🧑🏫 Lecture 17-18
이번 강의는 분산 학습(distributed training)에 대한 내용을 다룬다. LLM등 딥러닝 모델이 점점 복잡해지면서, 대규모 모델의 훈련은 단일 GPU로는 더 이상 충분하지 않고, 여러개의 GPU를 사용해야 가능하다. 이번 글에서는 딥러닝 모델의 훈련을 가속화하기 위한 다양한 분산 훈련 기법들을 다루고자 한다. 데이터 병렬화, 파이프라인 병렬화, 텐서 병렬화 등의 기법들을 통해 효율적인 분산 훈련을 실현하는 방법에 대해 살펴볼 것이다. 또한, 분산 훈련 뿐만 아니라 GPU간 통신의 병목 현상에 대한 대처법으로 가중치 압축(gradient compression) 및 지연 가중치 업데이트(delayed gradient update) 또한 살펴볼 것이다.
1. Background and motivation
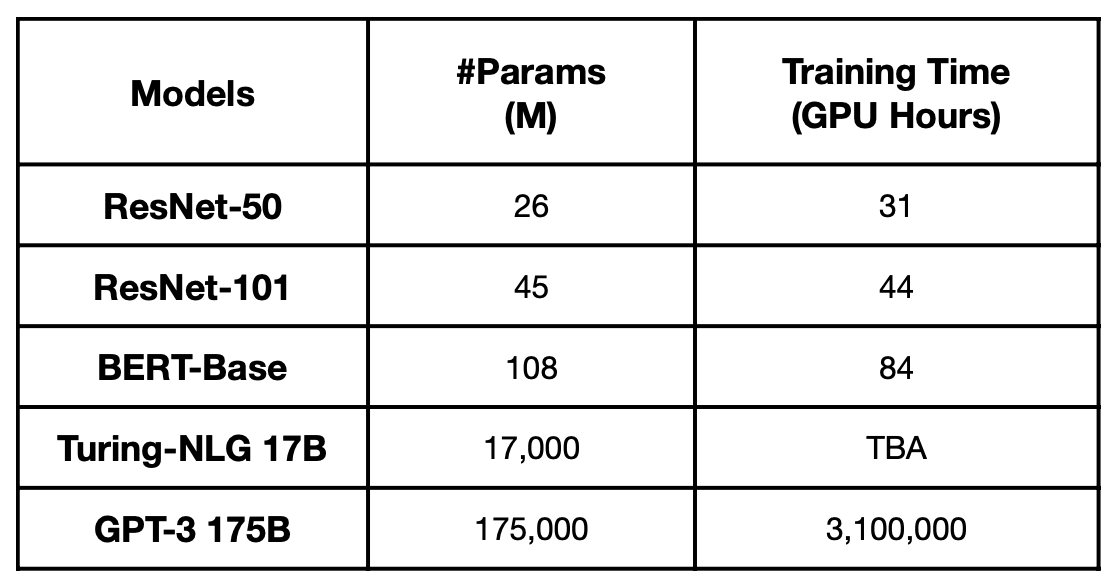
위 표는 Nvidia A100 기준으로 모델별로 훈련에 걸리는 시간이다. distributed training없이 단일 GPU로 학습한다면, GPT-3는 학습하는데 355년이나 걸린다.

위 농담처럼, 훈련에 너무 많은 시간이 걸린다면 모델을 발전시키기 어려울 것이다. distribution training을 사용하면, 이상적으로는 10일이 걸리는 작업을 1024개의 GPU로는 14분만에 학습이 가능하다.
2. Parallelization methods for distributed training
그렇다면 어떻게 병렬로 훈련시킬 수 있을까? 이번 장에서는 간단히 세 가지 방법을 소개하고, 각 방법에 대한 자세한 설명은 하나씩 다루도록 하겠다.
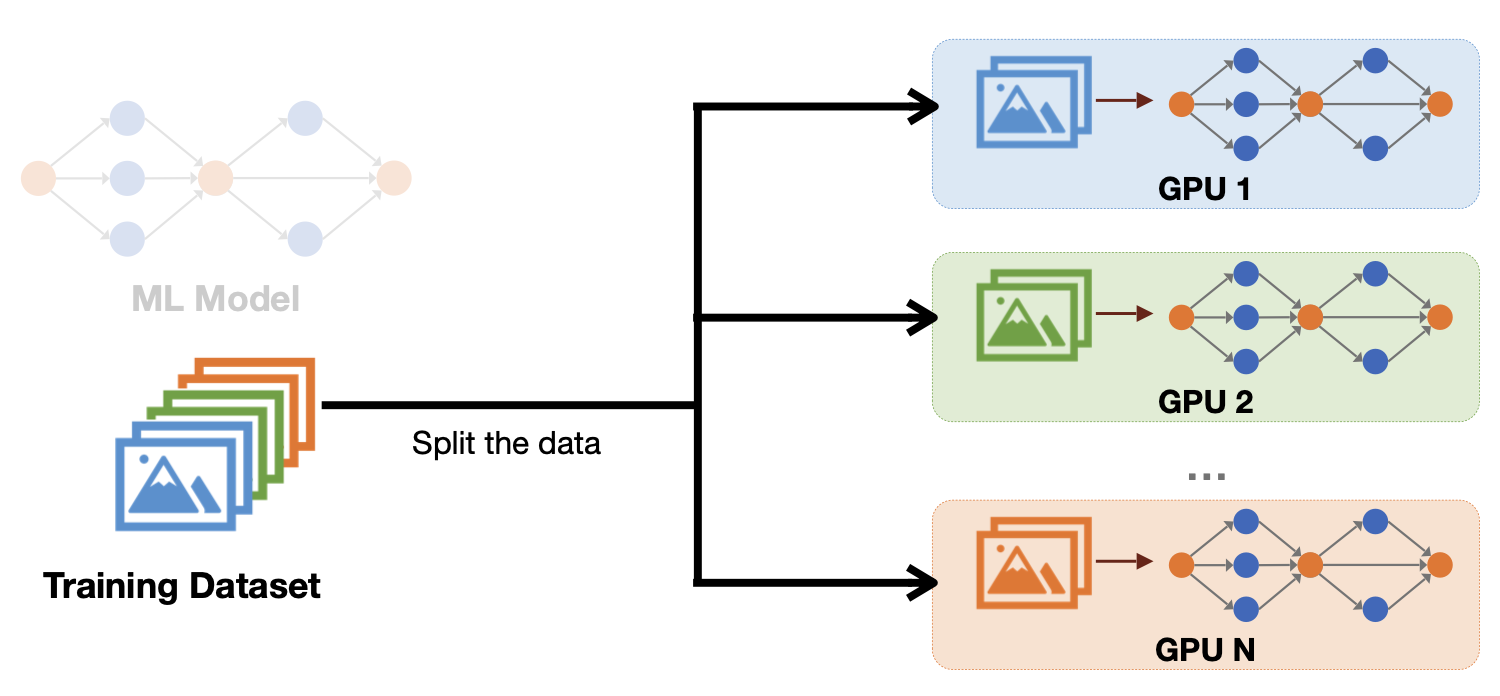
첫 번째는 data parallelism이다. 이 방법은 학습 데이터를 여러개의 GPU에 나눠서 학습한 뒤, 계산된 각각의 gradient를 다시 중앙에서 합치는 방식이다.
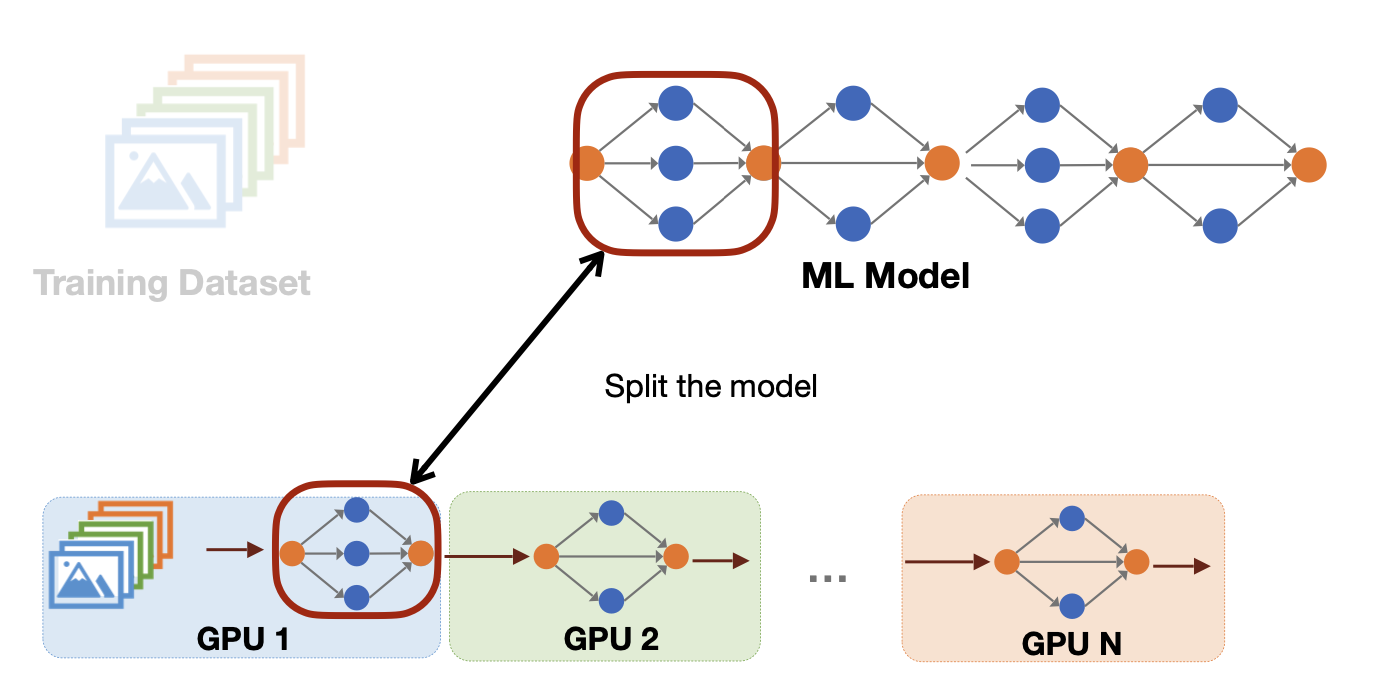
두 번째는 pipeline parallelism이다. 이 방법은 모델을 layer 별로 나눠서 할당하는 것이다. GPU별로 layer를 나눠 계산하는 것인데, 하나의 GPU에 모델의 모든 가중치를 넣기엔 너무 클 때 사용한다.
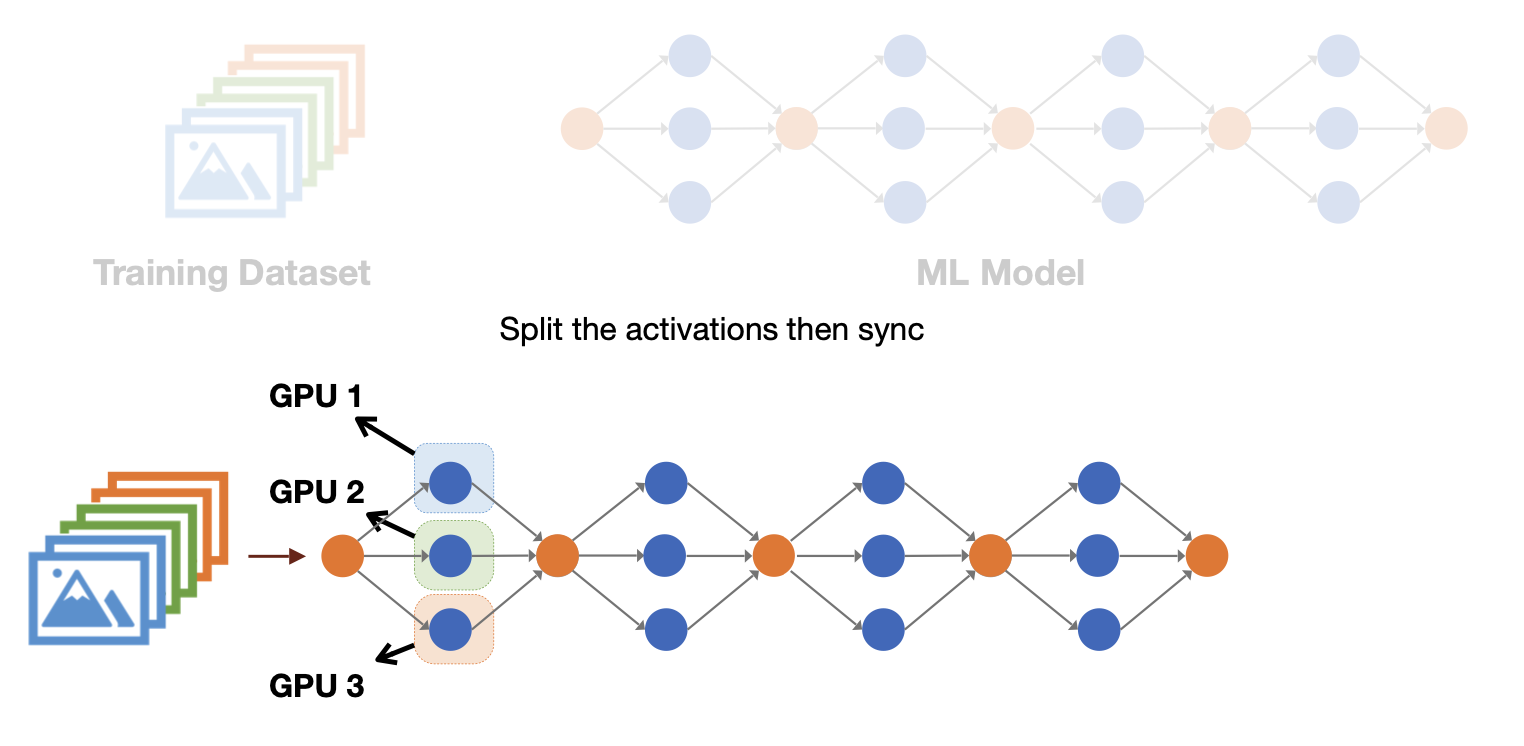
마지막으로 tensor parallelism이다. 이는 layer보다 더 잘게, 텐서 단위로 쪼개는 것이다. 직관적으로 보면 모델을 세로로 쪼개서 서로 다른 GPU에 할당하는 것인데, 자세한 설명은 뒤에 다시 다루겠다
3. Data parallelism
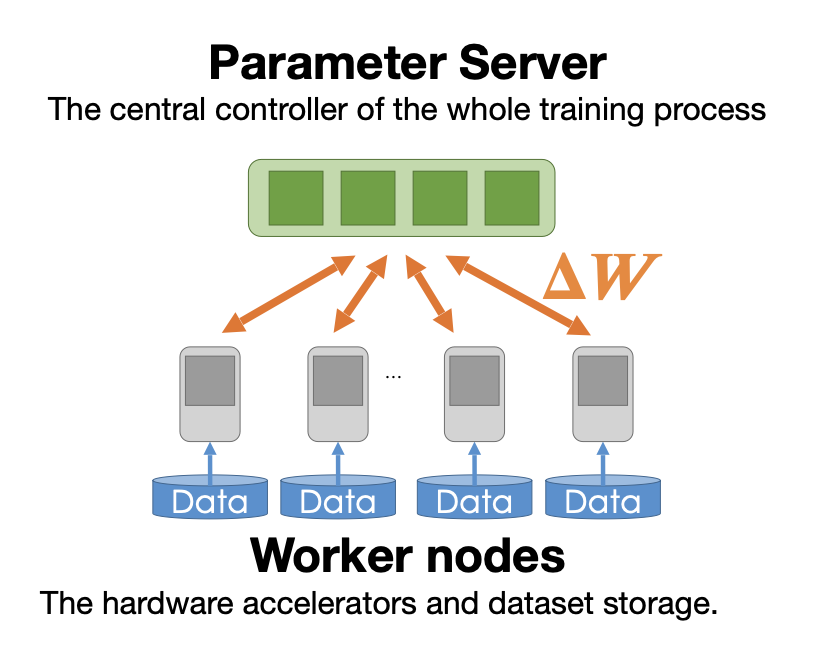
data parallelism을 할 떄에는 parameter server와 worker nodes라는 두 가지 요소가 존재한다. worker nodes는 분할된 데이터로 학습을 진행하고, parameter server는 worker로부터 전달받은 gradient를 합친다.
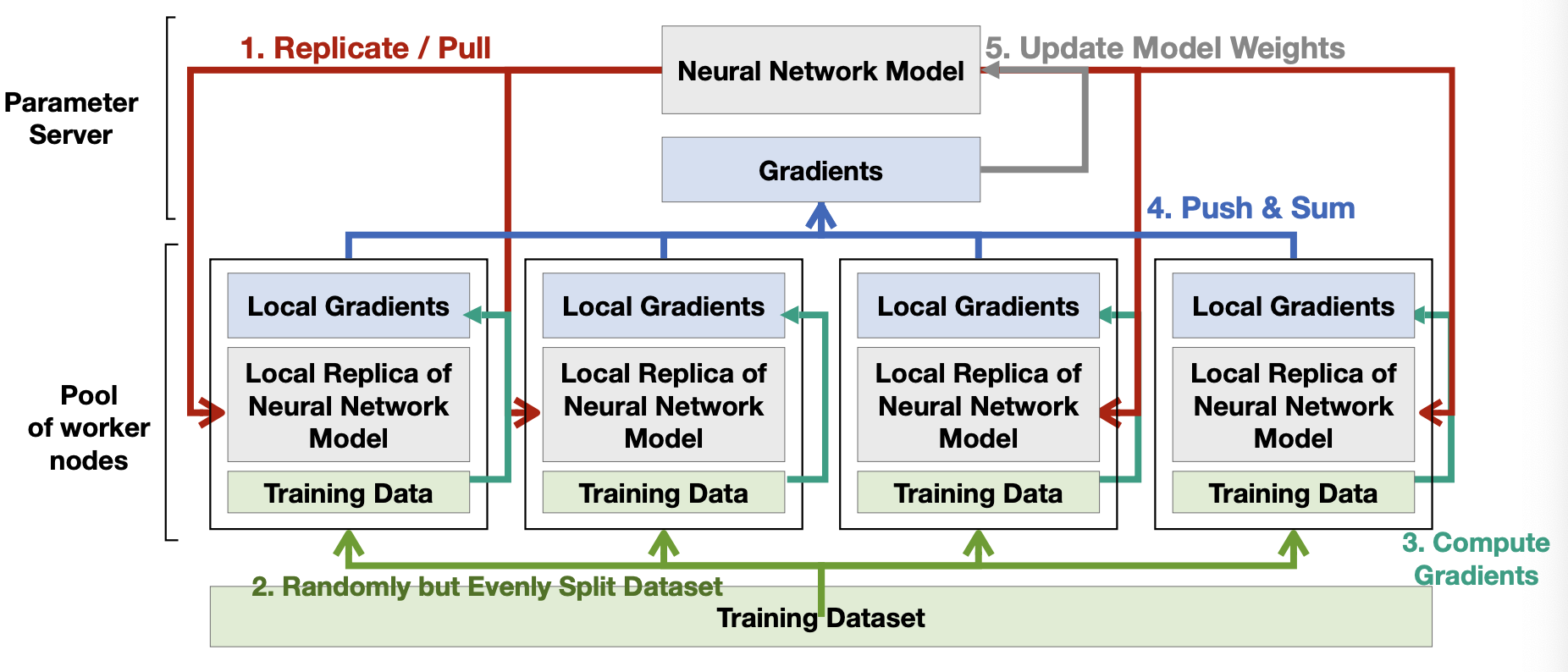
순서를 살펴보면
- parameter server에서 worker로 모델 가중치를 복사
- 학습 데이터셋을 worker에 적절히 배분
- worker에서 gradient 계산
- gradient를 parameter server에 전달
- parameter server에서 자체적으로 모델을 업데이트
4. Communication primitives
그런데, data parallelism에서 paramter server와 worker간의 통신은 어떻게 이루어질까?
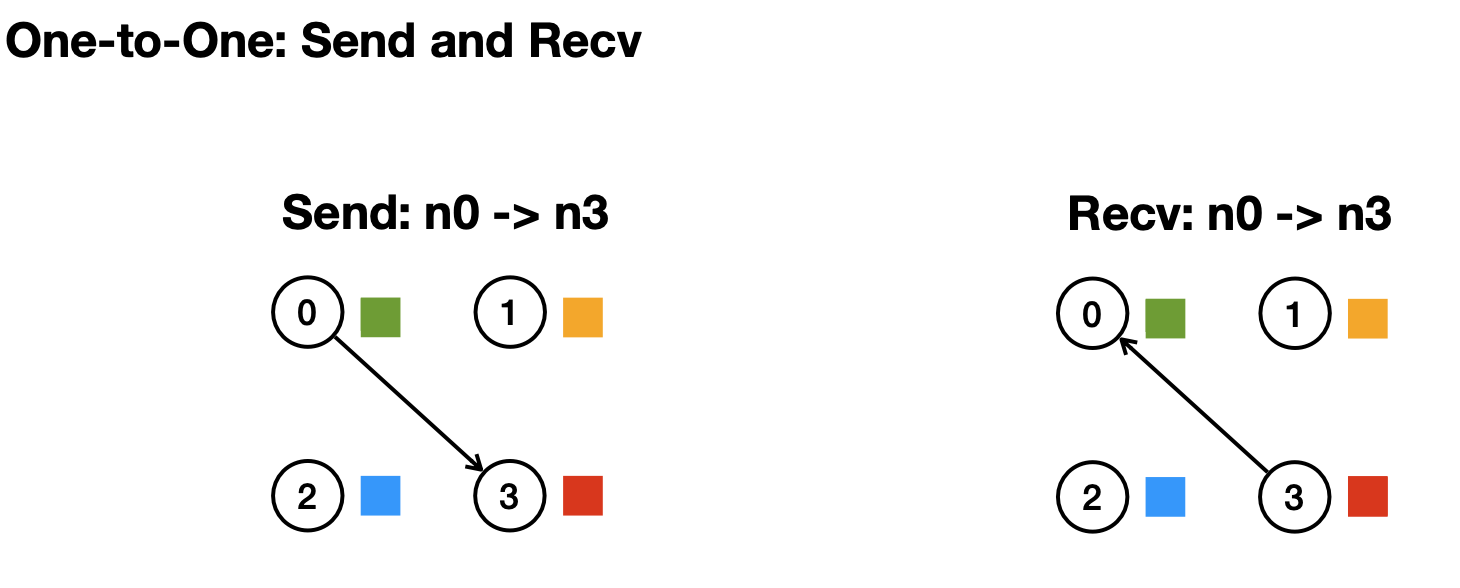
가장 단순한 방식은 소켓 통신같은 1:1 방식이다.
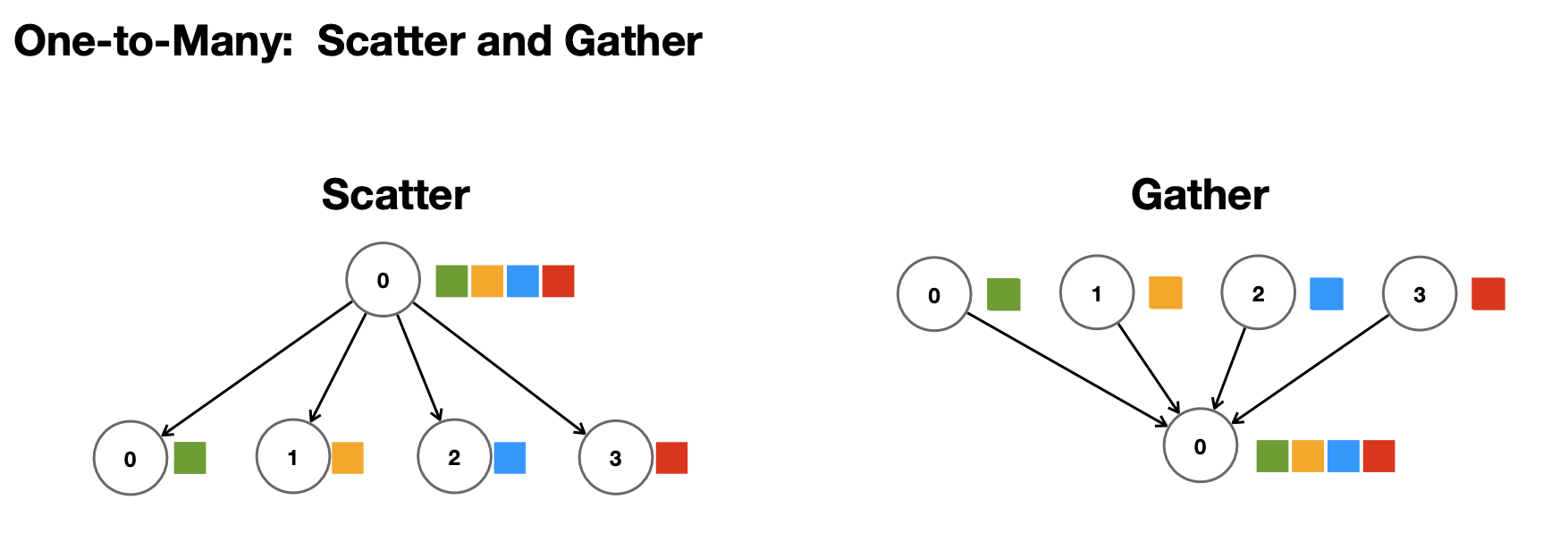
다른 방식으로는 일대다 방식이 있다. 한 노드로부터 정보를 분산하고, 합치는 것이다.
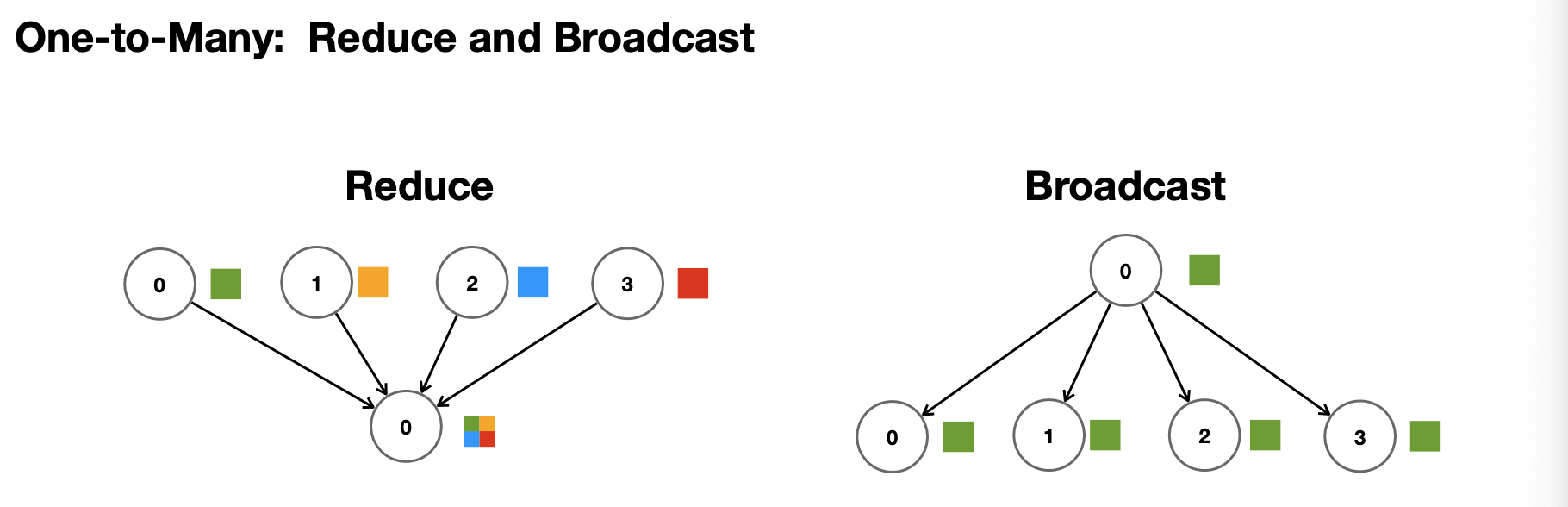
일대다 방식에서 조금 변형하면, reduce 방식이 된다. reduce 방식은 gather과 비슷하지만, 정보를 단순히 모으는 것이 아니라 합치거나 평균을 내는 것으로(빨파노초의 합)하나의 값을 만들어내고, 그런 뒤 broadcast를 통해 값을 모든 node로 송신한다
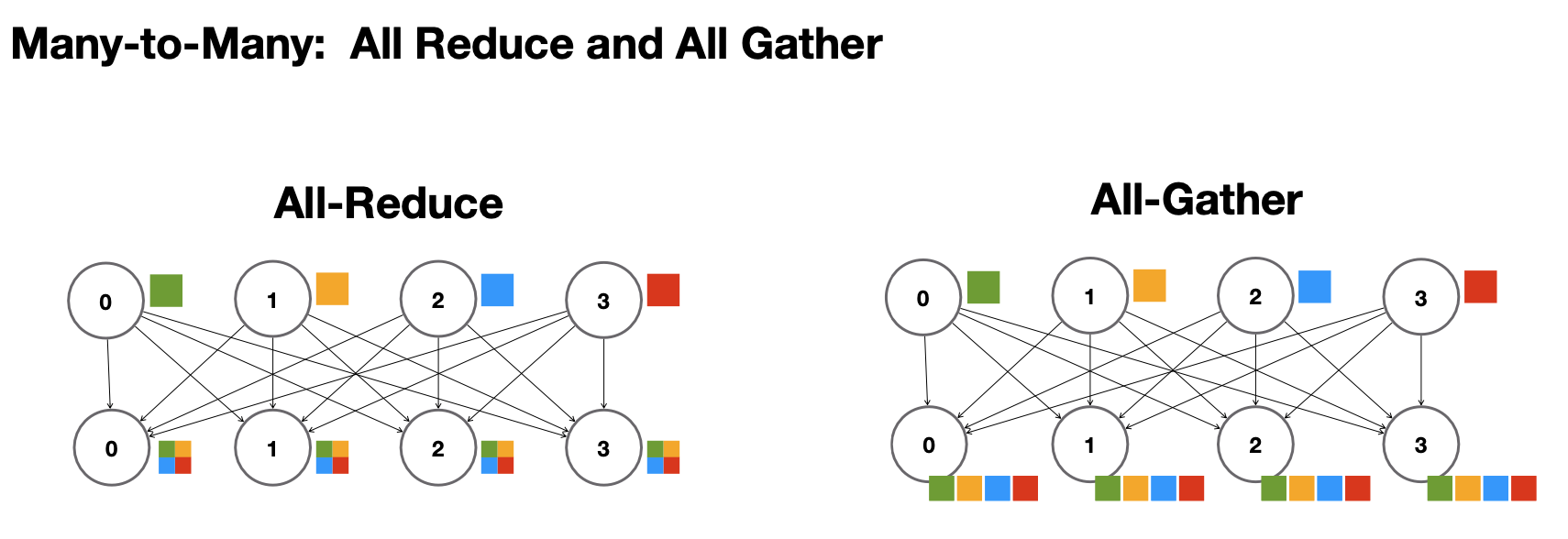 그 다음은, 다대다 방식이다. all-reduce는 모든 노드에 대해 reduce를 진행하는 것이고, all-gather을 통해 합치거나 하는 것이 아니라 모든 정보를 다 갖게 된다.
그 다음은, 다대다 방식이다. all-reduce는 모든 노드에 대해 reduce를 진행하는 것이고, all-gather을 통해 합치거나 하는 것이 아니라 모든 정보를 다 갖게 된다.
 우리가 이전 장에서 살펴본 data parallelism 방식의 복잡도를 구해보면, O(N)의 복잡도를가지고 이는 꽤 부담되는 정도이다. 이를 해결하기 위해 all reduce라는 방식을 사용한다.
우리가 이전 장에서 살펴본 data parallelism 방식의 복잡도를 구해보면, O(N)의 복잡도를가지고 이는 꽤 부담되는 정도이다. 이를 해결하기 위해 all reduce라는 방식을 사용한다.
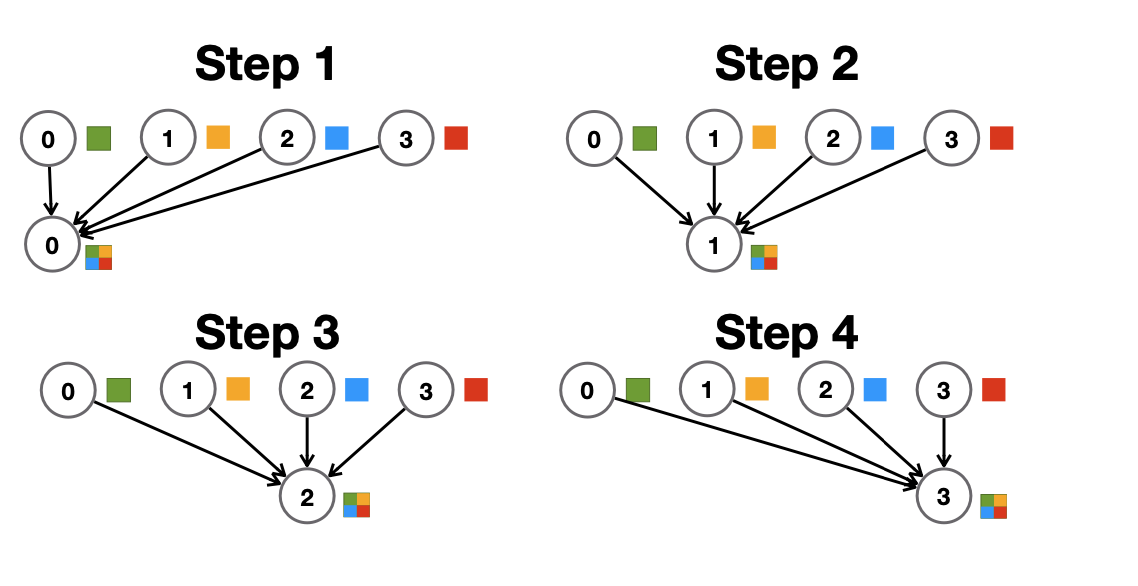 가장 간단한 방식은, sequential로 하나씩 reduce하는 방식이다. 이 방식은 시간과 bandwith 측면에서 모두 O(N)의 복잡도를 가진다.
가장 간단한 방식은, sequential로 하나씩 reduce하는 방식이다. 이 방식은 시간과 bandwith 측면에서 모두 O(N)의 복잡도를 가진다.
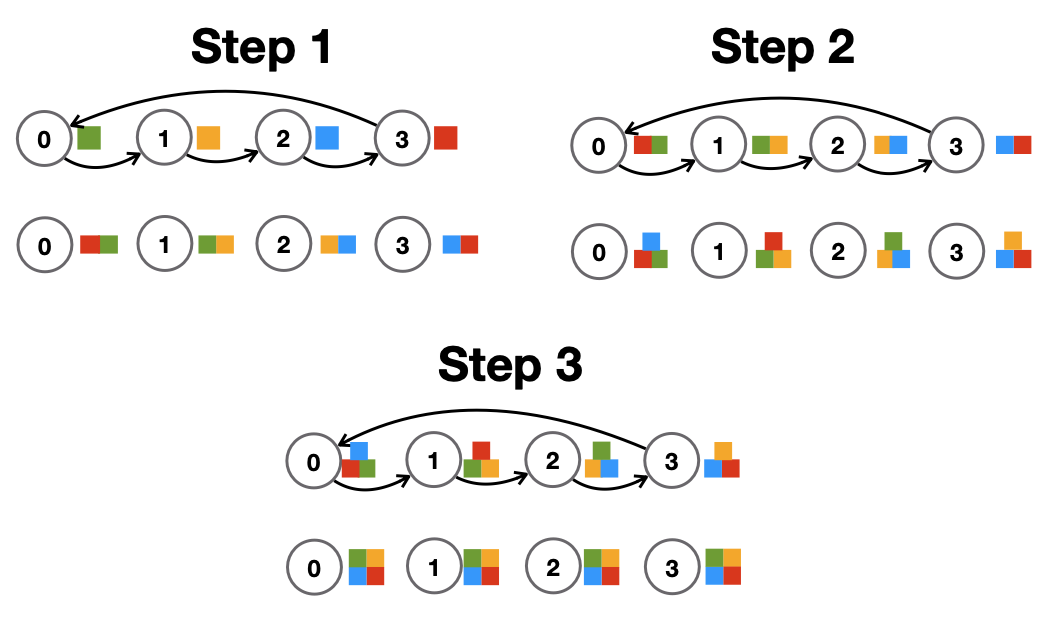 Ring 방식처럼 옆의 노드로만 전송하게 된다면, 시간은 그대로 O(N)이지만, bandwith는 O(1)의 복잡도를 갖게 된다.
Ring 방식처럼 옆의 노드로만 전송하게 된다면, 시간은 그대로 O(N)이지만, bandwith는 O(1)의 복잡도를 갖게 된다.
 종합해보면 위 표와 같다. 어떤 방식도 O(N)을 요구하는데, 어떤 식으로 더 줄일 수 있을까?
종합해보면 위 표와 같다. 어떤 방식도 O(N)을 요구하는데, 어떤 식으로 더 줄일 수 있을까?
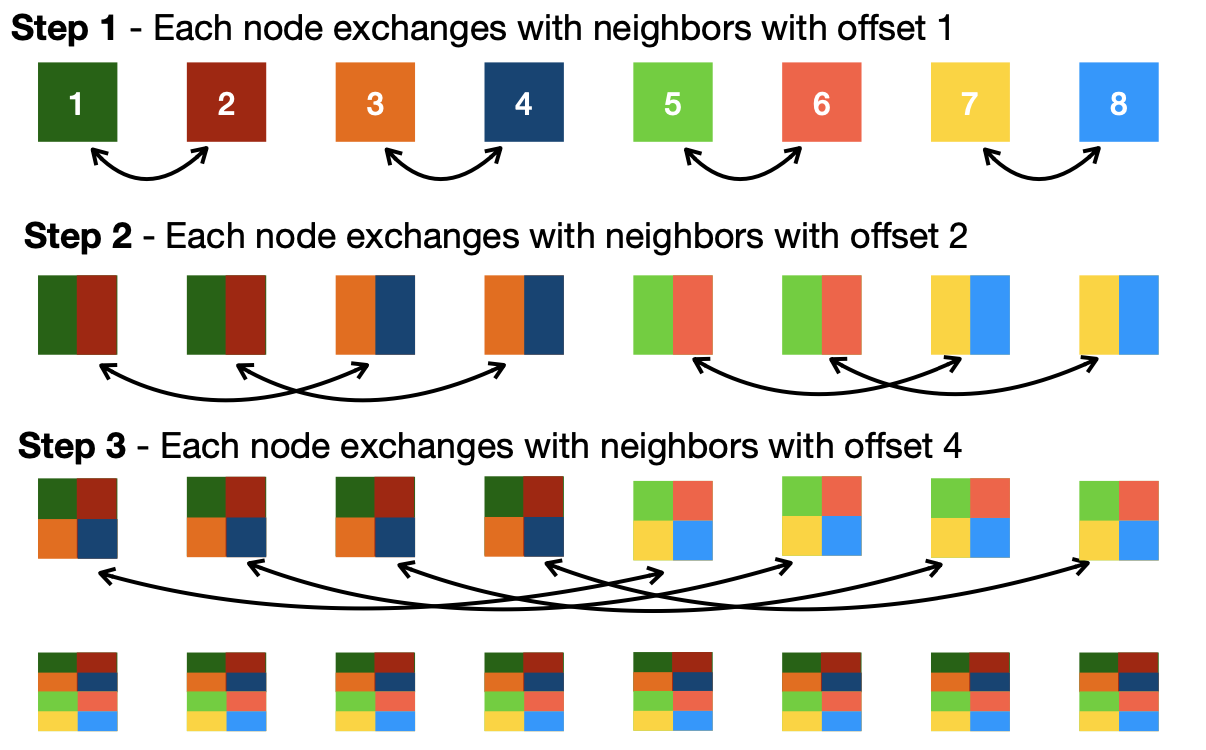 recursive all reduce 방식이 그 해법이다. 옆에 있는 노드끼리 정보를 교환하는 방식으로, log(N)으로 해결 가능하다.
recursive all reduce 방식이 그 해법이다. 옆에 있는 노드끼리 정보를 교환하는 방식으로, log(N)으로 해결 가능하다.
5. Reducing memory in data parallelism: ZeRO-1 / 2 / 3 and FSDP
data parallelism에서 메모리를 더 줄이는 ZeRO 시리즈 방법을 소개한다.
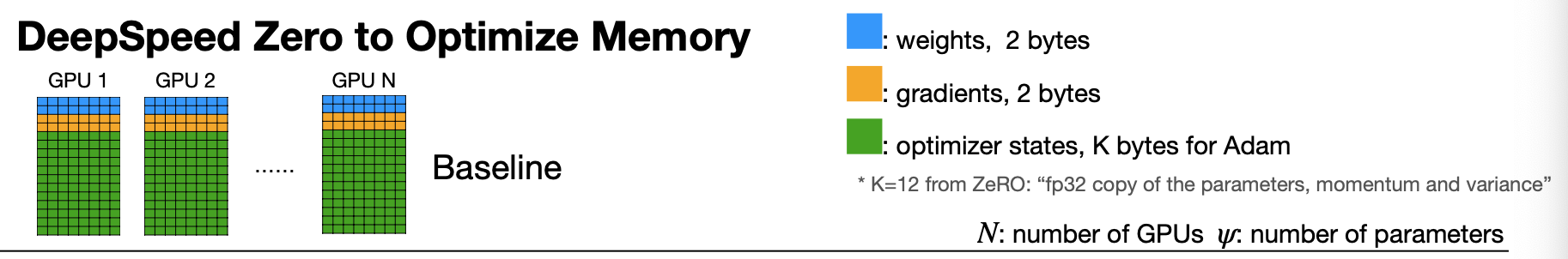
학습을 할때 weight와 gradient 이외에도 adam등의 optimizer를 사용하면 optimizer state(momentum, variance값, master copy)를 저장해야 한다. 그렇다면 하나의 파라미터에 16byte가 필요하게 된다(fp16기준, weight=2, gradient=2, optim state=12(4*3)) 위 그림처럼 많은 메모리가 optimizer state를 저장하기 위해 사용되게 된다.
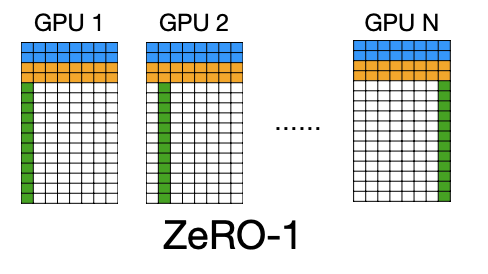
그래서 고안할 수 있는 방법이 optimizer state를 sharding(분산저장)하는 방식이다. 이러면 해당하는 구간에 대한 weight밖에 업데이트를 하지 못하게 되지만, 메모리 사용량은 줄어들게 된다.(12/N bytes for optim state)
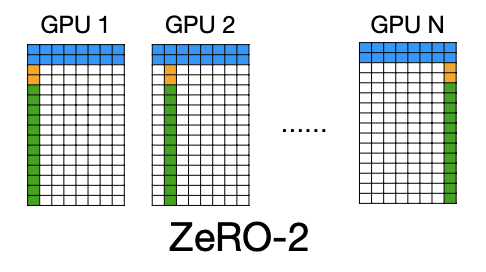
optimizer state뿐만 아니라, gradient도 sharding할 수 있다.(2/N bytes for gradient)
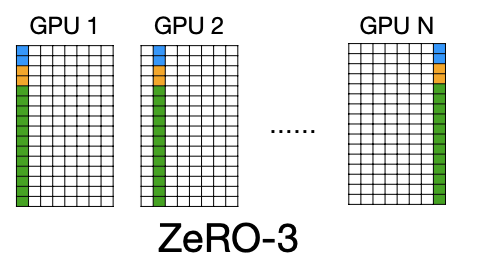
weight까지도 sharding할 수 있다. 하지만 gradient에 비해 이건 좀 어려운데, inference를 할 때 모든 weight가 필요하기 때문이다. 따라서 이 방식을 사용하면, inference시에는 다른 GPU(node)로부터 weight값을 가져와서 진행하게 된다. (2/N bytes for weights)
6. Pipeline parallelism
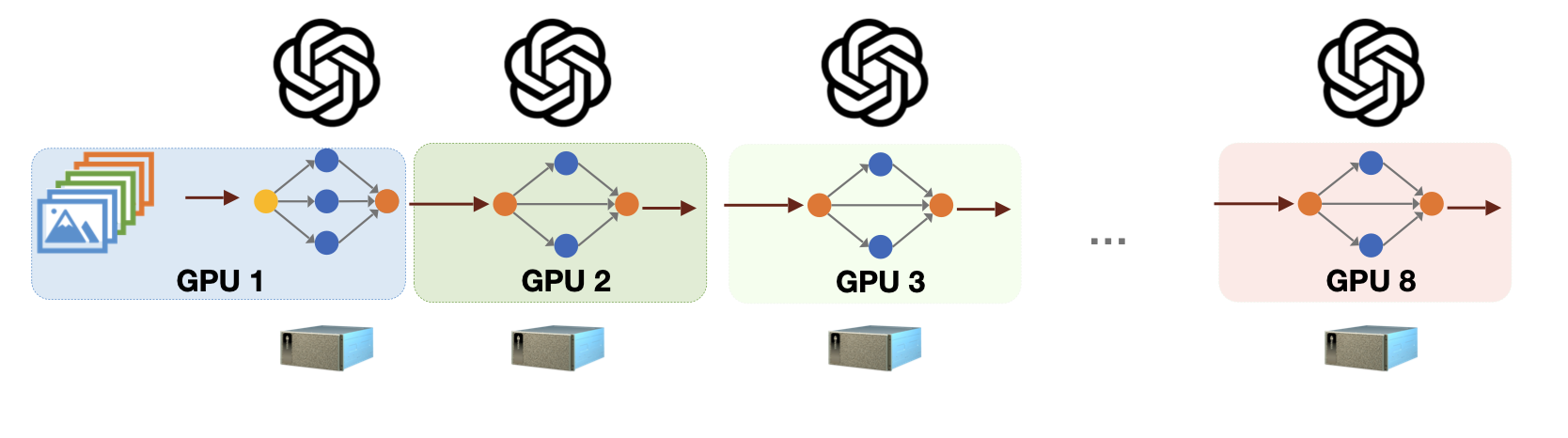
data parallelism과 달리 pipeline parallelism은, 모델을 분할하는 방식이다.
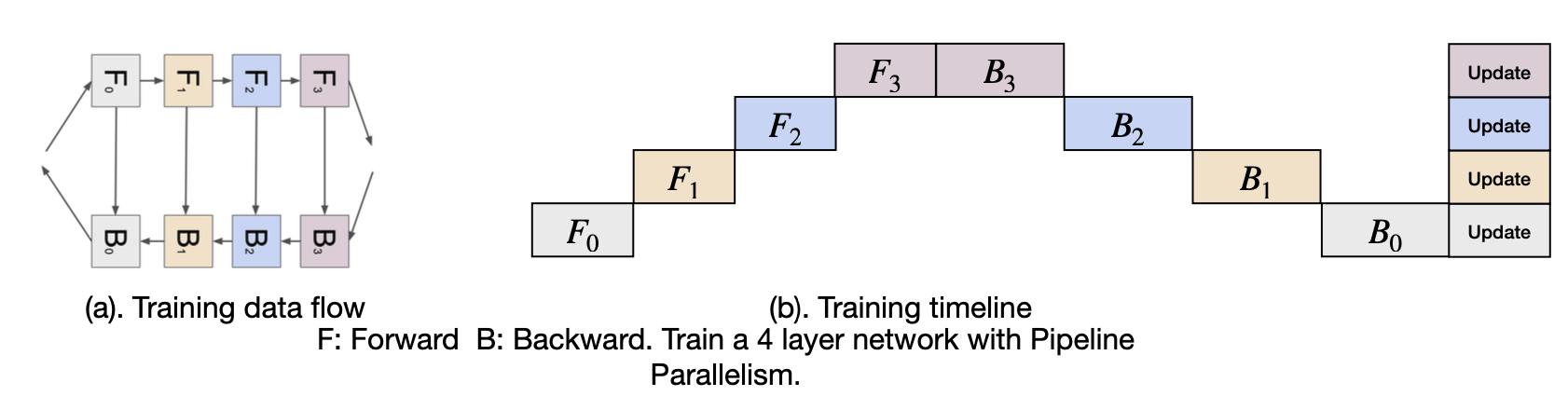
간단하게 구현을 생각해보면, forward-backward에 대해 위와 같이 일자적인 구조로 구현할 수 있다. 하지만, 이런 방식이면 F0이후 한참 뒤에 B0이 이루어 지는 것처럼 비게되는 시간이 많아진다.
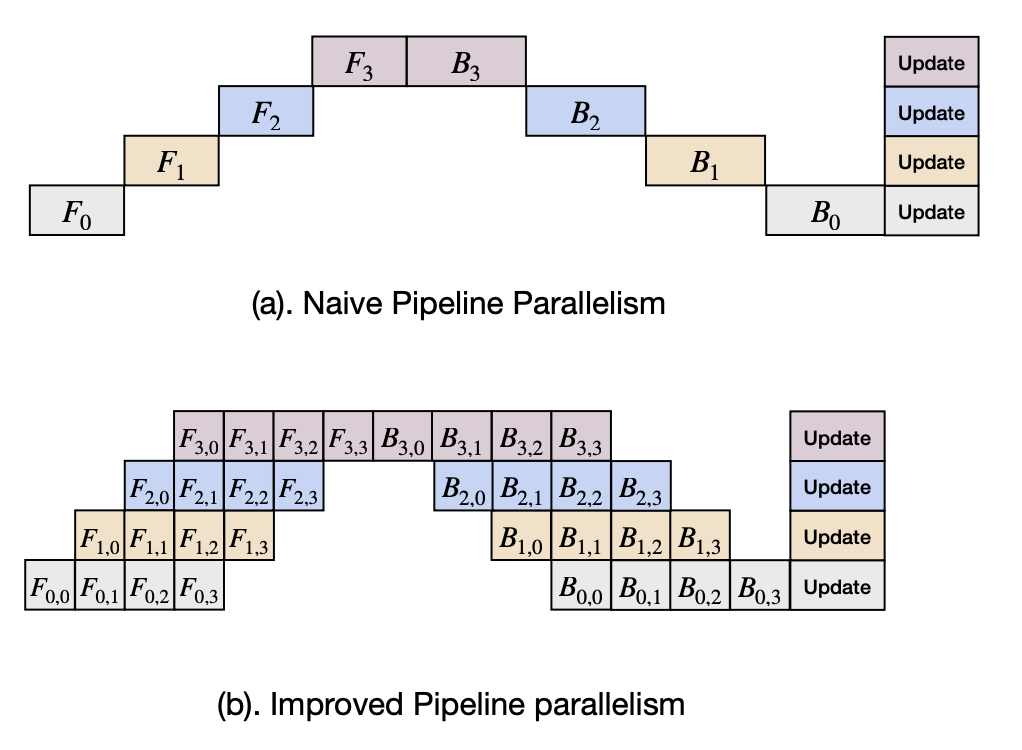
이를 해결하는 방법이 Gpipe에 제시된다. batch를 잘게 쪼개서 forward-backward간의 간격을 줄이는 방식이다. 이전의 naive한 방법에서 이 방법으로 바꿀 시 2.5배정도 utilization을 늘릴 수 있다.(25%->57%)
7. Tensor parallelism
하지만 57%의 utilization도 생각해봤을 때 너무 적게 활용되는 것 같기도 하다. 그렇다면 더 잘게 쪼개는 방식을 생각해볼 수 있을 것이다.
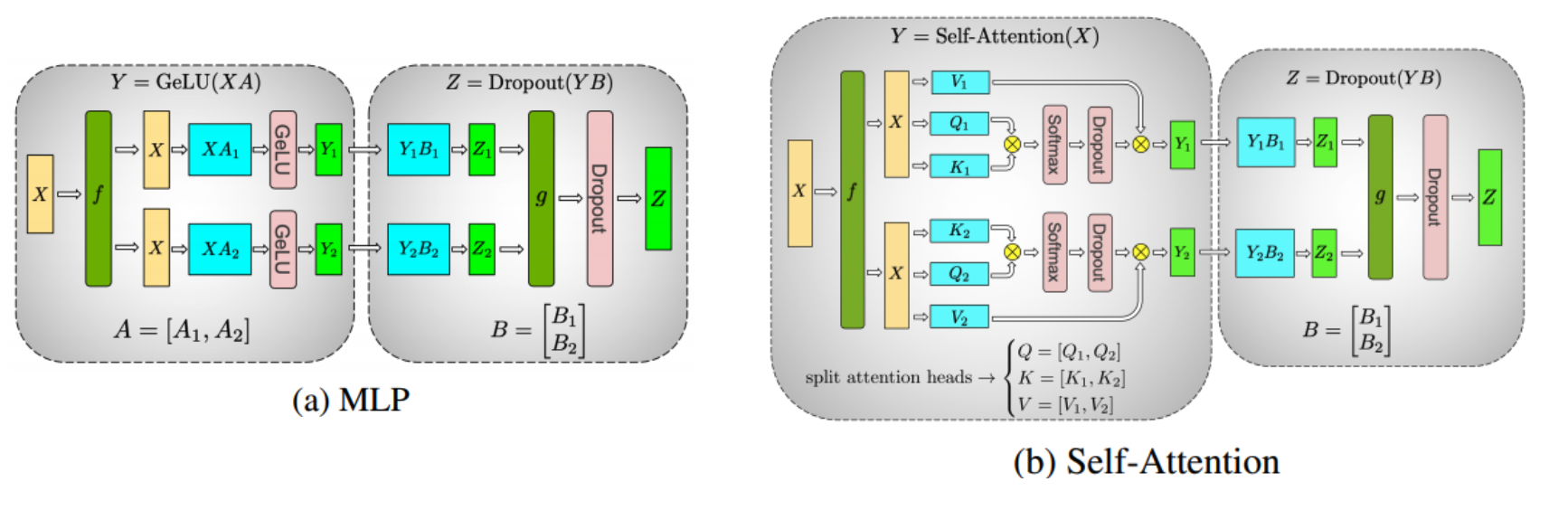
위 그림은 각각 MLP와 self-attention layer에서 tensor parallelism을 적용했을 떄의 구조이다. 녹색 f 를 통해 X를 N개(예시에서는 2개)의 chunk로 쪼개고, 각각의 X를 서로다른 GPU에서 연산을 진행한다.
8. Hybrid (mixed) parallelism and how to auto-parallelize
위에서 우리는 3가지 방법의 parallelism 방법을 살펴보았다. 이번 장에서는 이런 방법들을 조합해서 사용하는 방법에 대해 살펴본다.
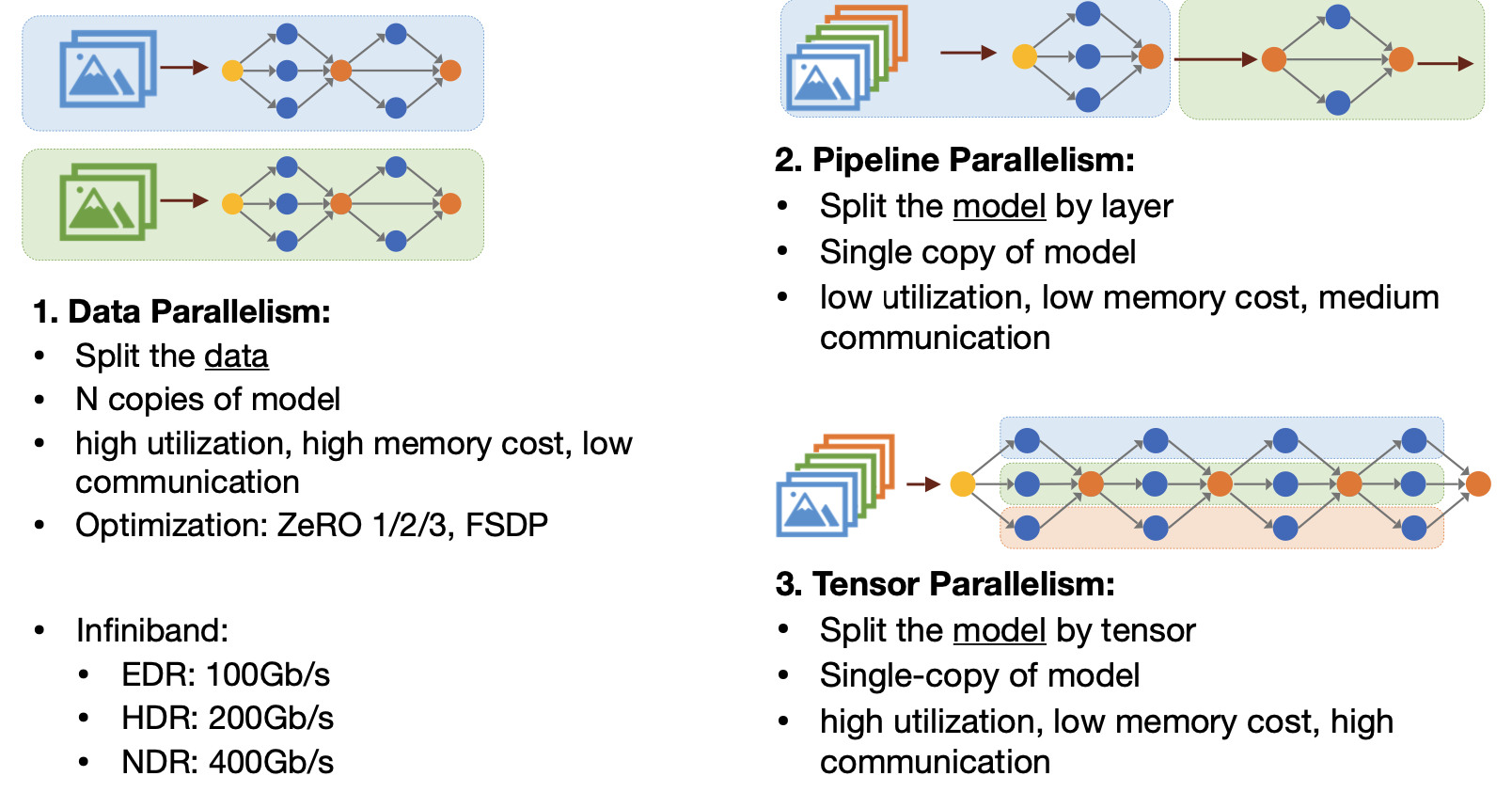
먼저 각 병렬화 방법을 다시 요약해보면, data parallelism은 데이터를 나누는 것이고, pipieline parallelism은 model을 layer단위로 나누는 것이며 tensor parallelism은 model을 tensor단위로 나누는 것이다.
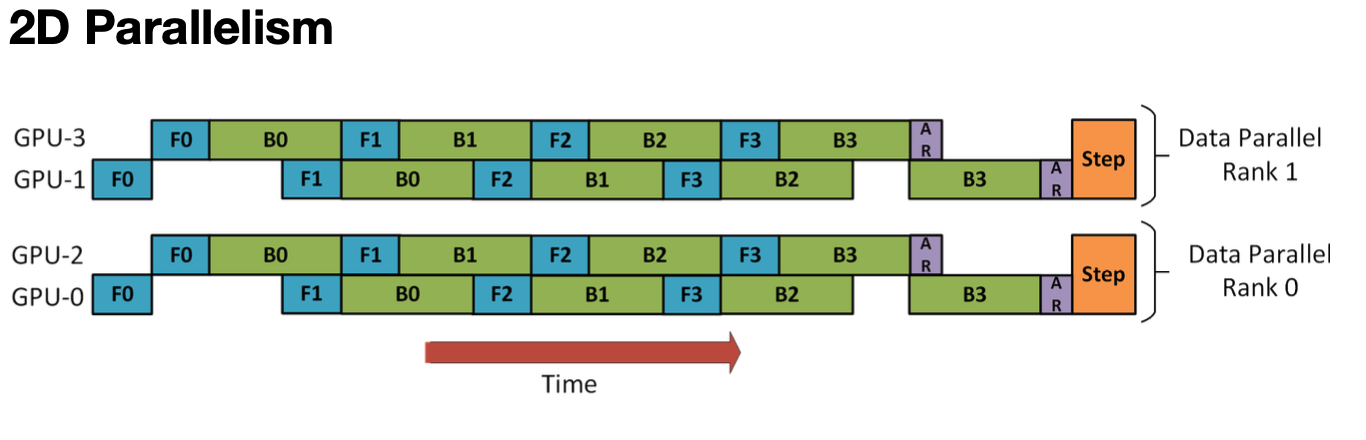
위 그림은 Data parallelism + Pipeline parallelism을 동시에 적용한 모습이다. 2개의 GPU단위로 data를 나누고, 2개 GPU간에 pipeline parallelism을 적용한다.
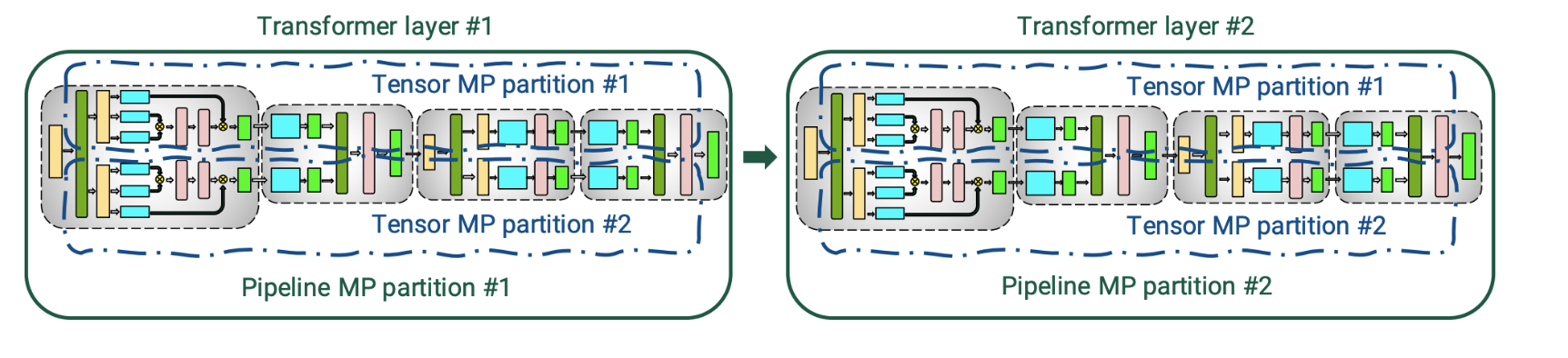
위 그림은 pipeline parallelism + tensor parallelism이다. 이렇듯 2개의 기법만을 사용하는 것이 아니라 3개의 병렬화 방법을 동시에 사용할 수도 있다(3d parallelism)
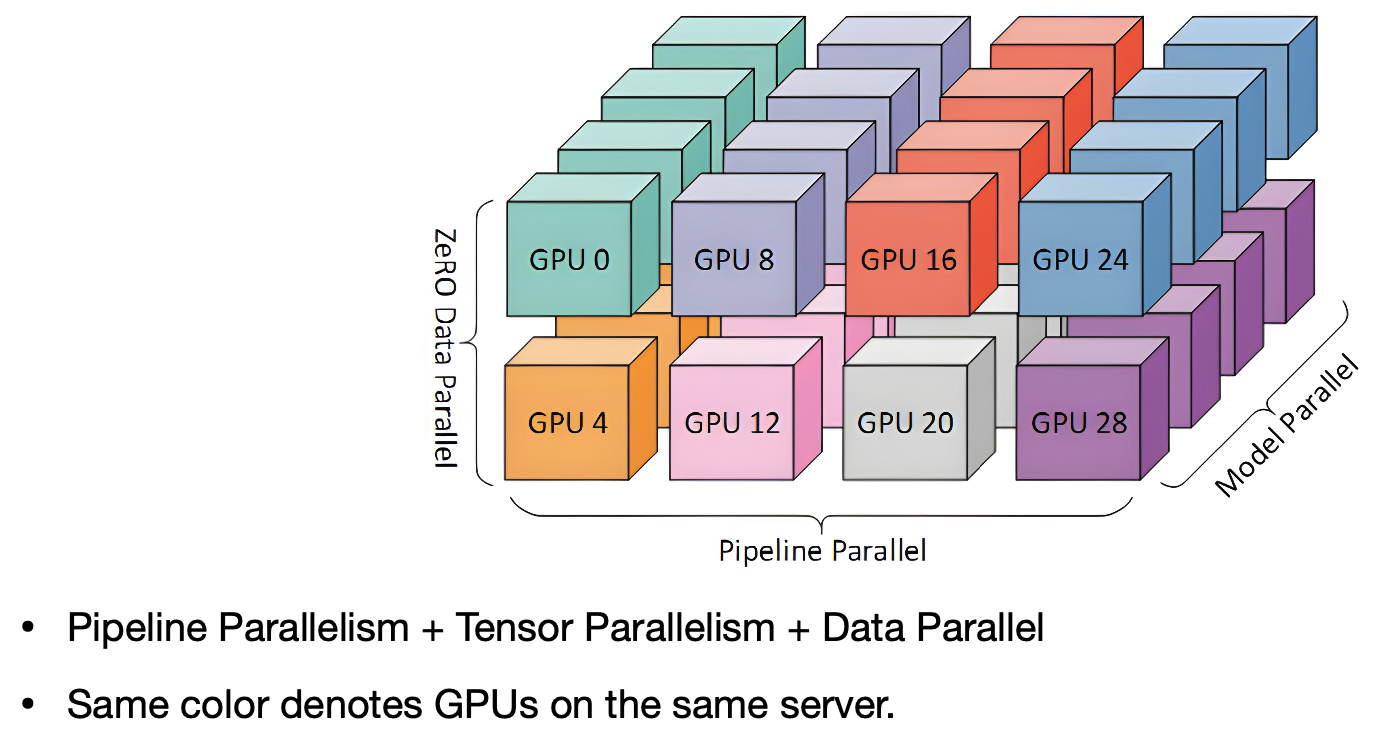
그림으로 표현하면 위와 같다.
생각해 볼 문제는, 이렇게 여러개의 병렬화 방식을 사용할 때, 어떤 식으로 사용해야 최적의 방식이 되느냐의 문제이다. 일반적으로는 모델이 GPU에서 돌아가지 않을 정도로 크다면 pipeline, layer가 GPU에서 돌아가지 않을 정도로 크다면 tensor 방식을 사용하지만 단순히 그런 방식을 적요하는 것이 최적의 방법은 아니다.
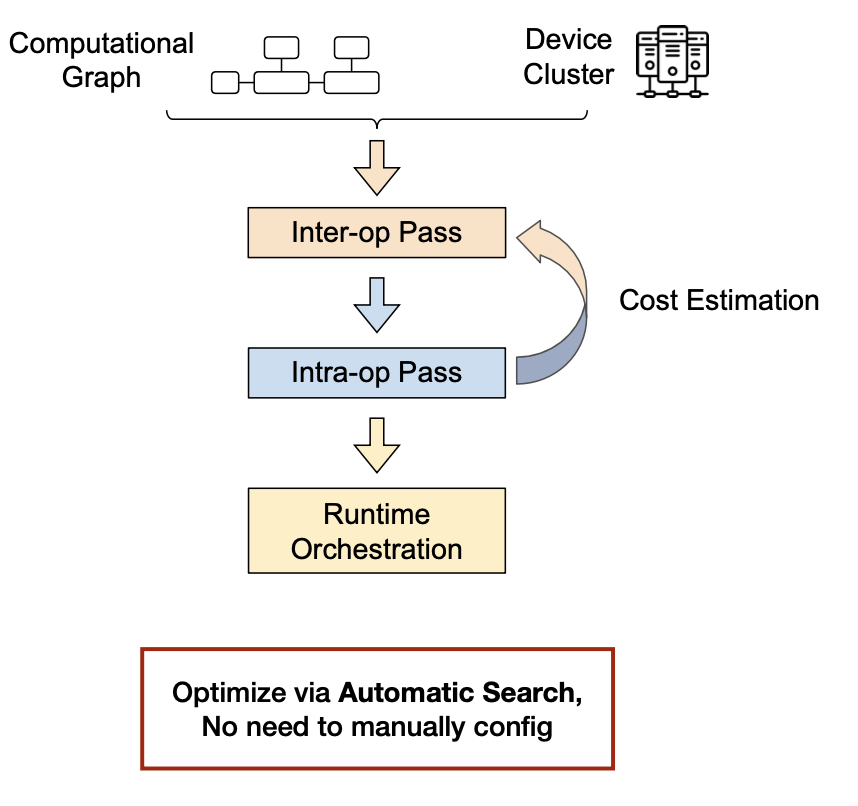
이를 NAS와 비슷한 방식으로 연산간의 관계를 설정하는 inter-op pass와 연산 내부의 동작을 설정하는 intra-op pass 두 단계를 통해 자동으로 찾아주는 방식이 존재한다.
9 Understand the bandwidth and latency bottleneck of distributed training
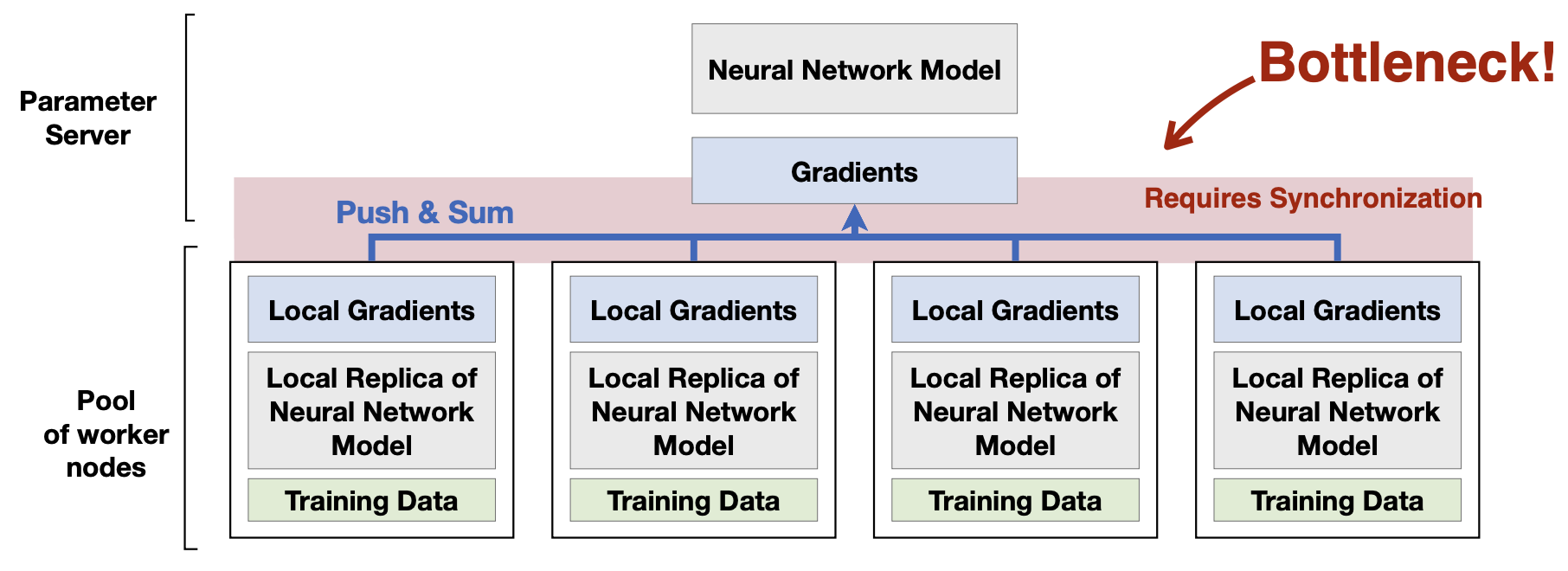 분산 학습 방식에는 반드시 따라오는 문제점이, communication에 따른 bottleneck이다. 모델이 커지면 더 여러곳에 분산해야 하고, 데이터 크기도 커지며, 전송 속도도 길어진다. 그렇게 되면 communication latency가 길어질 수 밖에 없다.
분산 학습 방식에는 반드시 따라오는 문제점이, communication에 따른 bottleneck이다. 모델이 커지면 더 여러곳에 분산해야 하고, 데이터 크기도 커지며, 전송 속도도 길어진다. 그렇게 되면 communication latency가 길어질 수 밖에 없다.
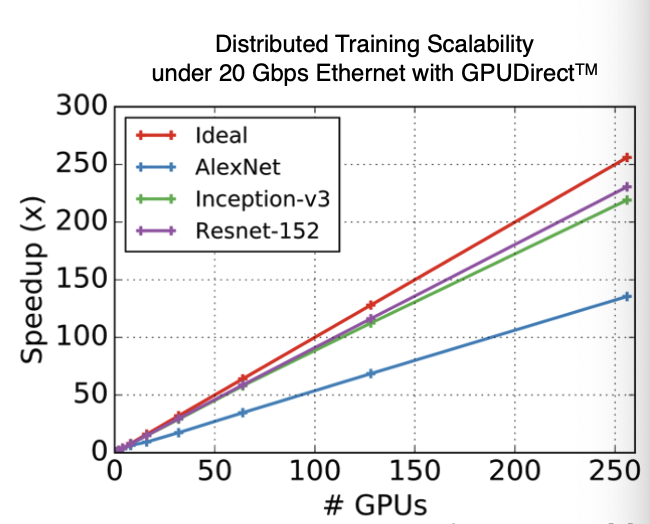
실제로, 분산 학습에서 GPU의 개수와 speed는 정확히 y=x의 그래프를 그리지 않는다. 이는 중간중간에 bottleneck으로 작용하는 부분이 있음을 보여준다.
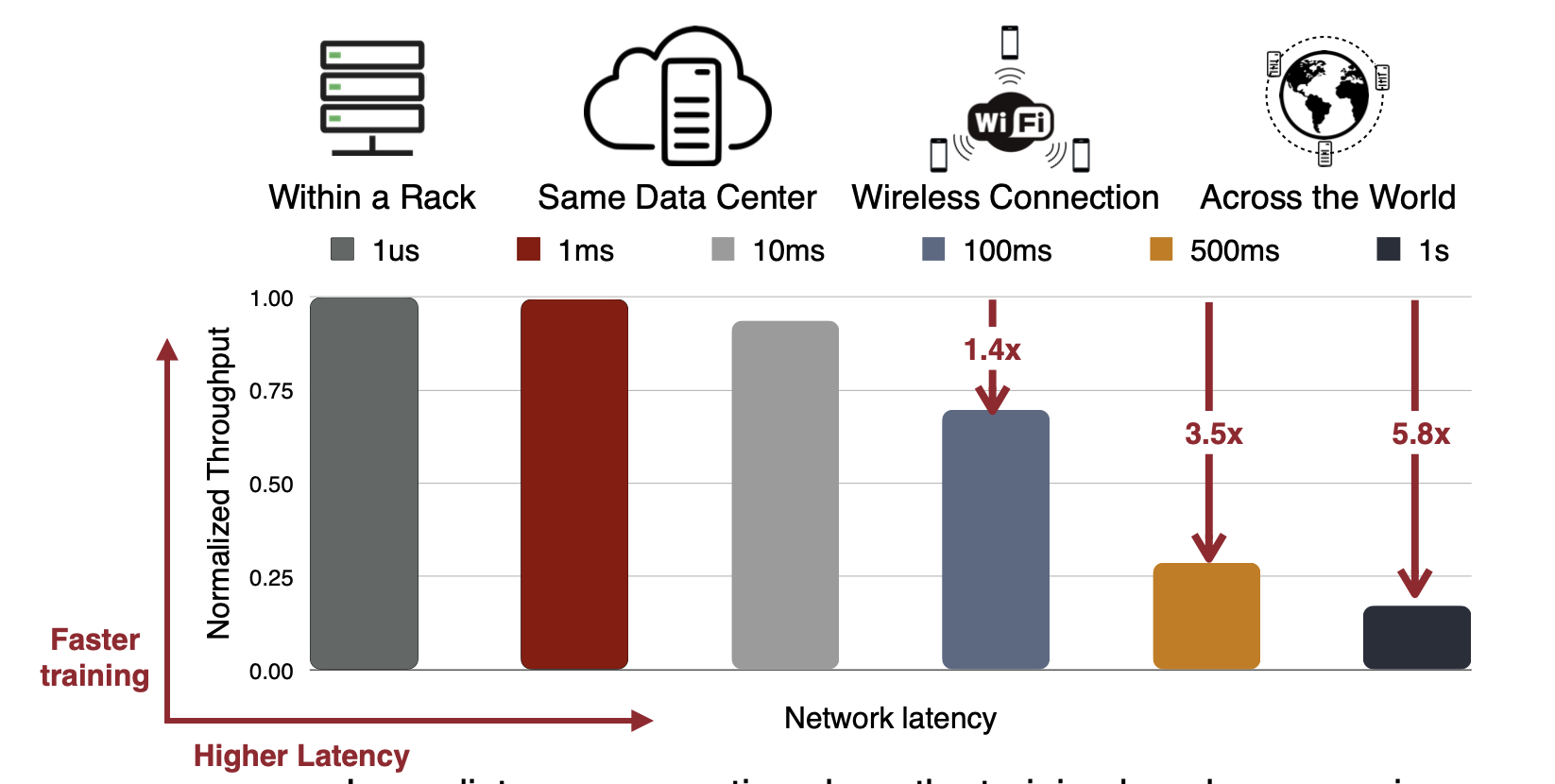
그리고 이 latency는 node간 거리가 멀수록 당연히 훨씬 늘어난다.
10. Gradient compression: overcome the bandwidth bottleneck
그렇다면 이런 data전송에서 bottleneck을 줄이려면 어떻게 해야 할까?
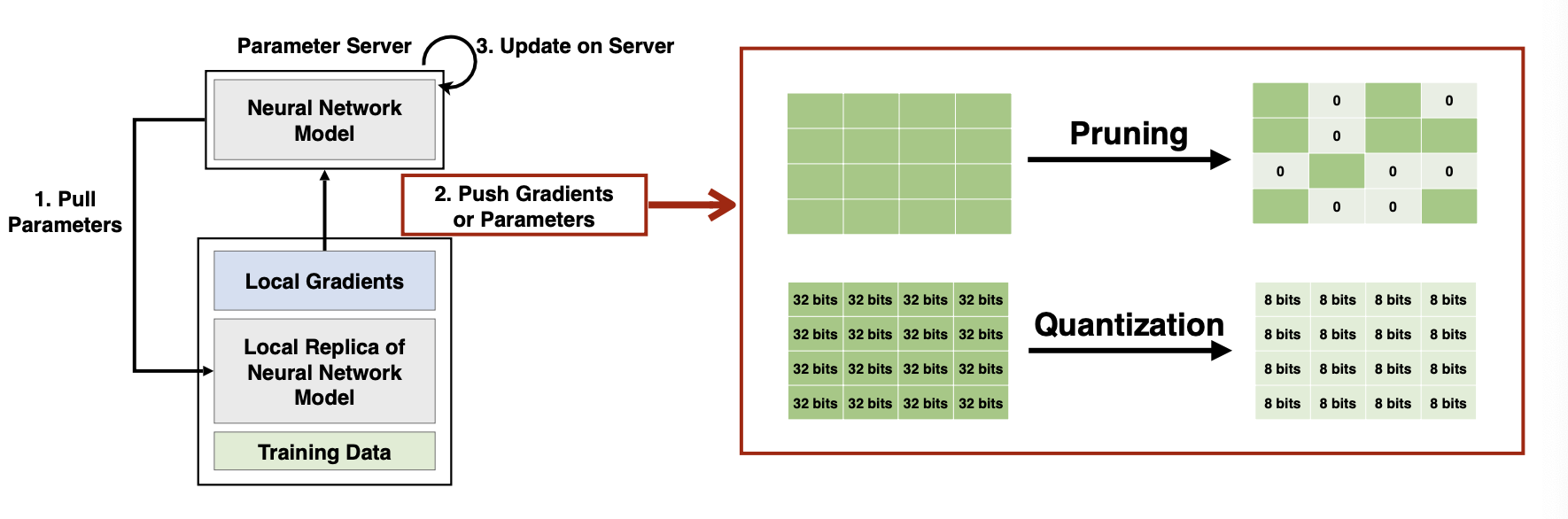
우리가 이전에 해왔던 pruning, quantization 방식을 똑같이 적용할 수 있다. pruning/quantization으로 데이터 크기를 줄인다면, 당연히 전송할 데이터 양도 줄어들고 bottleneck도 줄어든다.
10.1. Gradient Pruning: Sparse Communication, Deep Gradient Compression
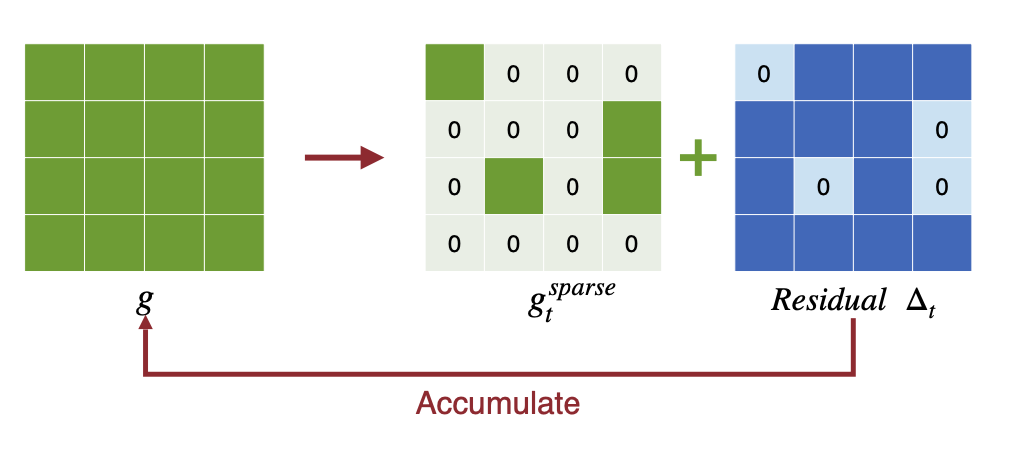
pruning 방식은 간단하게 gradient중에서 top-k개만 전송하는 방식이다. top-k의 기준은 단순히 magnitude를 사용한다. 전송되지 않은 gradient도 error feedback을 통해 local에 내비두어 사용한다.

하지만 이런 방식은 꽤나 성능 저하를 일으킨다. gradient만 사용하므로, momentum이 없기 떄문이다.
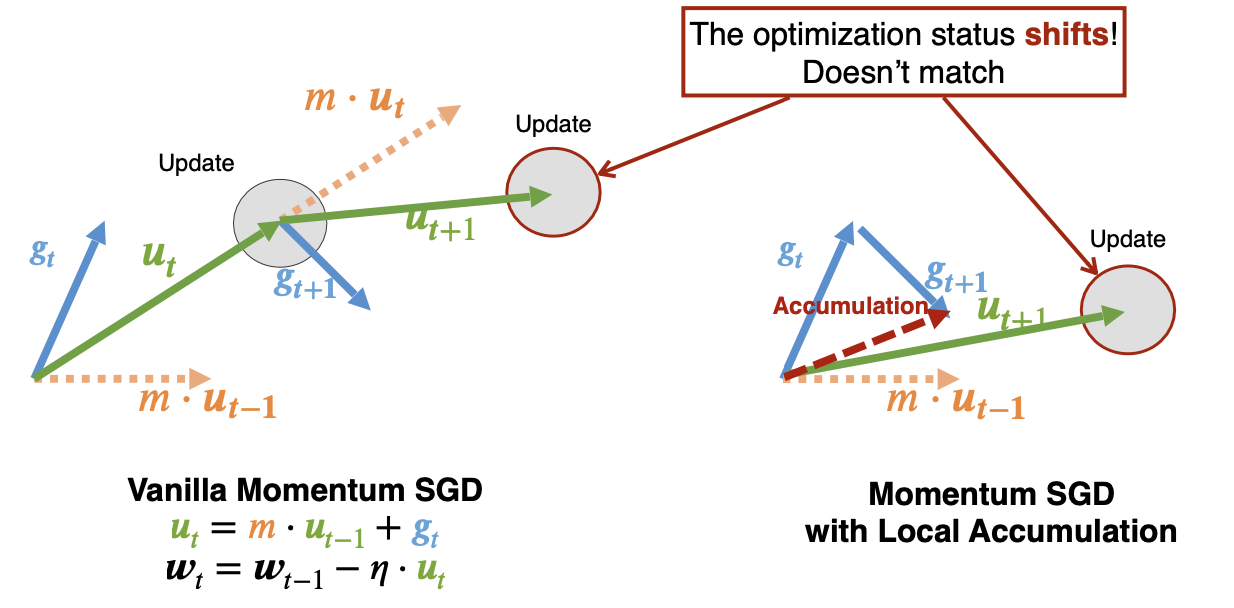
단순히 accumulate하면 위와 같이 momentum을 사용하는 방식과 꽤 달라지게 된다.
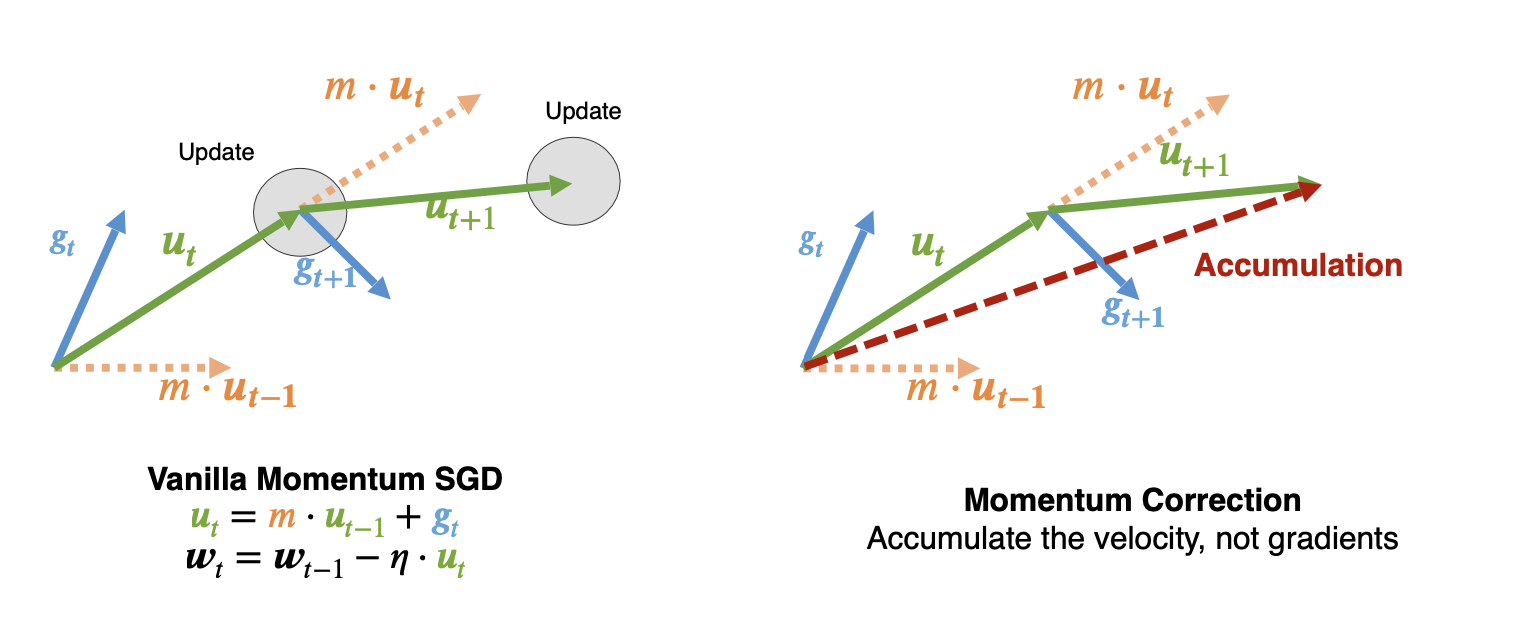
따라서 gradient가 아니라 velocity를 accumulate하는 것이 더 좋다. 또한 여러가지 warm up 방식을 사용하는 것이 좋다.
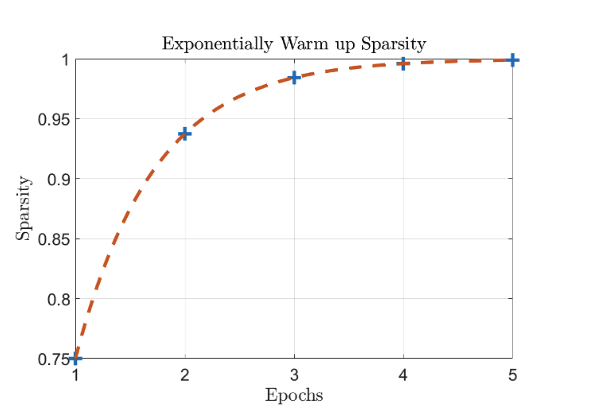
learning rate는 물론이고, pruning sparsity도 warm up 방식을 사용하는 것이 도움이 된다. optimizer가 적응하는데 도움을 준다.
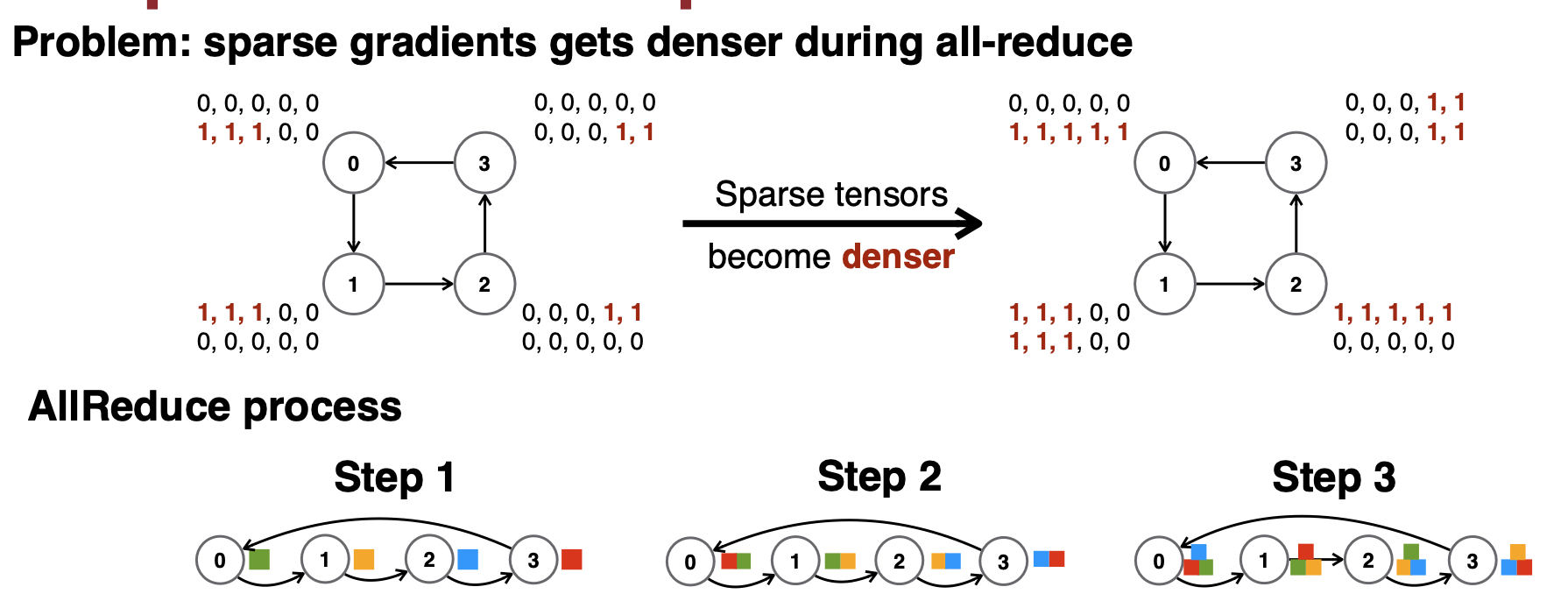
pruning 방식의 문제점은, 여러 node끼리 정보를 교환하는 all-reduce 과정을 거치면서 pruning 하는 의미가 없어진다는 것이다(더 dense해진다)
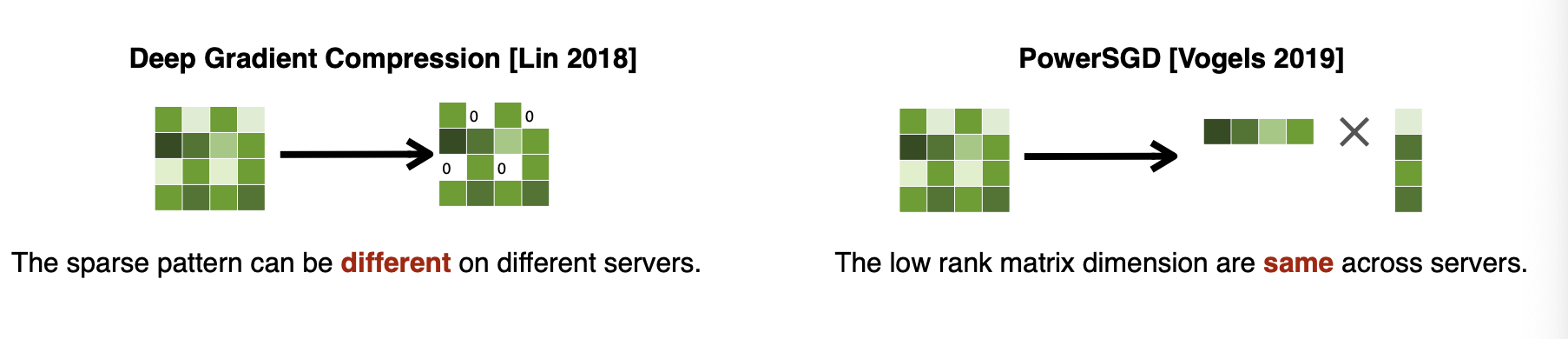
이런 방식을 해결하기 위해 sparse하게 만드는 것이 아니라 low rank matrix를 사용하는 방식을 사용하기도 한다.
10.2. Gradient Quantization: 1-Bit SGD, TernGrad
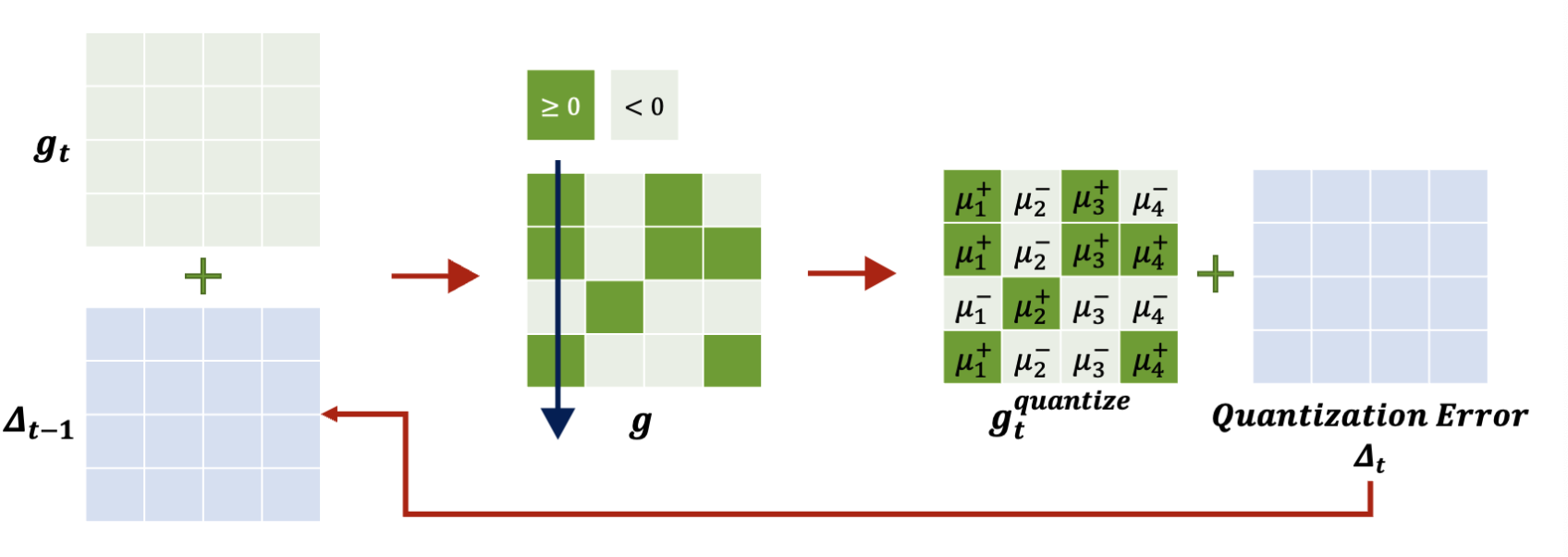
quantization 방법을 소개하면, 1bit-SGD 방식이 있다. 이는 0보다 크면 +, 아니면 -로 둔 뒤 scaling factor(u1~u4)를 colum마다 적용하는 방식이다. quantization error는 locally하게 집계되고, quantize된 gradient만 전송된다.
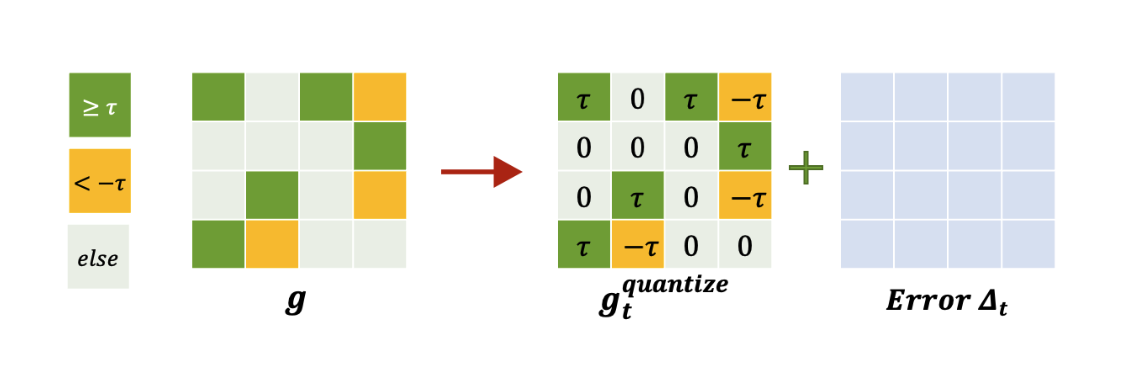
비슷한 방식으로, threshold를 특정 값으로 두고 quantize하는 방식도 있다.
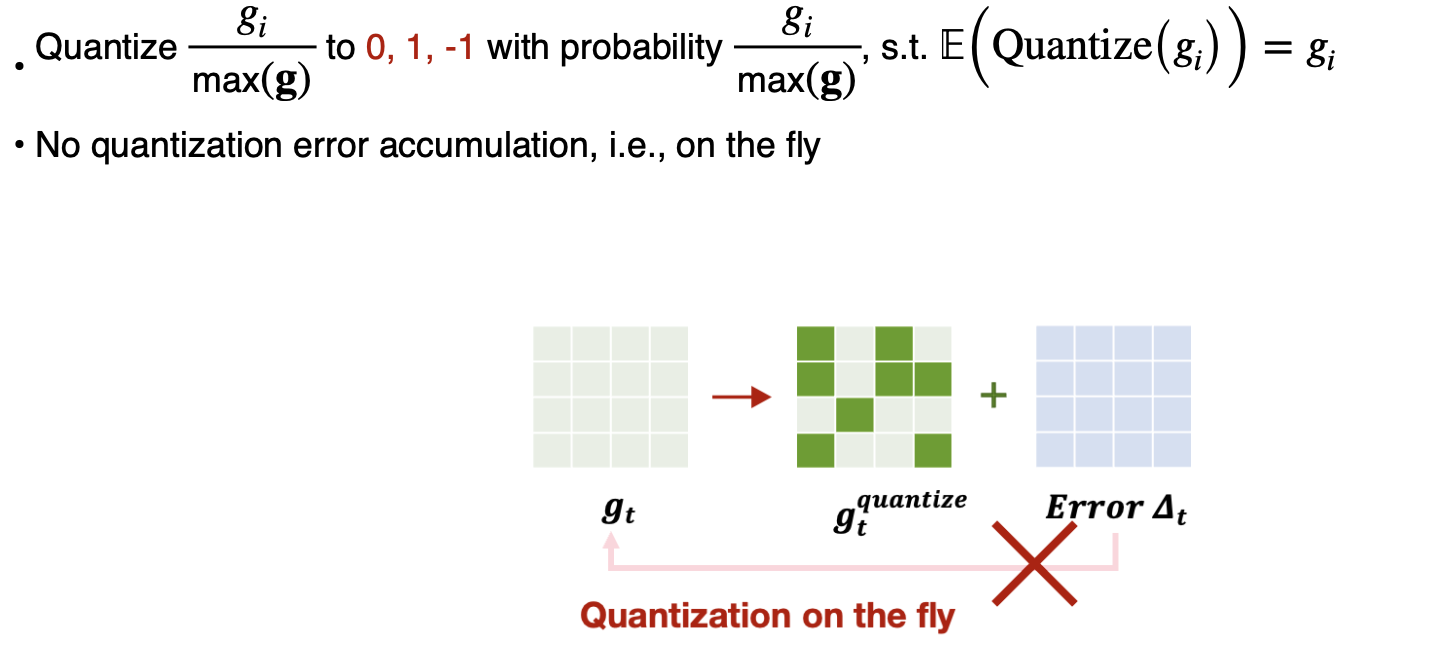
Terngrad는 확률값에 따라 0, 1, -1 중 하나로 양자화 하는 방식이다.
11. Delayed gradient update: overcome the latency bottleneck
pruning이나 quantize 방식으로 bandwith문제는 해결했지만, latency는 이런 방법들로는 해결할 수 없다.
거리나 신호 혼잡같은 물리적인 이유가 있다.
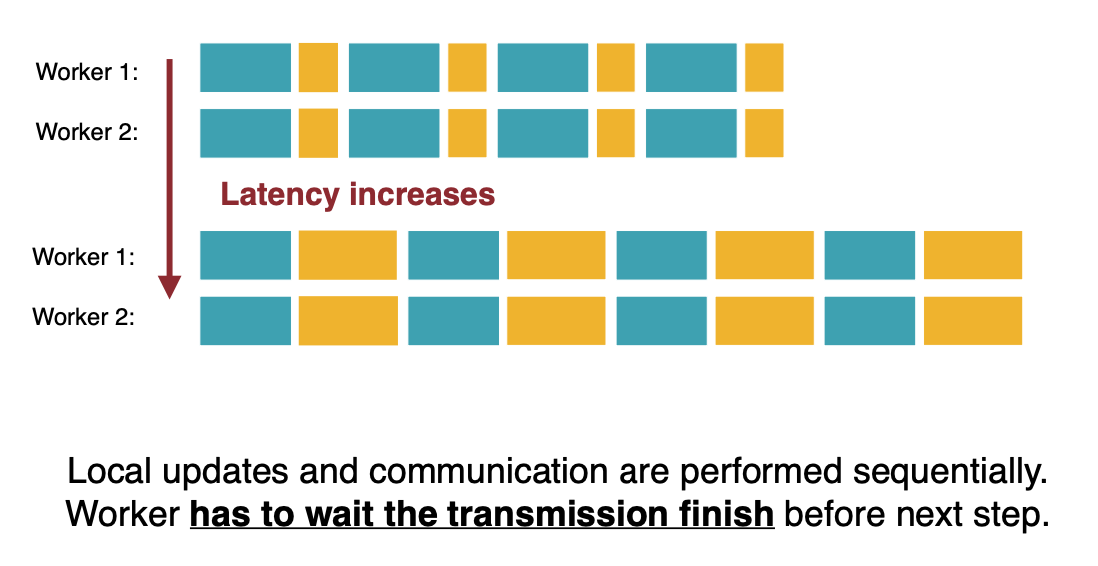
기본적인 분산 처리 방식에서는, 계산->전송->계산 방식으로 이루어지는데, 이런 구조에서는 전송 시간이 늘어나면 그 즉시 전체 시간이 늘어난다
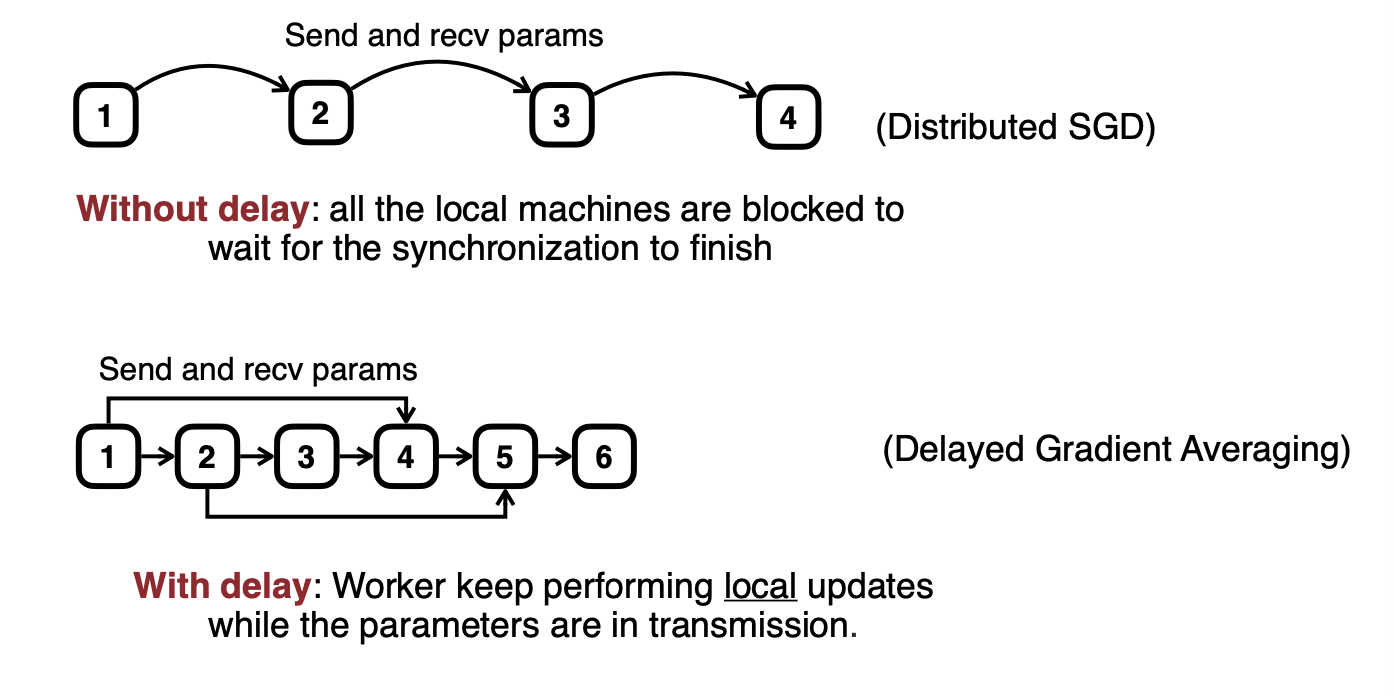
그래서 전송과 계산을 동시에 진행하면, 어느정도 시간을 절약할 수 있다.
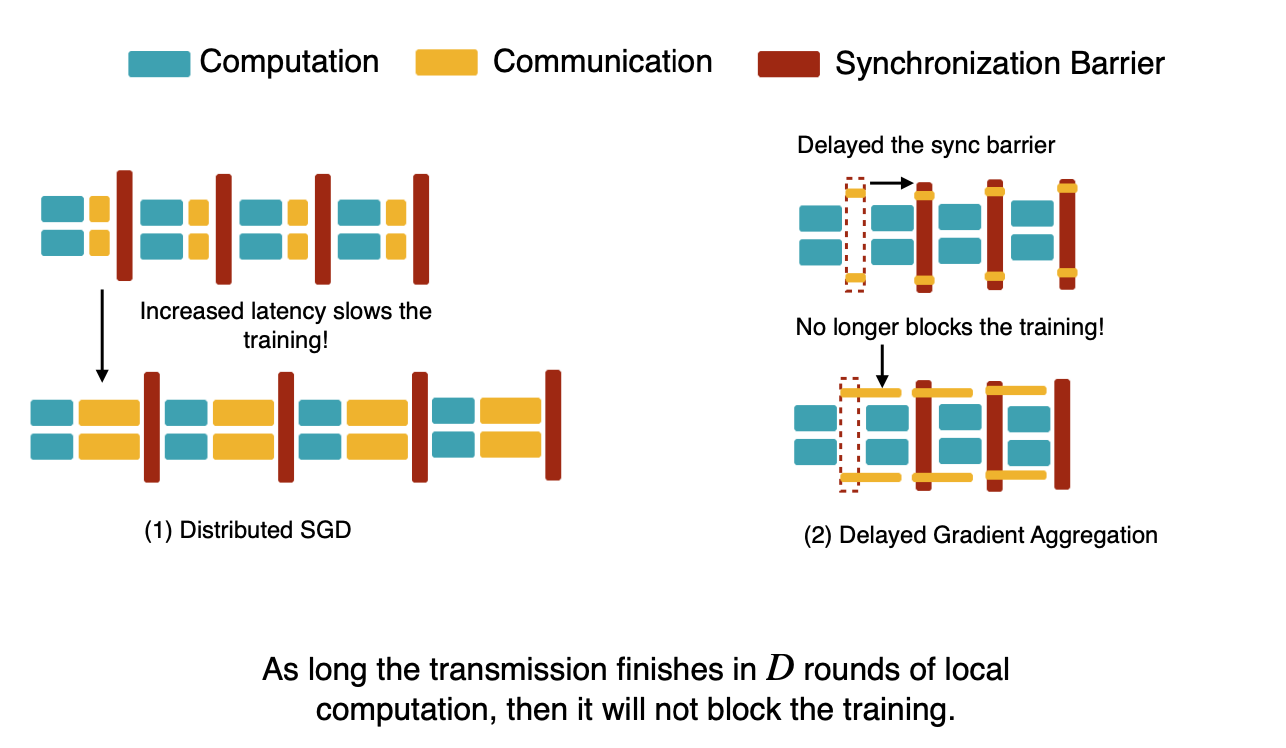
전송 시간이 어느정도 늘어나더라도, training을 방해하지 않는다.
여기까지 tinyML 17,18강인 distributed learning에 관한 정리였다. 실제로 모델이 점점 커지는 만큼, 혹은 edge 환경에서 개개인의 데이터로 학습을 하는 경우에도 분산 방식이 유용하게 사용된다. 하지만 분산 방식에서는 개인의 데이터가 유출될 위험이 존재하기도 한다. 그런 방법이 무엇인지, 어떻게 막을 수 있는지는 뒤의 강의에서 다루니, 관심있는 분은 뒤의 포스팅도 찾아보시길 바란다.