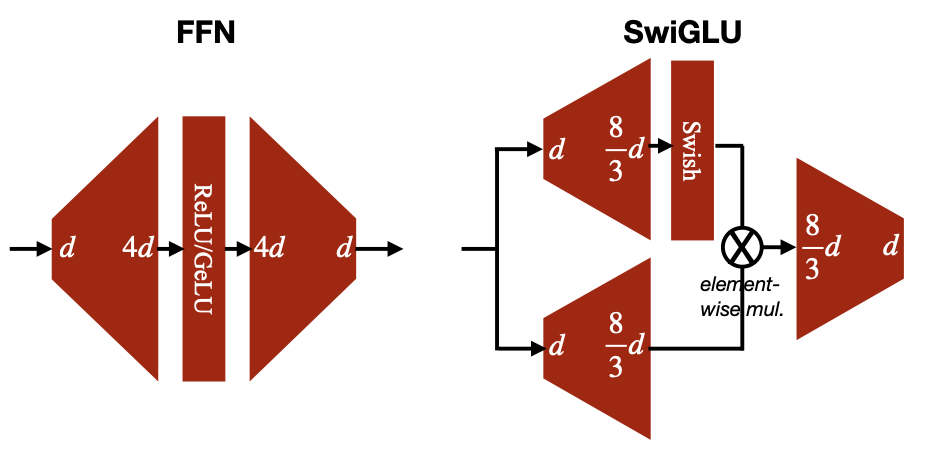
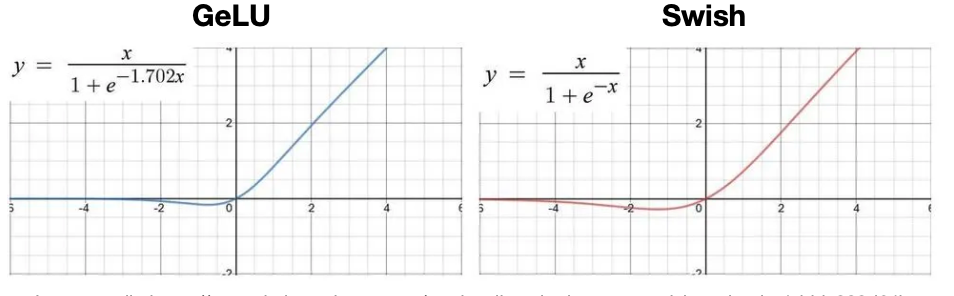 이때 성능은 PPL(perplexity)로 측정한다.
이때 성능은 PPL(perplexity)로 측정한다.
3. Large language models(LLMs)
LLM이 어떤 일을 할 수 있는지, 어떤 종류가 있는지에 대해서는 이미 많이 글과 정보가 있기 때문에, 3장에서는 LLM의 여러가지 특징에 대해 간단히 설명한다. 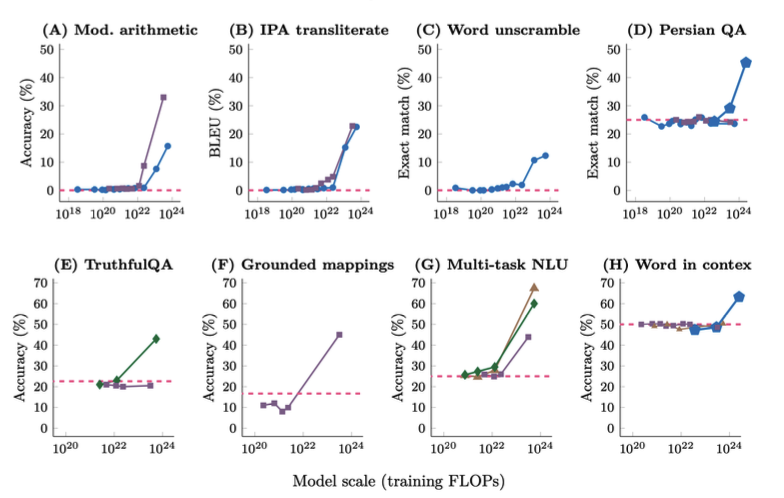 LLM의 신기한 특징중 하나는, model size가 커지다 보면 어느새 특정 task에 대한 능력이 생긴다는 것이다. 입력 맥락에 맞는 숫자 연산을 한다거나, 섞인 알파벳 철자를 찾아낼 수도 있다.
LLM의 신기한 특징중 하나는, model size가 커지다 보면 어느새 특정 task에 대한 능력이 생긴다는 것이다. 입력 맥락에 맞는 숫자 연산을 한다거나, 섞인 알파벳 철자를 찾아낼 수도 있다. 
또한 이전 NLP 시대에서는 downstream task를 하기 위해서 fine tuning을 해야 했지만, LLM은 파인튜닝 없이 Zero-shot이나 Few-shot 방식으로 downstream task를 해결한다. 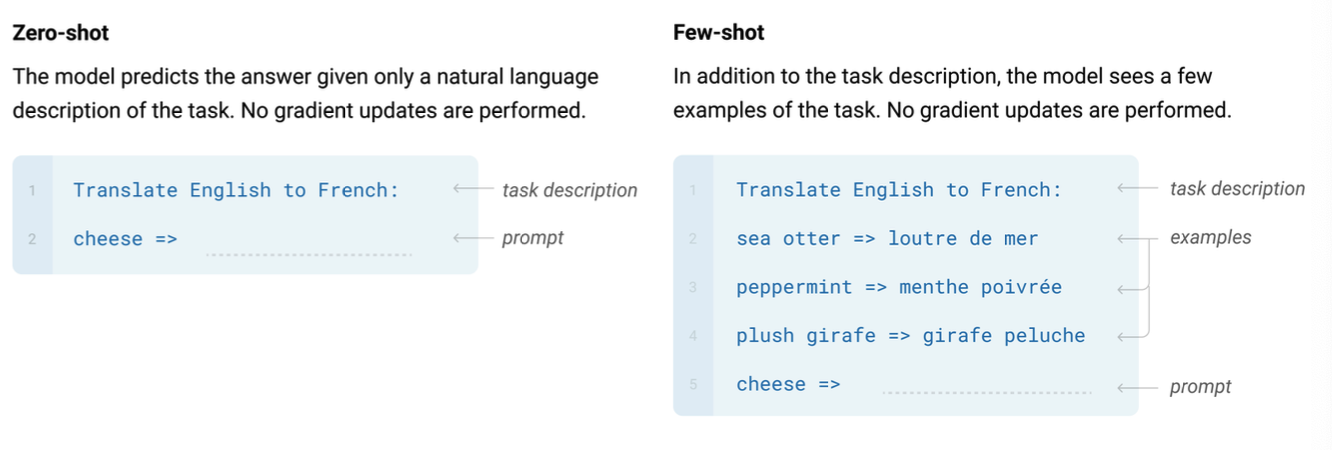
주목받는 LLM 모델과 각각의 특징을 간략히 정리해보면, llama는 SwiGLU를 적용했고, llama2에서는 training tokens을 크게 늘린 점이 falcon은 180B라는 거대한 model size가 mistral은 sliding window attention이라는 attention 기법이 독특한 점이다.
친칠라 법칙(The Chinchilla Law)
친칠라 법칙은 model size뿐만 아니라, training data의 크기도 늘려야 최적의 computation-accuracy trade-off 하는 지점을 찾을 수 있다는 것이다. (무조건 data 크기를 늘리는게 좋다는게 아니라 데이터 양에 따른 최적 model size가 있다는 뜻이다) llama-2가 비교적 적은 파라미터와 많은 train token으로 좋은 성능을 보여준다. 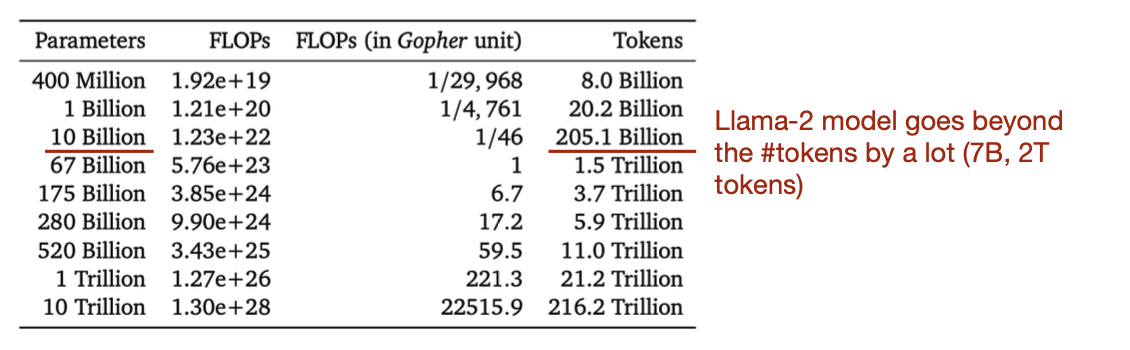
4. Advanced topics, multi-modal LLM
이후 강의에서 한번 더 자세히 다루기 때문에 이번 강의 정리 글에서는 생략합니다
5. Efficient inference algorithms for LLMs
앞선 강의들에서 inference를 효율적으로 하기 위한 방법으로 quantization과 pruning의 방법이 있었고, 이 방법들을 LLM에도 적용해 볼 수 있을 것입니다.
5.1. Quantization: SmoothQuant, AWQ, TinyChat
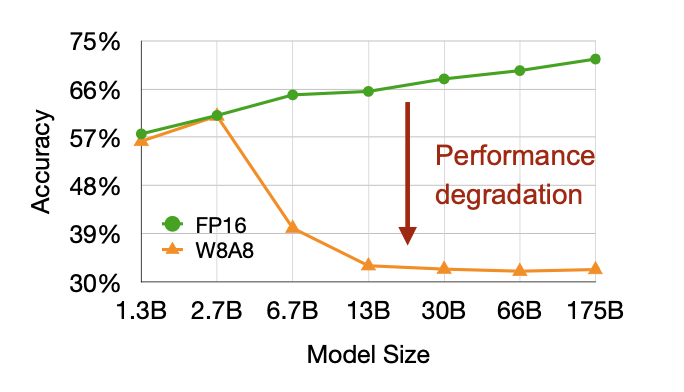 하지만, 단순히 W8A8과 같이 quantize하는 것은, 굉장히 큰 성능 저하를 보여준다 이유는, LLM에서는 activation의 outlier가 중요한 역할을 하기 때문이다
하지만, 단순히 W8A8과 같이 quantize하는 것은, 굉장히 큰 성능 저하를 보여준다 이유는, LLM에서는 activation의 outlier가 중요한 역할을 하기 때문이다 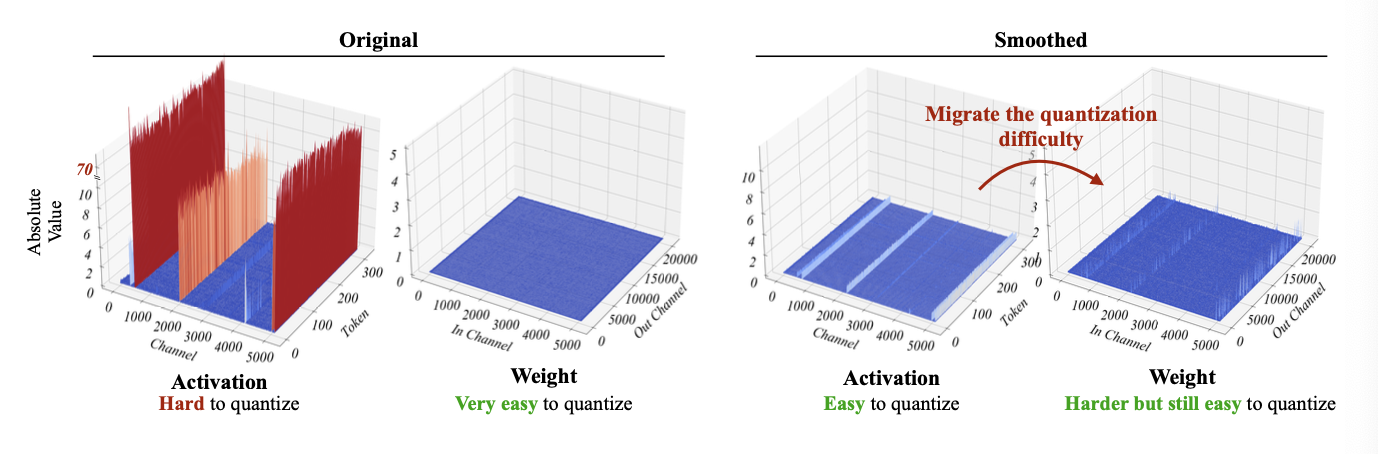 위 그림의 오른쪽처럼 activation에는 굉장히 큰 outlier가 존재하고 weight는 비교적 편차가 없다. 따라서 activation을 10으로 나누고, weight에 10을 곱하면 수식의 값은 변하지 않지만, activation을 좀 더 편하게 quantize할 수 있게 된다(오른쪽 그림). 이런 방식을 activation을 좀더 평평하게 만든다고 해서 smoothQuant라고 한다.
위 그림의 오른쪽처럼 activation에는 굉장히 큰 outlier가 존재하고 weight는 비교적 편차가 없다. 따라서 activation을 10으로 나누고, weight에 10을 곱하면 수식의 값은 변하지 않지만, activation을 좀 더 편하게 quantize할 수 있게 된다(오른쪽 그림). 이런 방식을 activation을 좀더 평평하게 만든다고 해서 smoothQuant라고 한다.  smoothQuant방식은 llama 모델에서도 매우 잘 동작한다.
smoothQuant방식은 llama 모델에서도 매우 잘 동작한다.
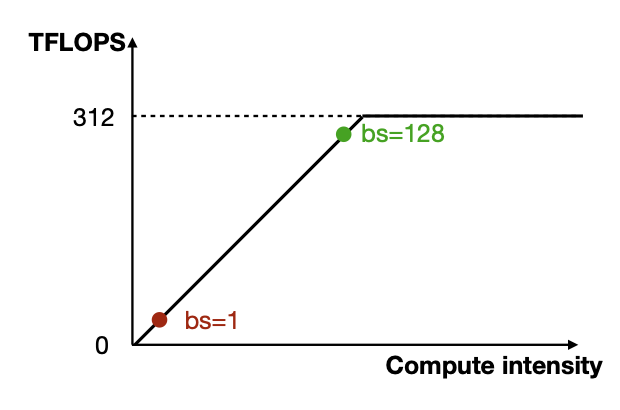 위 그림의 x축인 compute intensity는 FLOPs / MemoryBandwith를 나타낸다. 즉, 데이터 하나당 연산을 얼마나 효율적으로 할 수 있느냐에 대한 지표이다. 위 그림에서 batch size가 1일 때 낮은 TFLOPS를 보이는 이유는 메모리 때문이다. LLM에서 매 토큰을 생성하기 위해서는 큰 메모리 fetch가 필요하다(parameter fetch.). activation과 weight 중에서는 weight가 훨씬 더 크므로, weight를 줄이는데 더 집중해야 한다.
위 그림의 x축인 compute intensity는 FLOPs / MemoryBandwith를 나타낸다. 즉, 데이터 하나당 연산을 얼마나 효율적으로 할 수 있느냐에 대한 지표이다. 위 그림에서 batch size가 1일 때 낮은 TFLOPS를 보이는 이유는 메모리 때문이다. LLM에서 매 토큰을 생성하기 위해서는 큰 메모리 fetch가 필요하다(parameter fetch.). activation과 weight 중에서는 weight가 훨씬 더 크므로, weight를 줄이는데 더 집중해야 한다.
위에서 살펴본 W8A8 방식의 quantization은 batch serving(한번에 여러 batch를 처리하는 일)에서는 잘 동작한다. 하나만 처리하는 작업은(single-batch) memory-bounded(메모리가 부족하면 bottleneck이 된다)이다. 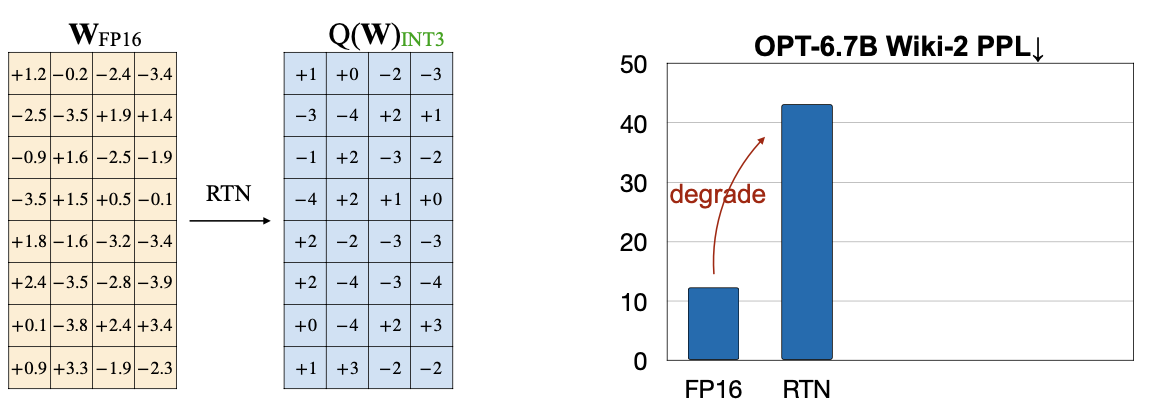 당연히 weight를 바로 quantize 하면 위 그림처럼 성능 저하가 발생한다 오른쪽 그림을 살펴보면, RTN방식을 단순히 적용한 경우 Perplexity가 많이 상승한 것을 볼 수 있다.
당연히 weight를 바로 quantize 하면 위 그림처럼 성능 저하가 발생한다 오른쪽 그림을 살펴보면, RTN방식을 단순히 적용한 경우 Perplexity가 많이 상승한 것을 볼 수 있다. 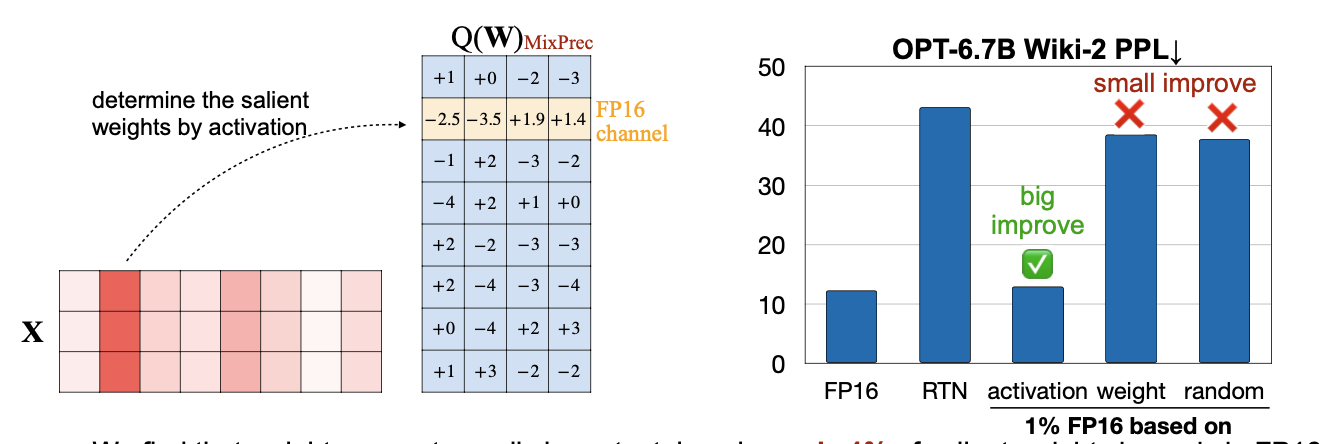 더 나은 방법은, 중요한(salient) weight들만 quantize 하지 않고 두는 것인데, salient 하다고 판단하는 기준을 “activation”값을 기반으로 판단할 때(magnitude-base, 단순히 절댓값이 크면 중요하다고 판단) 좋은 성능을 보인다. 이런 방식을 AWQ(Activation-aware Weight Quantization) 라고 한다.
더 나은 방법은, 중요한(salient) weight들만 quantize 하지 않고 두는 것인데, salient 하다고 판단하는 기준을 “activation”값을 기반으로 판단할 때(magnitude-base, 단순히 절댓값이 크면 중요하다고 판단) 좋은 성능을 보인다. 이런 방식을 AWQ(Activation-aware Weight Quantization) 라고 한다.
SmoothQuant와 AWQ는 오늘날 널리 사용되는 방식이다.
5.2. Pruning/sparsity: SpAtten, H2O, MoE
quantization을 했으면, pruning도 해 봐야 한다. 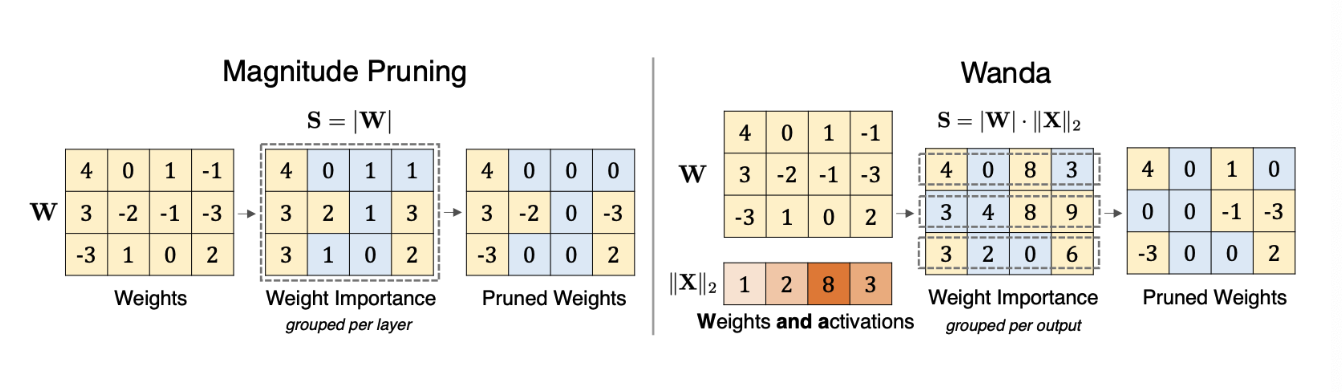 Wanda는 AWQ처럼 Weight와 Activation을 고려해서 pruning 하는 방식이다
Wanda는 AWQ처럼 Weight와 Activation을 고려해서 pruning 하는 방식이다 
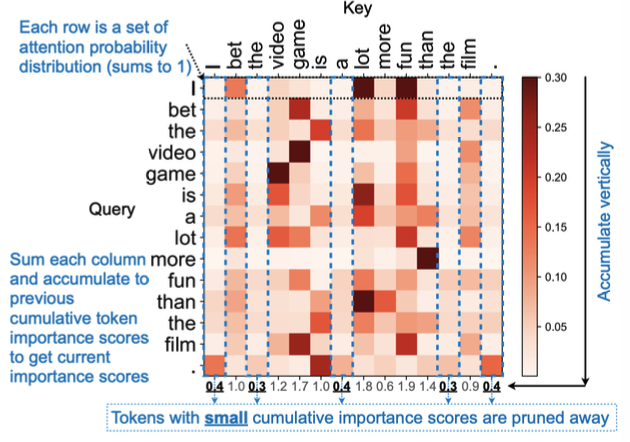 SpAtten은 중요하지 않은 토큰 자체를 삭제하는 방식이다. 오른쪽 attention 맵 기반으로, 가장 낮은 attention 합계를 가진 토큰을 삭제한다.
SpAtten은 중요하지 않은 토큰 자체를 삭제하는 방식이다. 오른쪽 attention 맵 기반으로, 가장 낮은 attention 합계를 가진 토큰을 삭제한다. 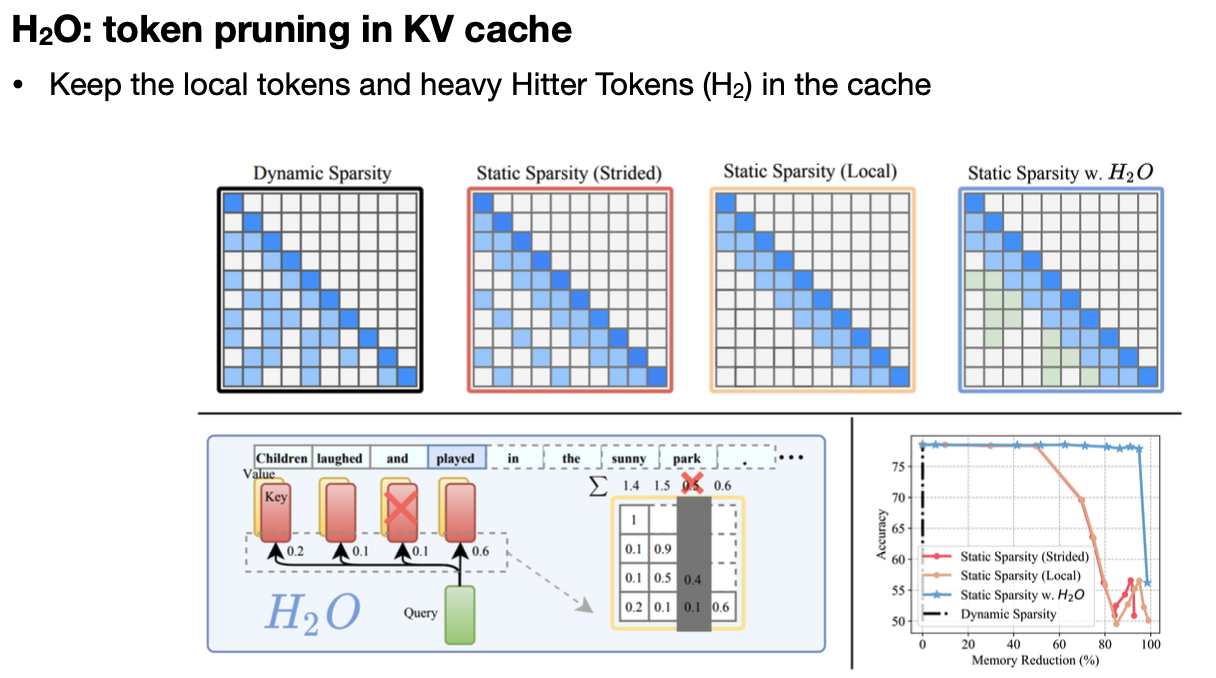 H2O는 Heavy Hitter Token(H2)를 중심으로 남기고, 나머지를 pruning하는 방식이다. 여기서 말하는 Heavy Hitter란 attention 기반으로 선정한다. 이해하기로는, SpAtten의 방식과 비슷하다고 느꼈다.
H2O는 Heavy Hitter Token(H2)를 중심으로 남기고, 나머지를 pruning하는 방식이다. 여기서 말하는 Heavy Hitter란 attention 기반으로 선정한다. 이해하기로는, SpAtten의 방식과 비슷하다고 느꼈다. 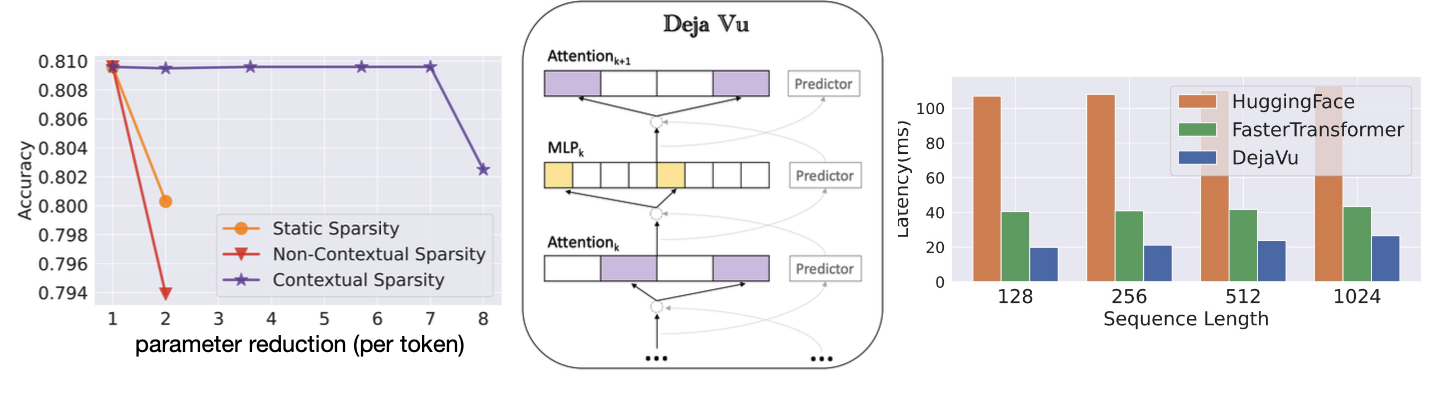 DejaVu는 입력에 영향을 받지 않는 attention head들이 존재하고, 이것을 contextual sparsity라고 부르며, 이 패턴을 MLP를 통해 예상할 수 있다는 가설을 세웠다. 이런 contextual sparsity를 제거하는 방식을 DejaVu는 사용했다.
DejaVu는 입력에 영향을 받지 않는 attention head들이 존재하고, 이것을 contextual sparsity라고 부르며, 이 패턴을 MLP를 통해 예상할 수 있다는 가설을 세웠다. 이런 contextual sparsity를 제거하는 방식을 DejaVu는 사용했다. 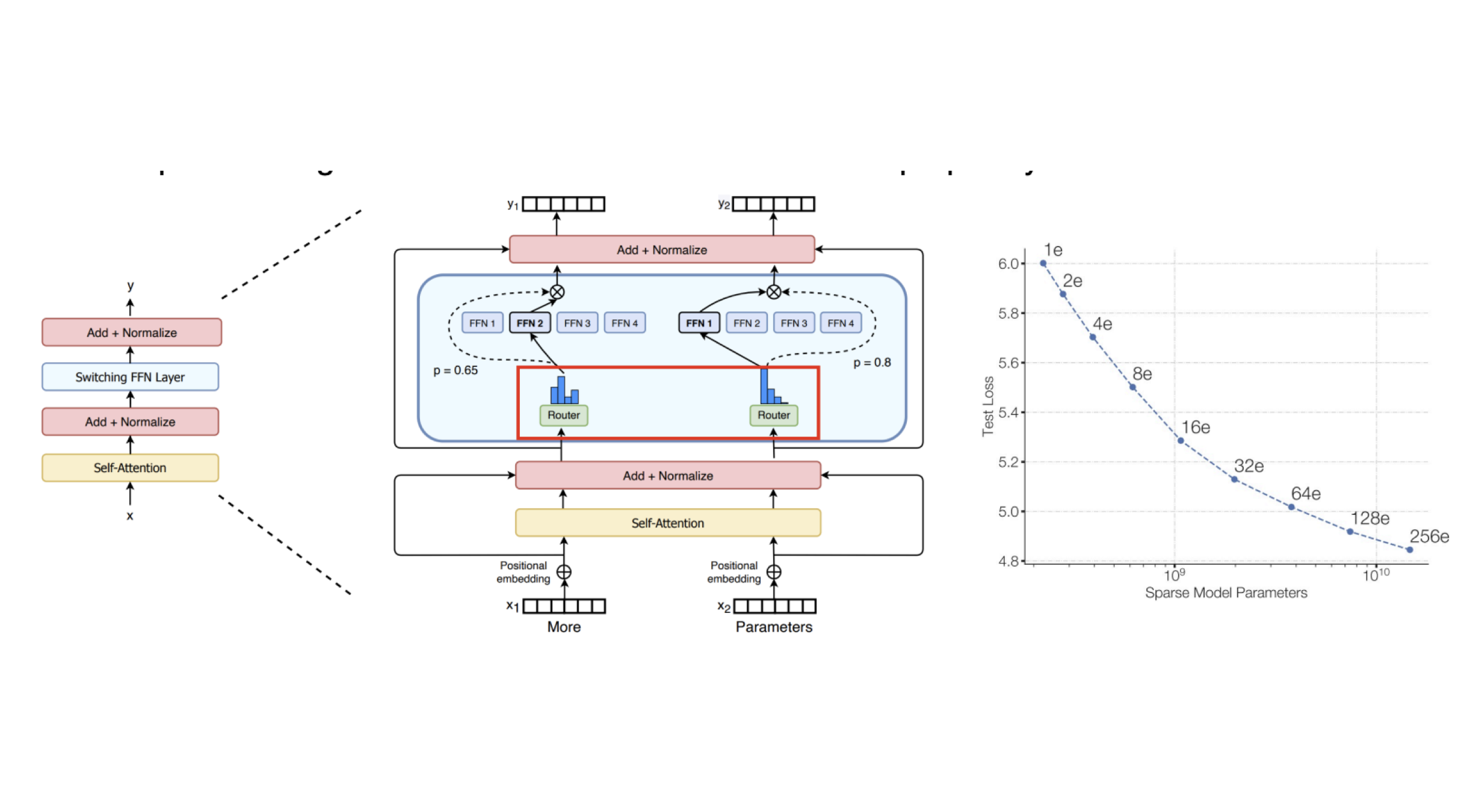 MoE(Mixture of Experts) 는 FFN을 N개로 나누고, Expert를 사용해 그중에 하나를 고르는 개념을 도입한다. 그림 중간에 있는 Router로부터 확률적으로 어떤 FFN을 사용할지 MoE방식은 GPT-4에서 사용하고 있다고 알려져 있다.
MoE(Mixture of Experts) 는 FFN을 N개로 나누고, Expert를 사용해 그중에 하나를 고르는 개념을 도입한다. 그림 중간에 있는 Router로부터 확률적으로 어떤 FFN을 사용할지 MoE방식은 GPT-4에서 사용하고 있다고 알려져 있다.
6. Efficient inference systems for LLMs
이 장에서는 system적 관점에서 더 효율적으로 LLM을 inference하는 법에 다룬다.
6.1. vLLM(Paged Attention)
다수의 사용자가 LLM을 사용하는 환경에선 무엇이 문제가 될까? 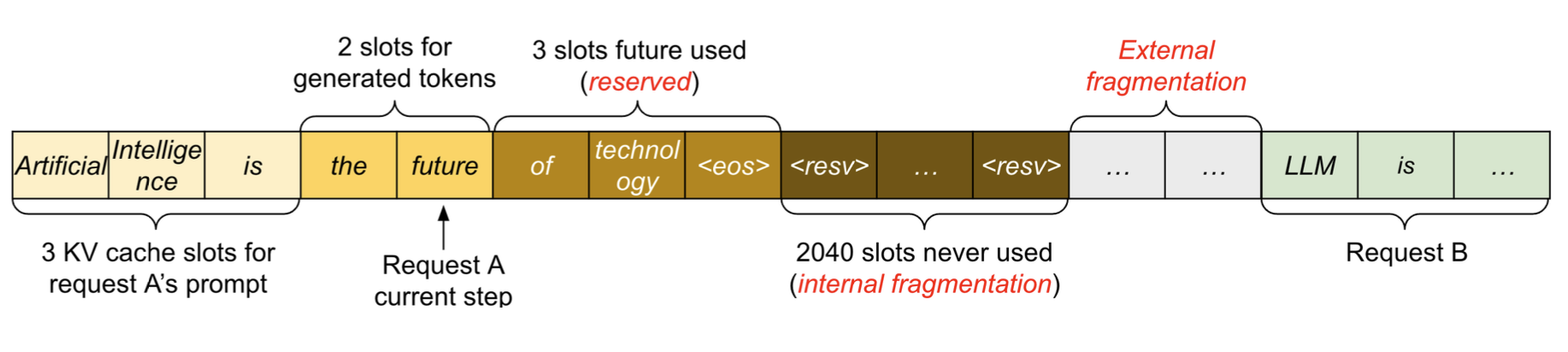 위 그림처럼 우리는 LLM의 출력이 얼마나 길어질 지 모르기 떄문에, 얼마나 메모리를 할당해야 할 지 알 수 없다. 따라서 <resv> 처럼 내부 단편화, 혹은 다른 요청간의 간격으로 인해 외부 단편화가 발생하게 된다. 마치 실제 운영체제의 메모리같다. 그렇다면, 재밌게도 운영체제에서 사용했던 방법으로 이를 해결할 수 있고, 그 방법이 바로 Page를 사용하는 방식이다.
위 그림처럼 우리는 LLM의 출력이 얼마나 길어질 지 모르기 떄문에, 얼마나 메모리를 할당해야 할 지 알 수 없다. 따라서 <resv> 처럼 내부 단편화, 혹은 다른 요청간의 간격으로 인해 외부 단편화가 발생하게 된다. 마치 실제 운영체제의 메모리같다. 그렇다면, 재밌게도 운영체제에서 사용했던 방법으로 이를 해결할 수 있고, 그 방법이 바로 Page를 사용하는 방식이다.
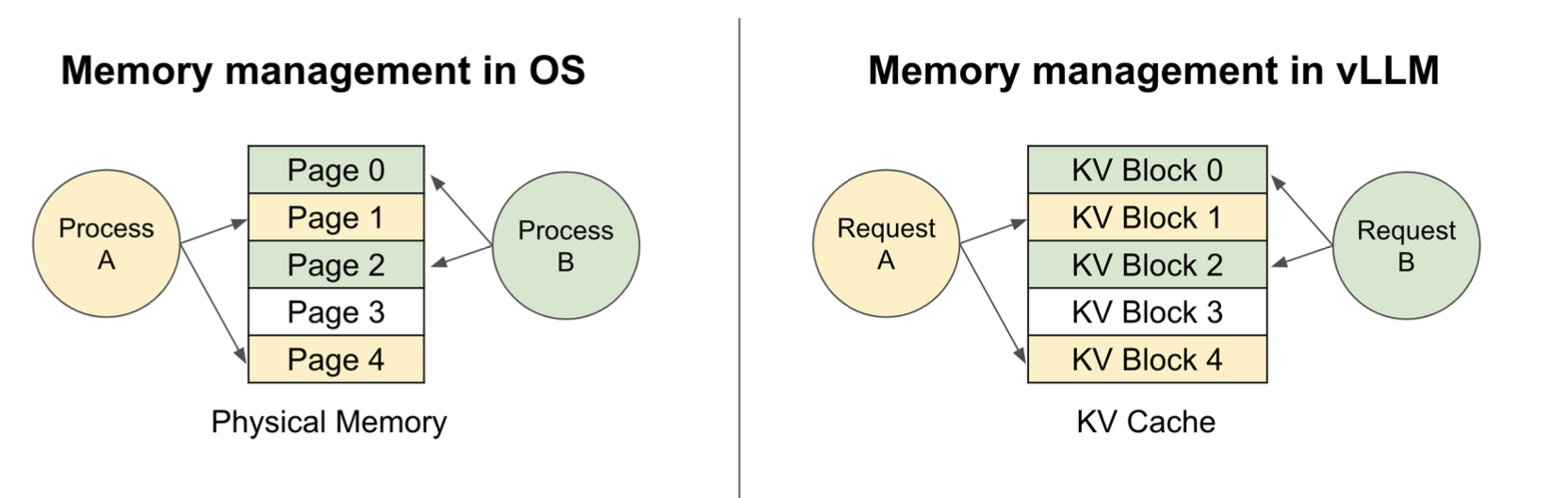 OS에서 다른 프로세스간 메모리를 사용할 때 page단위로 사용했듯이, LLM에서도 다른 요청들 간에 KV cache를 page 단위로 사용하면 된다.
OS에서 다른 프로세스간 메모리를 사용할 때 page단위로 사용했듯이, LLM에서도 다른 요청들 간에 KV cache를 page 단위로 사용하면 된다. 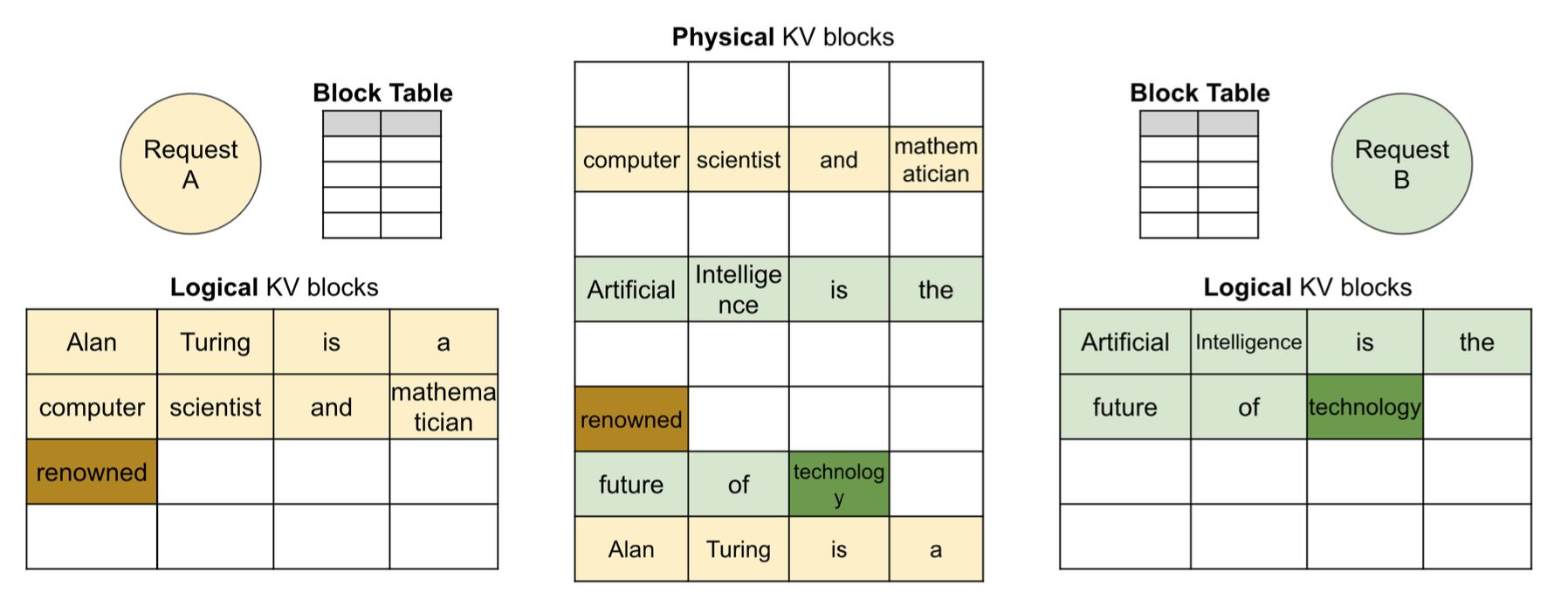 위처럼 다른 요청을 page단위로 받을 수 있다.
위처럼 다른 요청을 page단위로 받을 수 있다.
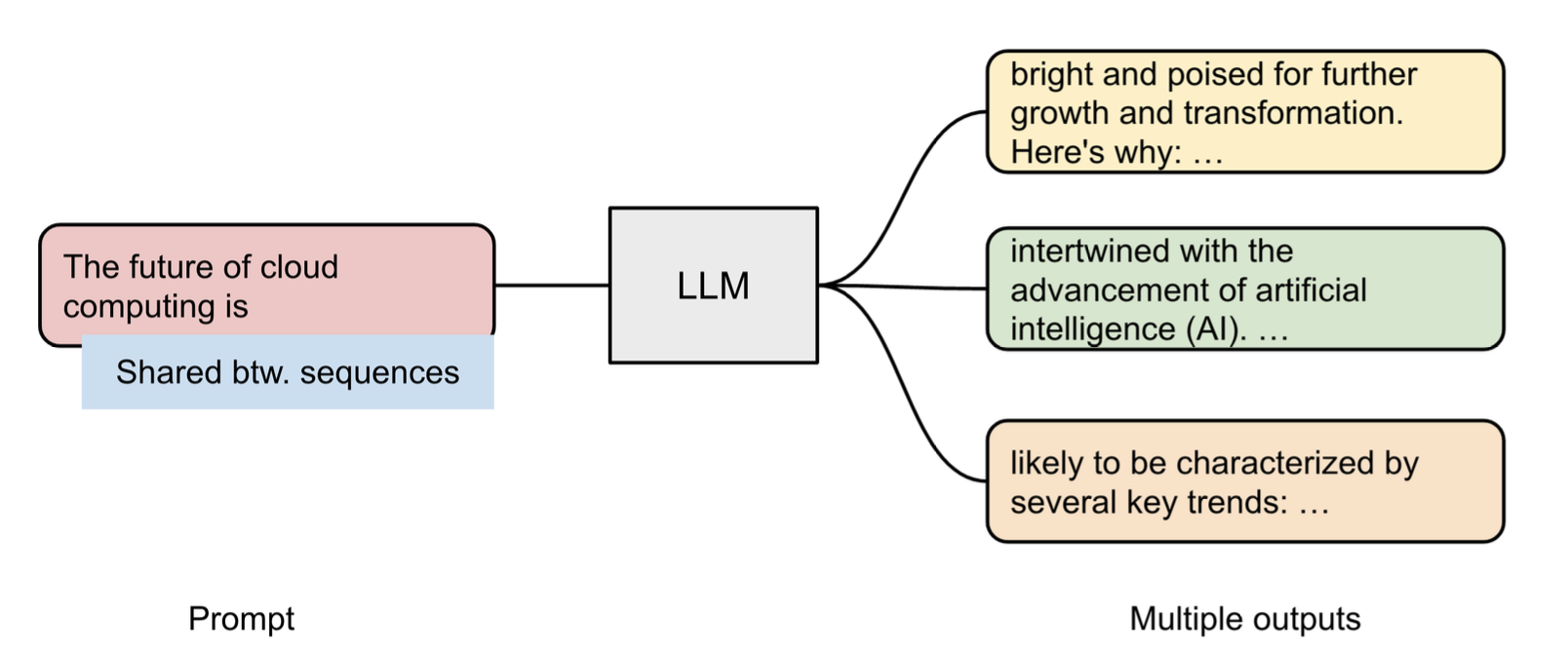 더 놀라운 점은, 하나의 KV Cache를 공유할 수 있다는 점이다. 앞 문장을 공유하거나, 아니면 Prompt같이 많이 사용되는 문장의 KV cache를 공유해 효율적으로 대량의 inference가 가능하다.
더 놀라운 점은, 하나의 KV Cache를 공유할 수 있다는 점이다. 앞 문장을 공유하거나, 아니면 Prompt같이 많이 사용되는 문장의 KV cache를 공유해 효율적으로 대량의 inference가 가능하다.
이런 방식을 Paged Attention 이라고 하고, 이 방법을 사용한 것이 vLLM이라는 방법론이다.
6.2. StreamingLLM
LLM 배포시 또 다른 문제는 길이 문제이다. 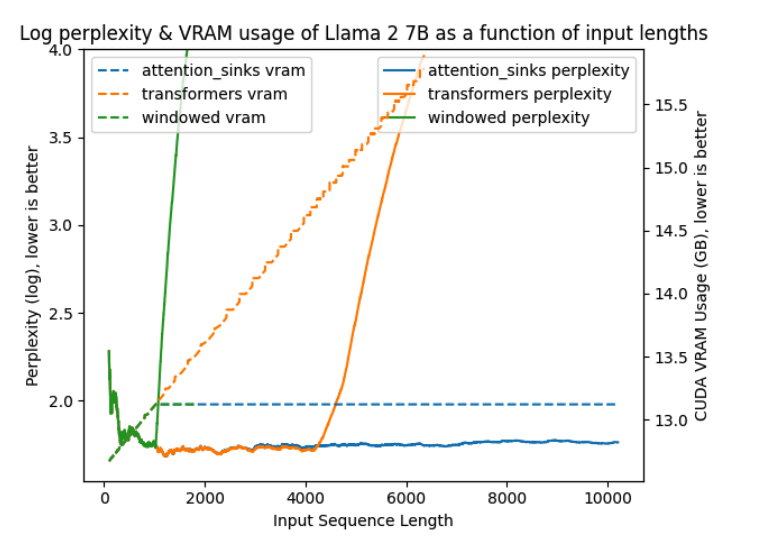 엄청나게 긴 문장이나, 혹은 챗봇에서 엄청 예전에 이야기했던 내용까지 기억하려면 메모리가 매우 많이 필요하다. 단순히 transformer 방식을 사용하면(노란색 그래프) 메모리는 선형적으로 증가하고, perplexity는 입력 길이 4K 이후로 폭발적으로 증가한다(training에서 보지 못한 길이이기 때문에) windowed attention(일정 context만 기억, 녹색)은 메모리 사용량은 일정하지만 입력 길이가 window길이를 벗어나는 순간(그림에서는 1K정도) perplexity가 급증한다(첫 몇 토큰이 매우 중요하기 때문에)
엄청나게 긴 문장이나, 혹은 챗봇에서 엄청 예전에 이야기했던 내용까지 기억하려면 메모리가 매우 많이 필요하다. 단순히 transformer 방식을 사용하면(노란색 그래프) 메모리는 선형적으로 증가하고, perplexity는 입력 길이 4K 이후로 폭발적으로 증가한다(training에서 보지 못한 길이이기 때문에) windowed attention(일정 context만 기억, 녹색)은 메모리 사용량은 일정하지만 입력 길이가 window길이를 벗어나는 순간(그림에서는 1K정도) perplexity가 급증한다(첫 몇 토큰이 매우 중요하기 때문에) 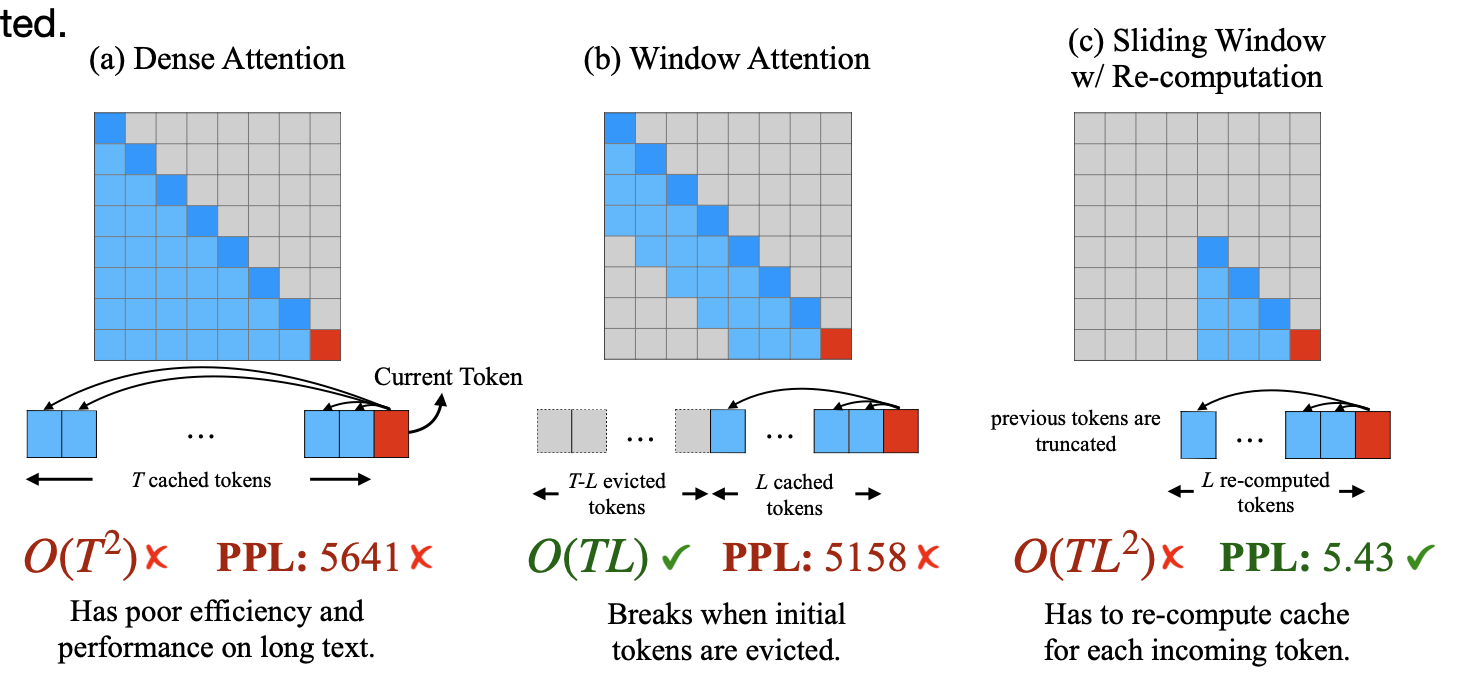 a가 위에서 말한 단순 transformer방식, b가 windowed attention이다. c는 sliding window방식인데, 이전 토큰을 메모리에 두는게 아니라 다시 계산하는 방법이다. 이 방법은 perplexity는 괜찮지만, 연산하는데 너무 많은 시간이 든다.
a가 위에서 말한 단순 transformer방식, b가 windowed attention이다. c는 sliding window방식인데, 이전 토큰을 메모리에 두는게 아니라 다시 계산하는 방법이다. 이 방법은 perplexity는 괜찮지만, 연산하는데 너무 많은 시간이 든다.
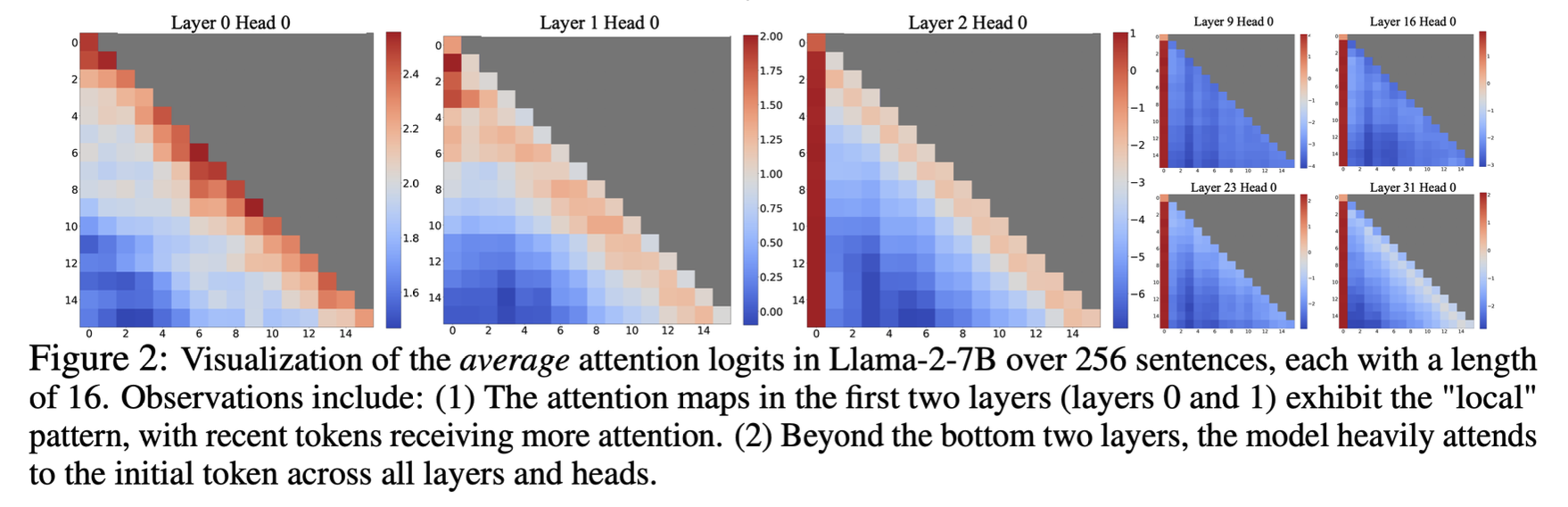 이런 문제를 해결하기 위해 찾아내기 위한 아이디어를 Attention Sink에서 찾았다. 위 그림에서 보면 첫번째 토큰의 attention score가 매우 높은 것을 알 수 있다. 그런데, 그들이 문맥적으로(semantically)중요하지 않은 경우에도 그렇다. 이런 현상을 Attention Sink라고 하는데, 왜 일어나는 현상일까?
이런 문제를 해결하기 위해 찾아내기 위한 아이디어를 Attention Sink에서 찾았다. 위 그림에서 보면 첫번째 토큰의 attention score가 매우 높은 것을 알 수 있다. 그런데, 그들이 문맥적으로(semantically)중요하지 않은 경우에도 그렇다. 이런 현상을 Attention Sink라고 하는데, 왜 일어나는 현상일까? 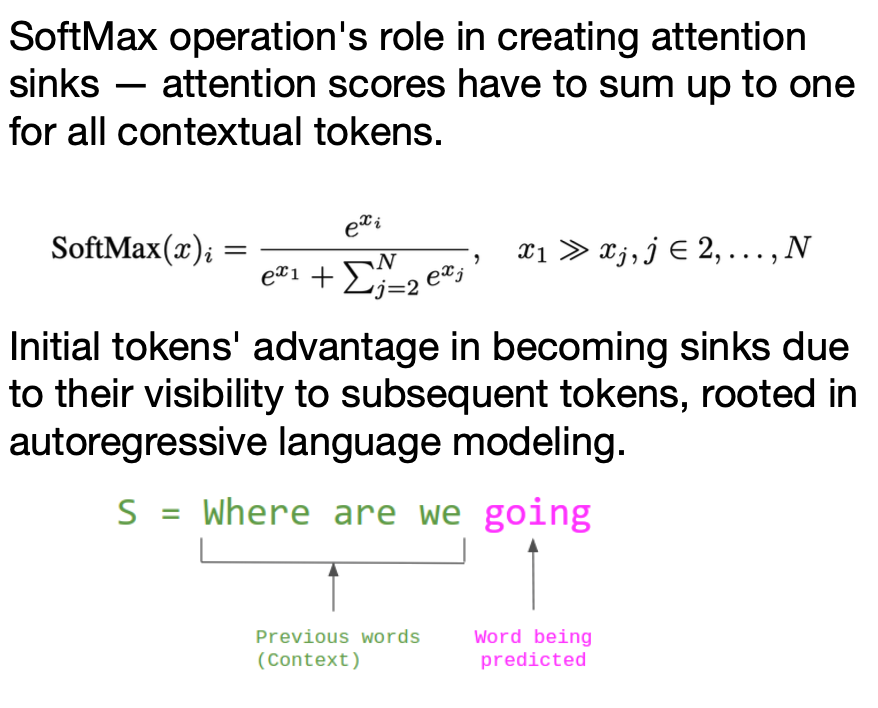 attention을 구할 때 softmax를 사용하게 되는데, decoding을 하면서 첫번째 토큰은 모든 토큰을 decode 할 때 등장하게 되므로, 당연히 어느정도의 값을 계속 더해가서 생기는 현상이라는 것이다.
attention을 구할 때 softmax를 사용하게 되는데, decoding을 하면서 첫번째 토큰은 모든 토큰을 decode 할 때 등장하게 되므로, 당연히 어느정도의 값을 계속 더해가서 생기는 현상이라는 것이다. 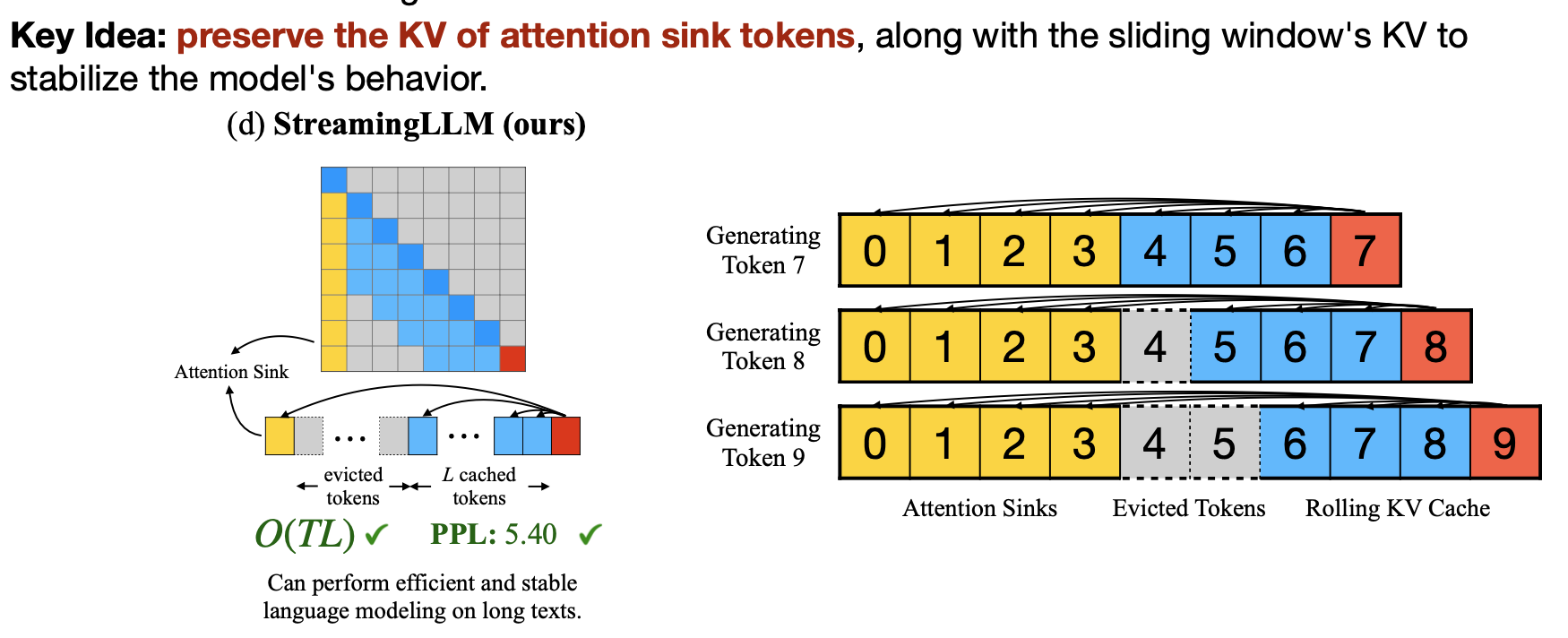 그래서 이런 attention sink가 일어나는 첫 토큰은 무조건 남겨두고, windowed attention을 사용하면 더 괜찮은 결과를 얻을 수 있다는 것이다. 이런 현상에 대한 논리적인 설명은 찾지 못했지만, 아마도 첫 토큰이 문맥적으로 중요하지 않더라도 “sink(쌓아두는)”의 역할을 하는 것이라고 생각된다.
그래서 이런 attention sink가 일어나는 첫 토큰은 무조건 남겨두고, windowed attention을 사용하면 더 괜찮은 결과를 얻을 수 있다는 것이다. 이런 현상에 대한 논리적인 설명은 찾지 못했지만, 아마도 첫 토큰이 문맥적으로 중요하지 않더라도 “sink(쌓아두는)”의 역할을 하는 것이라고 생각된다. 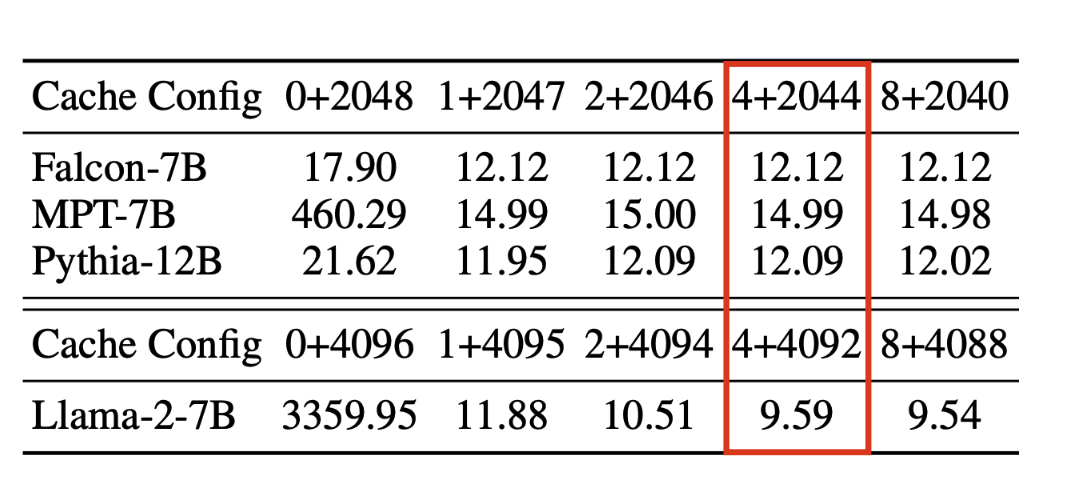 ablation study에서는 하나의 토큰이 아니라, 4개의 token을 sink로 하는게 평균적으로 좋다는 결과가 있다
ablation study에서는 하나의 토큰이 아니라, 4개의 token을 sink로 하는게 평균적으로 좋다는 결과가 있다
6.3. FlashAttention
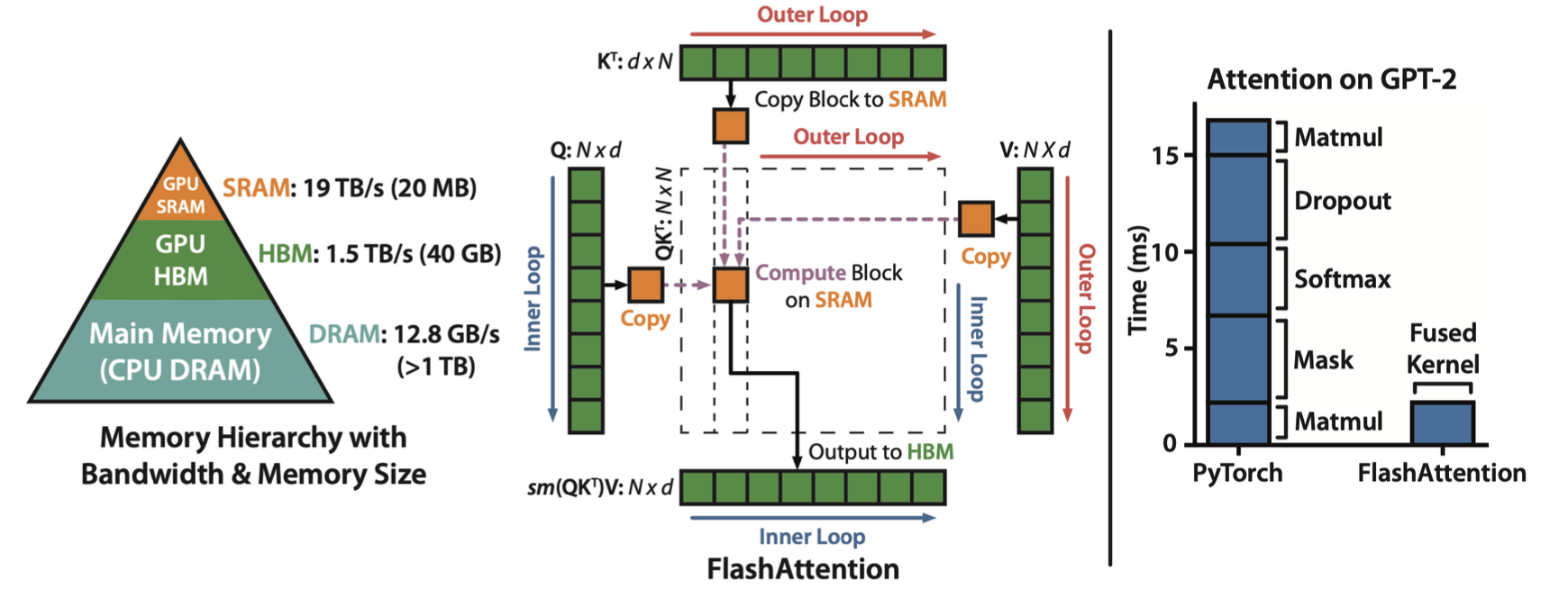 FlashAttention은 좀 더 하드웨어적인 접근이다. HBM(High Bandwith Memory)에 접근하는 횟수를 줄이는 아이디어이다. 행렬 연산을 할 때 전체 메모리를 불러오는 것이 아니라 하나씩 불러와서(Copy Block to SRAM부분) GPU의 SRAM 내에서 연산을 최대한 마치겠다는 아이디어이다. 앞에서 다뤘던 MQA, GQA등을 적용한 FlashAttention-2라는 논문도 있다.
FlashAttention은 좀 더 하드웨어적인 접근이다. HBM(High Bandwith Memory)에 접근하는 횟수를 줄이는 아이디어이다. 행렬 연산을 할 때 전체 메모리를 불러오는 것이 아니라 하나씩 불러와서(Copy Block to SRAM부분) GPU의 SRAM 내에서 연산을 최대한 마치겠다는 아이디어이다. 앞에서 다뤘던 MQA, GQA등을 적용한 FlashAttention-2라는 논문도 있다.
6.4. Speculative decoding
LLM의 decoding은 매우 memory-bounded하다. 하나하나의 토큰을 생성할 때마다 매우 많은 메모리 연산이 필요하다. Speculative Decoding은 이런 문제를 해결하기 위해 작은 모델로 K개의 토큰을 생성한 뒤 큰 모델로 이 토큰이 좋은지 아닌지 판단하고 대안을 생성한다(큰 모델에서는 batch size가 1일 때나 K일때나 비슷하므로) 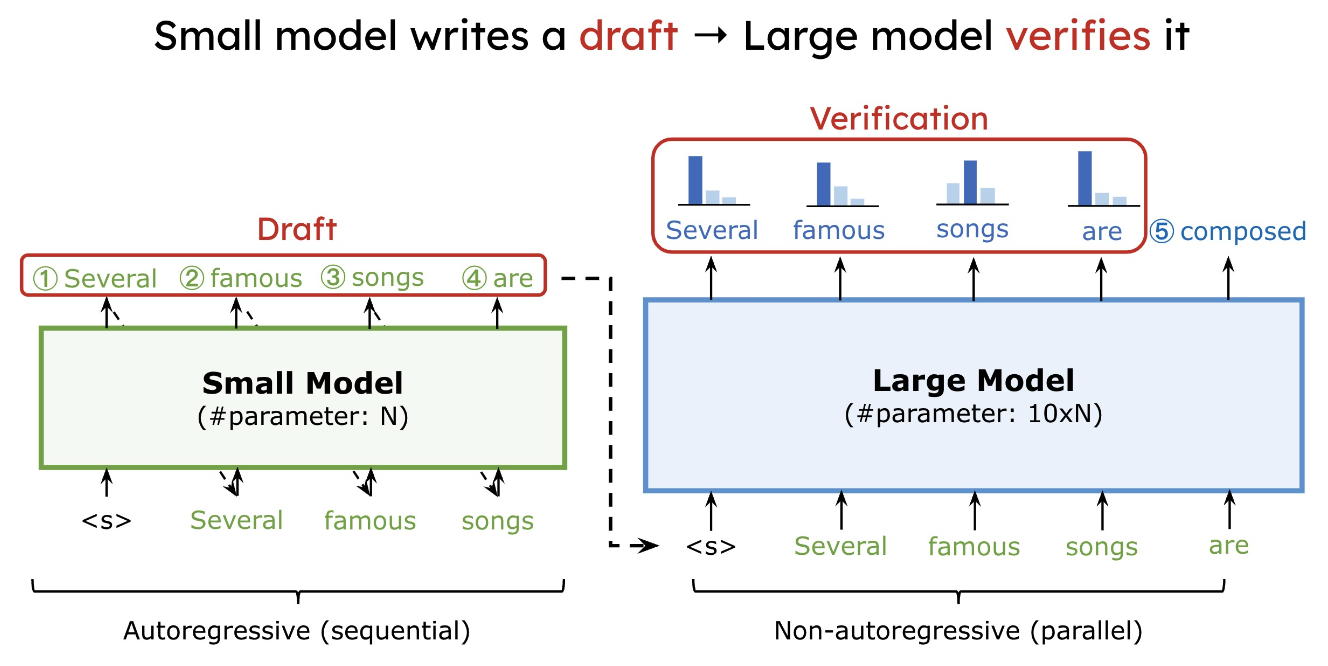 K개의 token을 생성할 때, 큰 모델을 K번 호출하는 것이 아니라 작은 모델을 K번, 큰 모델은 1번만 호출하면 되므로 decoding 시간을 절약할 수 있다(대략 2~3배)
K개의 token을 생성할 때, 큰 모델을 K번 호출하는 것이 아니라 작은 모델을 K번, 큰 모델은 1번만 호출하면 되므로 decoding 시간을 절약할 수 있다(대략 2~3배)
7. Efficient fine-tuning for LLMs
이번 장에서는 LLM fine tuning을 효율적으로 하는 법을 알아본다.
7.1. LoRA/QLoRA
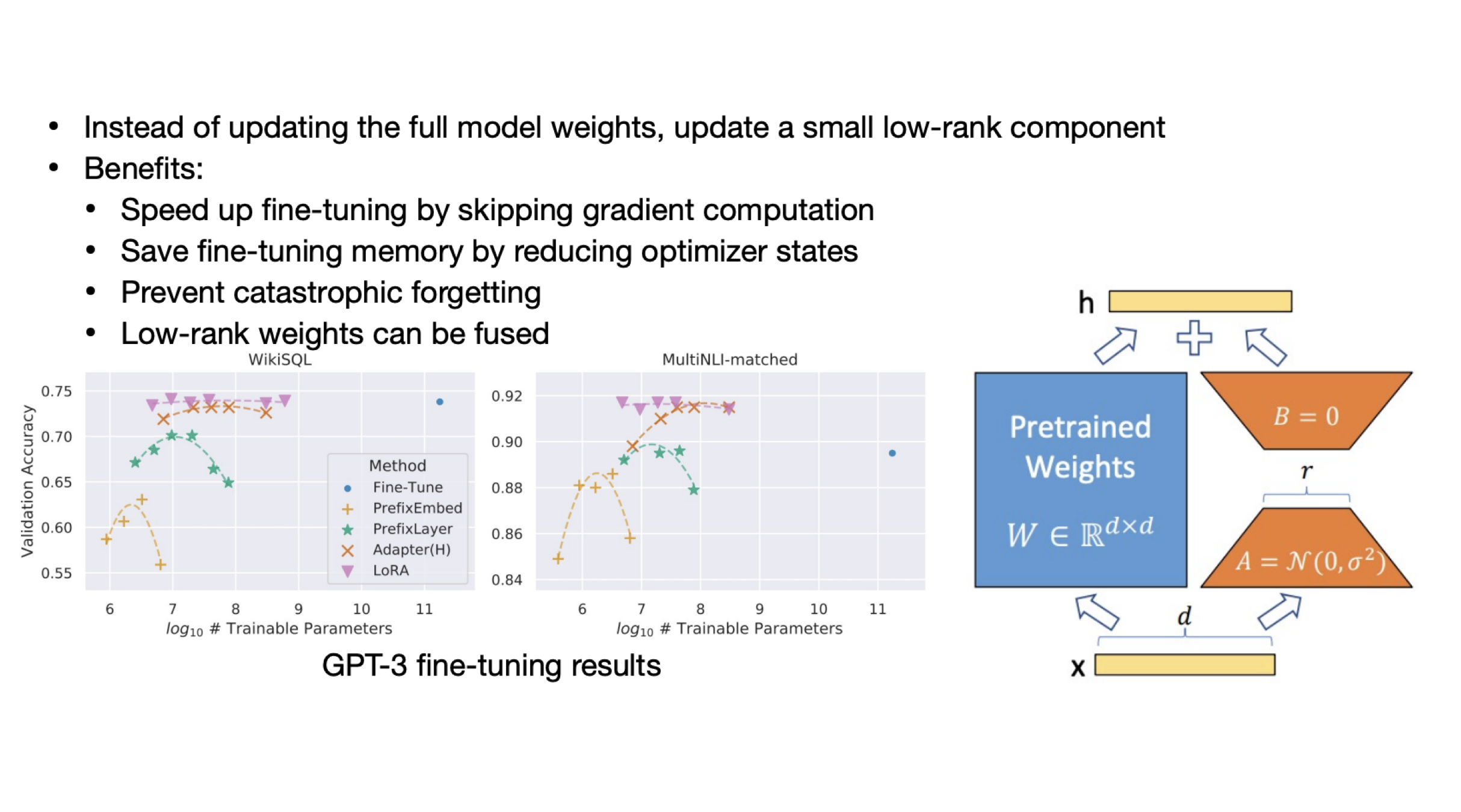 LoRA는 모델 전체를 update하는게 아니라, 작은 bypass branch의 weight만 update하는 방법이다. LLM을 pretrain한 가중치 W가 있고, full-fine tuning했을 때 달라지는 가중치를 delta W라고 하자. 그러면 그 delta W를 low-rank 행렬인 A와 B의 곱(위 그림의 주황색 행렬)으로 나타내자는 아이디어이다.
LoRA는 모델 전체를 update하는게 아니라, 작은 bypass branch의 weight만 update하는 방법이다. LLM을 pretrain한 가중치 W가 있고, full-fine tuning했을 때 달라지는 가중치를 delta W라고 하자. 그러면 그 delta W를 low-rank 행렬인 A와 B의 곱(위 그림의 주황색 행렬)으로 나타내자는 아이디어이다.
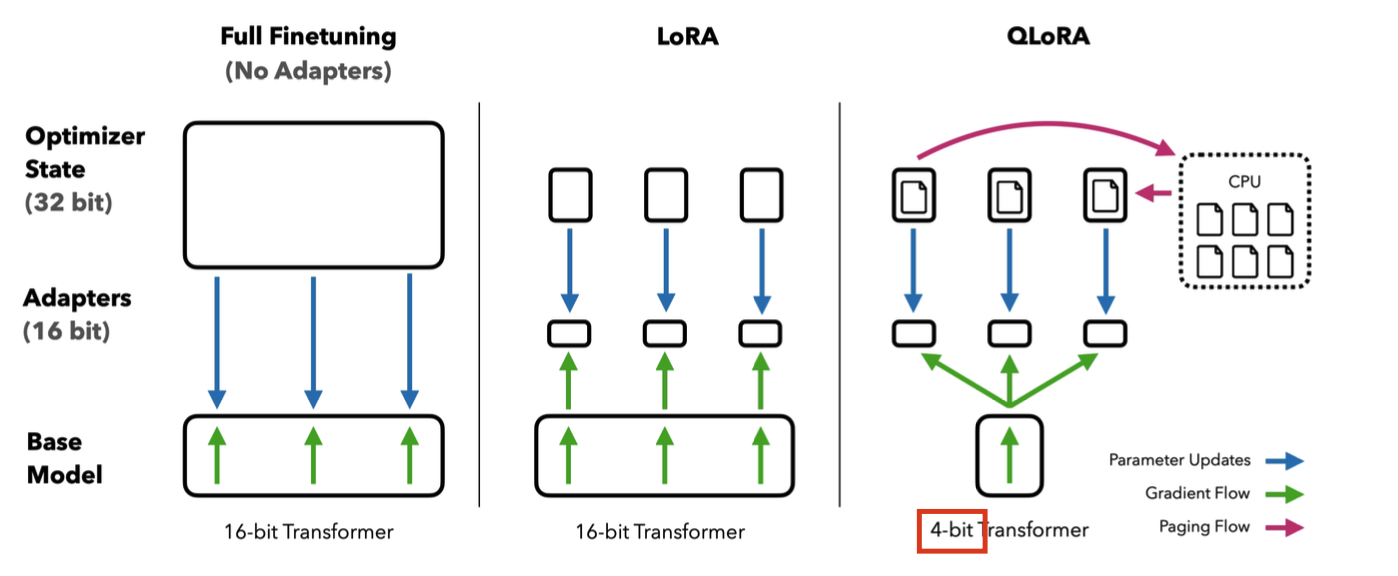 QLoRA는 간단히 말하면 LoRA에 quantization을 더한 것이다. NF4(NormalFloat4)라는 normal distribution에 최적화된 데이터 타입, Double Quantization, paged optimizer등의 기법을 사용한다.
QLoRA는 간단히 말하면 LoRA에 quantization을 더한 것이다. NF4(NormalFloat4)라는 normal distribution에 최적화된 데이터 타입, Double Quantization, paged optimizer등의 기법을 사용한다.
7.2. Adapter
Adapter는 transformer 블록에 learnable한 작은 블록을 하나 끼워 넣는 것이다. 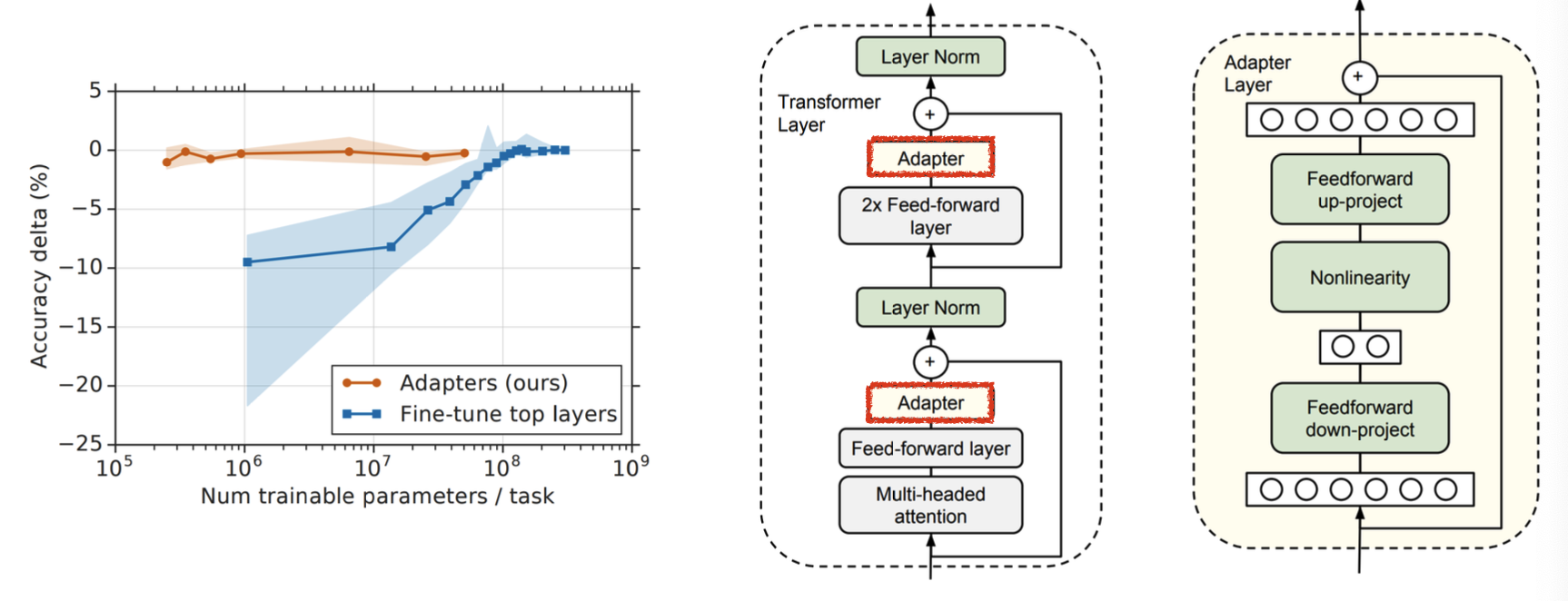 위 그림에서 어댑터는 오른쪽 노란색 구조를 넣은 것이다. 하지만 새로운 layer가 추가되는 것이라, inference시 시간이 조금 더 늘어날 수 있다는 문제점이 있다.
위 그림에서 어댑터는 오른쪽 노란색 구조를 넣은 것이다. 하지만 새로운 layer가 추가되는 것이라, inference시 시간이 조금 더 늘어날 수 있다는 문제점이 있다.
7.3. Prompt Tuning
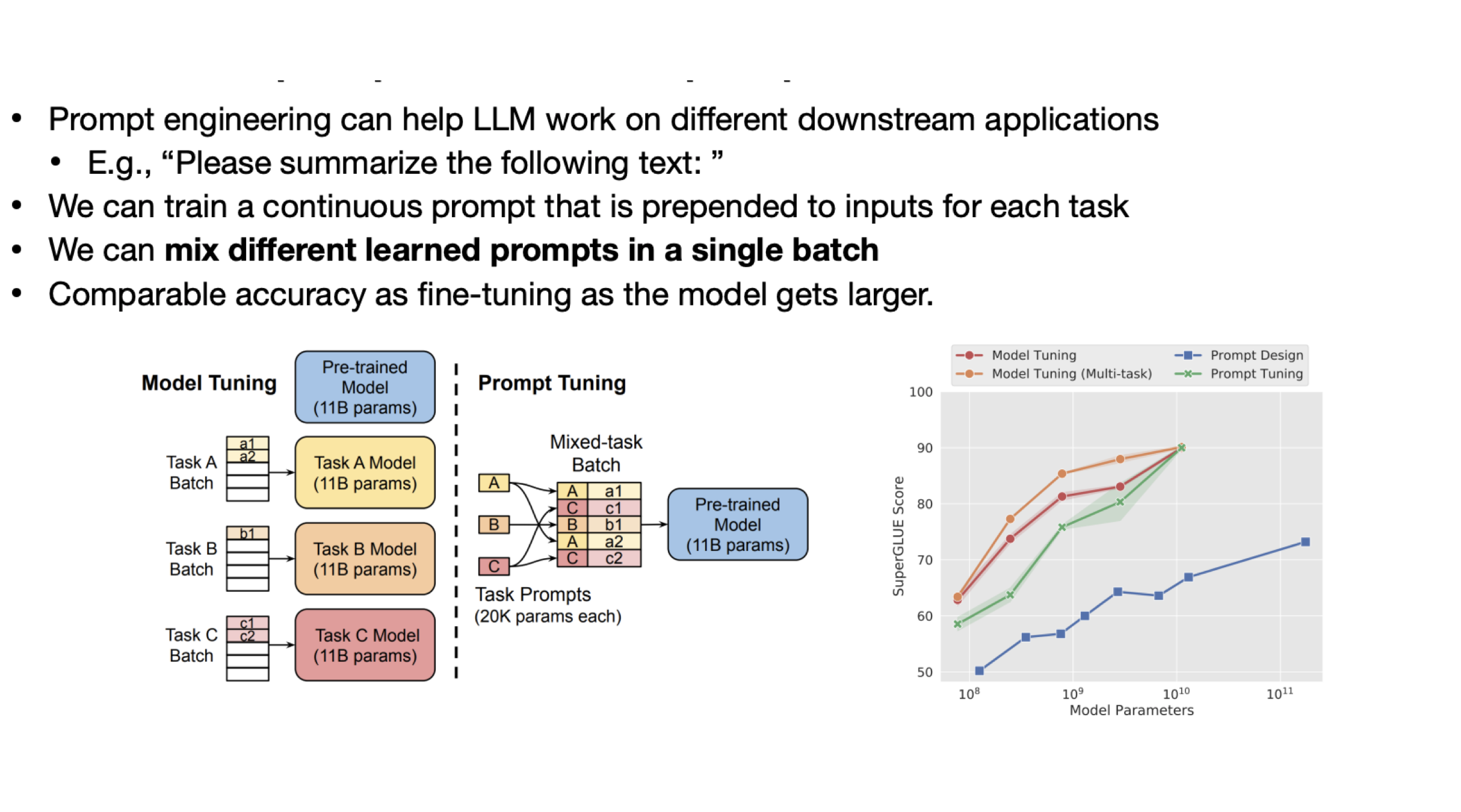 위의 방법들과는 다르게, tuning없이 prompt만 입력해서 특정한 task에 대한 성능을 높이는 방법이다. 예를 들어, “뒤에 문장을 요약해줘 :” 라는 문장을 입력에 추가하면 요약 task에 대한 성능이 올라간다. 이를 활요하면, 하나의 모델로 여러가지 task에 대응할 수 있게 되며, 모델이 커질수록 해당 task에 대해서만 fine-tuning한 모델이랑 비슷한 성능을 내게 된다.
위의 방법들과는 다르게, tuning없이 prompt만 입력해서 특정한 task에 대한 성능을 높이는 방법이다. 예를 들어, “뒤에 문장을 요약해줘 :” 라는 문장을 입력에 추가하면 요약 task에 대한 성능이 올라간다. 이를 활요하면, 하나의 모델로 여러가지 task에 대응할 수 있게 되며, 모델이 커질수록 해당 task에 대해서만 fine-tuning한 모델이랑 비슷한 성능을 내게 된다.