🧑🏫 Lecture 4
이전 포스팅에서 Pruning에 대해서 배웠었다. 이번에는 Pruning에 대한 남은 이야기인 Pruning Ratio를 정하는 방법, Fine-tuning 과정에 대해 알아보고, 마지막으로 Sparsity를 위한 System Support에 대해 알아보고자 한다.
1. Pruning Ratio
Pruning을 하기 위해서 어느 정도 Pruning을 해야 할지 어떻게 정해야 할까?
즉, 다시 말해서 몇 % 정도 그리고 어떻게 Pruning을 해야 좋을까?
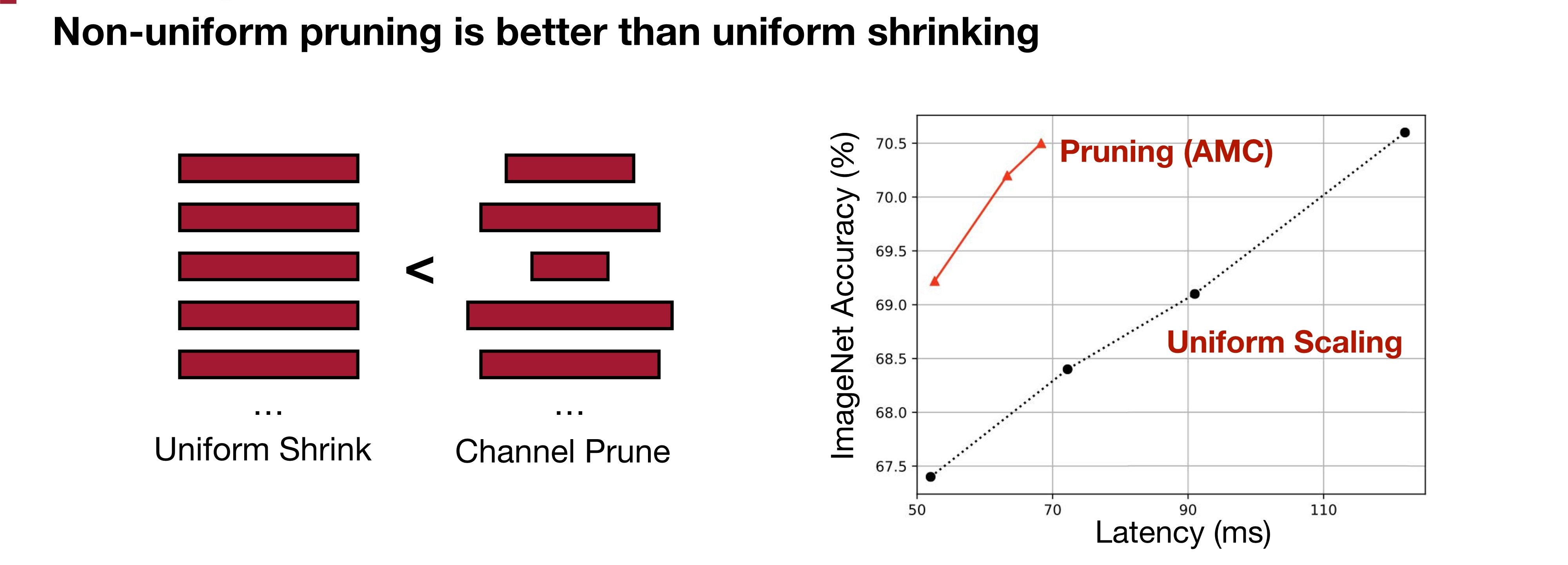
우선 Channel 별 Pruning을 할 때, Channel 구분 없이 동일한 Pruning 비율(Uniform)을 적용하면 성능이 좋지 않다. 오른쪽 그래프에서 지향해야 하는 방향은 Latency는 적게, Accuracy는 높게이므로 왼쪽 상단의 영역이 되도록 Pruning을 진행해야 한다. 그렇다면 결론은 Channel 별 구분을 해서 어떤 Channel은 Pruning 비율을 높게, 어떤 Channel은 Pruning 비율을 낮게 해야 한다는 이야기가 된다.
1.1 Sensitiviy Analysis
Channel 별 구분을 해서 Pruning을 한다는 기본 아이디어는 아래와 같다.
- Accuracy에 영향을 많이 주는 Layer는 Pruning을 적게 해야 한다.
- Accuracy에 영향을 적게 주는 Layer는 Pruning을 많이 해야 한다.
Accuracy를 되도록이면 원래의 모델보다 덜 떨어지게 만들면서 Pruning을 해서 모델을 가볍게 만드는 것이 목표이기 때문에 당연한 아이디어일 것이다. Accuracy에 영향을 많이 준다는 말은 Sensitive한 Layer이다라는 표현으로 다르게 말할 수 있다. 따라서 각 Layer의 Senstivity를 측정해서 Sensitive한 Layer는 Pruning Ratio를 낮게 설계하면 된다.
Layer의 Sensitivity를 측정하기 위해 Sensitivity Analysis를 진행해보자. 당연히 특정 Layer의 Pruning Ratio가 높을 수록 weight가 많이 가지치기 된 것이므로 Accuracy는 떨어지게 된다.
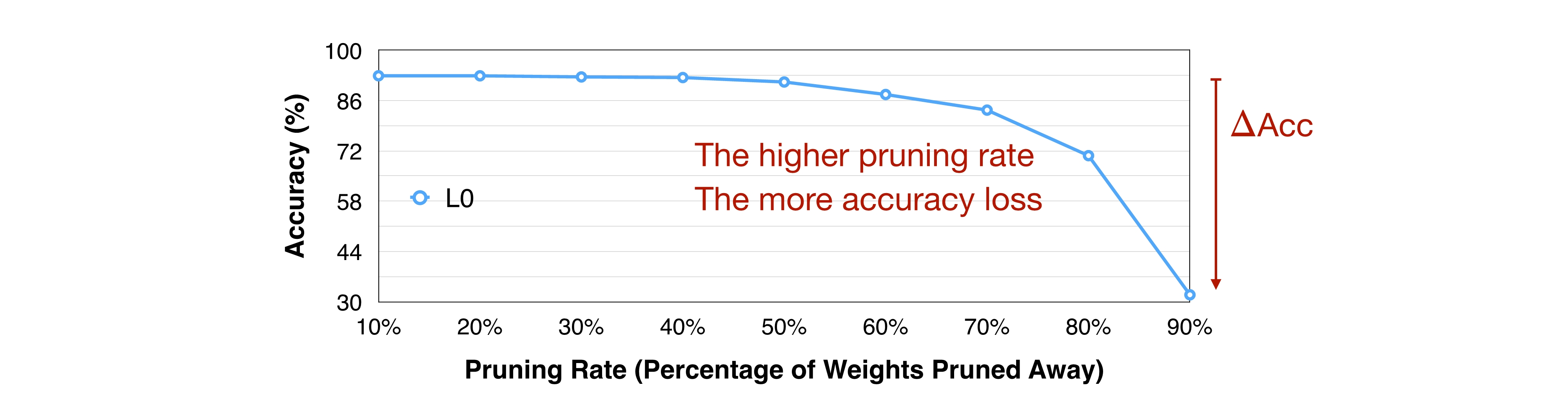
Pruning Ratio에 의해 Pruned 되는 weight는 이전 강의에서 배운 “Importance(weight의 절댓값 크기)”에 따라 선택된다.
위의 그림에서 처럼 Layer 0(L0)만을 가지고 Pruning Ratio를 높여가면서 관찰해보면, 약 70% 이후부터는 Accuracy가 급격하게 떨어지는 것을 볼 수 있다. L0에서 Ratio를 높여가며 Accuracy의 변화를 관찰한 것처럼 다른 Layer들도 관찰해보자.
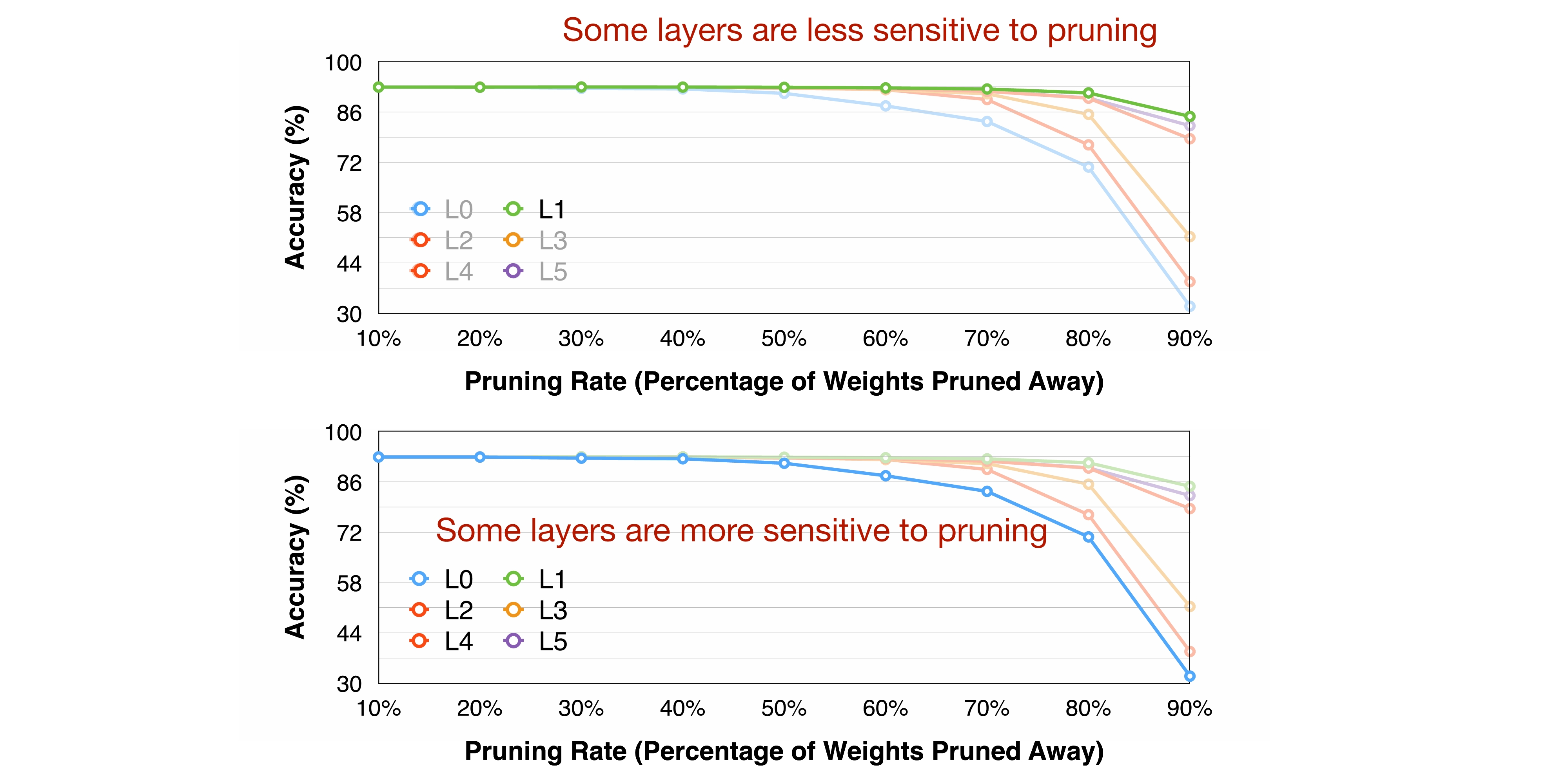
L1은 다른 Layer들에 비해 상대적으로 Pruning Ratio를 높여가도 Accuracy의 떨어지는 정도가 약한 반면, L0는 다른 Layer들에 비해 상대적으로 Pruning Ratio를 높여가면 Accuracy의 떨어지는 정도가 심한 것을 확인할 수 있다. 따라서 L1은 Sensitivity가 높다고 볼 수 있으며 Pruning을 적게해야 하고, L0은 Sensitivity가 낮다고 볼 수 있으며 Pruning을 많게해야 함을 알 수 있다.
여기서 Sensitivity Analysis에서 고려해야할 몇가지 사항들에 대해서 짚고 넘어가자.
- Sensitivity Analysis에서 모든 Layer들이 독립적으로 작동한다는 것을 전제로 한다. 즉,
L0의 Pruning이L1의 효과에 영향을 주지 않는 독립성을 가진다는 것을 전제로 한다. - Layer의 Pruning Ratio가 동일하다고 해서 Pruned Weight수가 같음을 의미하지 않는다.
- 100개의 weight가 있는 layer의 10% Pruning Ratio 적용은 10개의 weight가 pruned 되었음을 의미하고, 500개의 weight가 있는 layer의 10% Pruning Ratio 적용은 50개의 weight가 pruned 되었음을 의미한다.
- Layer의 전체 크기에 따라 Pruning Ratio의 적용 효과는 다를 수 있다.
Sensitivity Analysis까지 진행한 후에는 보통 사람이 Accuracy가 떨어지는 정도, threshold를 정해서 Pruning Ratio를 정한다.
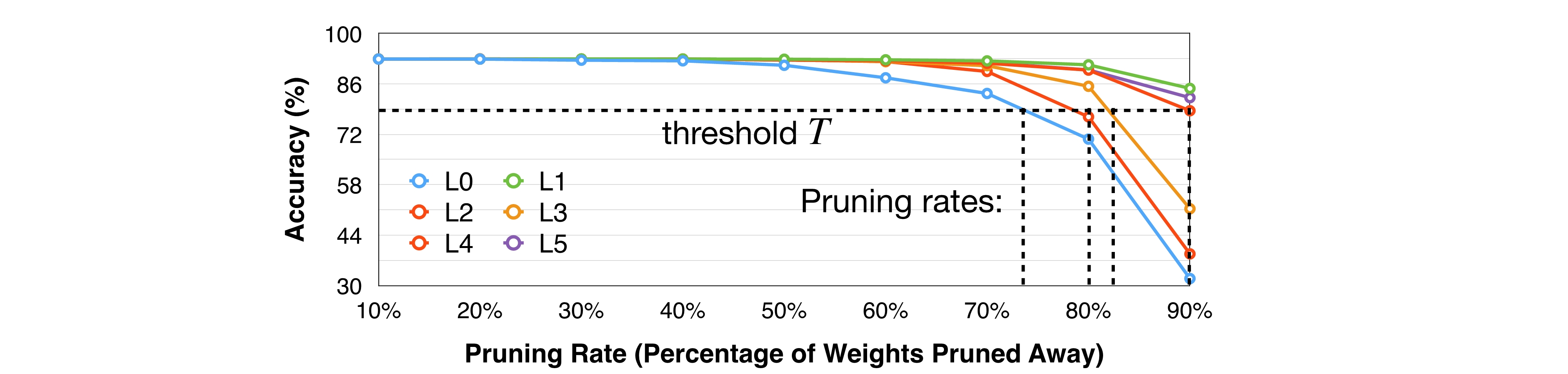
위 그래프에서는 Accuracy가 약 75%수준으로 유지되는 threhsold \(T\) 수평선을 기준으로 L0는 약 74%, L4는 약 80%, L3는 약 82%, L2는 90%까지 Pruning을 진행해야 겠다고 정한 예시를 보여준다. 민감한 layer인 L0는 상대적으로 Pruning을 적게, 덜 민감한 layer인 L2는 Pruning을 많게 하는 것을 확인할 수 있다.
물론 사람이 정하는 threshold는 개선의 여지가 물론 있다. Pruning Ratio를 좀 더 Automatic하게 찾는 방법에 대해 알아보자.
1.2 AMC
AMC는 AutoML for Model Compression의 약자로, 강화학습(Reinforcement Learning) 방법으로 최적의 Pruning Ratio를 찾도록 하는 방법이다.
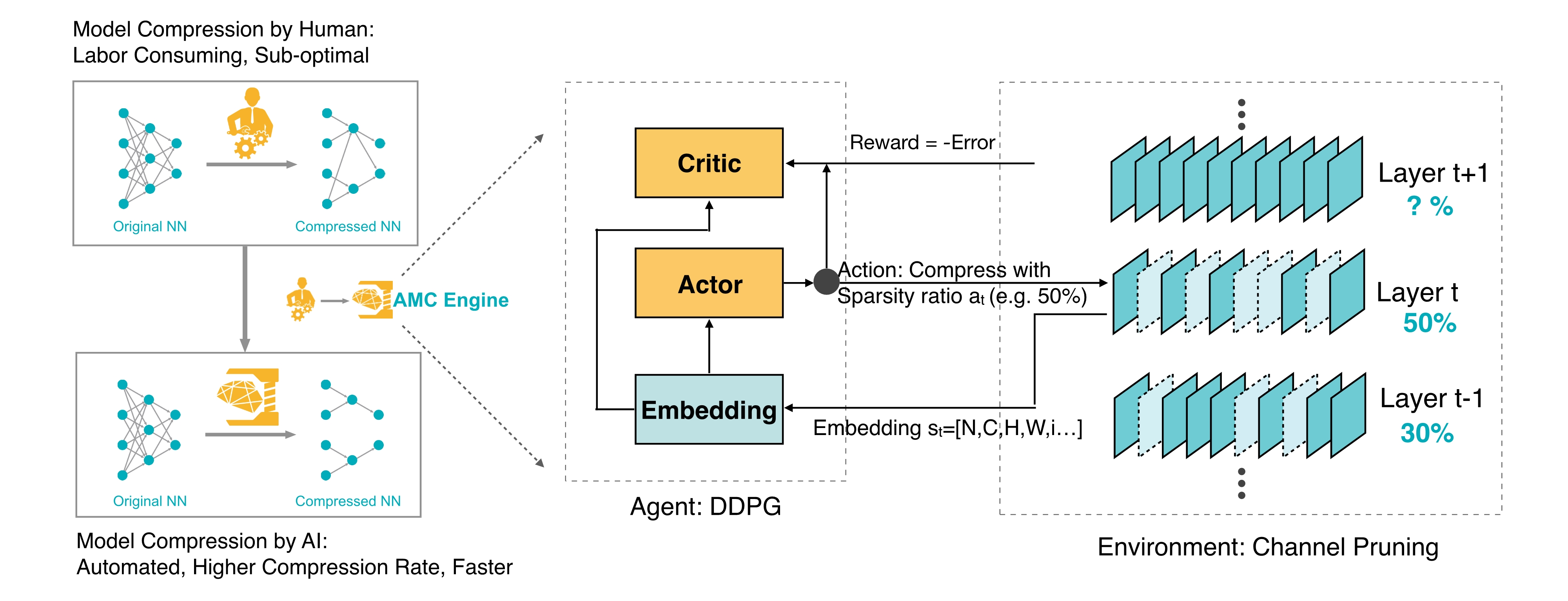
AMC의 구조는 위 그림과 같다. 강화학습 알고리즘 계열 중, Actor-Critic 계열의 알고리즘인 Deep Deterministic Policy Gradient(DDPG)을 활용하여 Pruning Ratio를 정하는 Action을 선택하도록 학습한다. 자세한 MDP(Markov Decision Process) 설계는 아래와 같다.

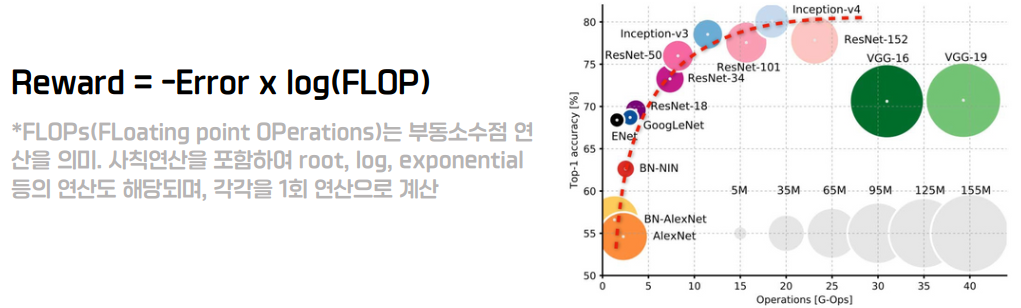
강화학습 Agent의 학습 방향을 결정하는 중요한 Reward Function은 모델의 Accuracy를 고려해서 Error를 줄이도록 유도할 뿐만 아니라 Latency를 간접적으로 고려할 수 있도록 모델의 연산량을 나타내는 FLOP를 적게 하도록 유도하도록 설계한다. 오른쪽에 모델들의 연산량 별(Operations) Top-1 Accuracy 그래프를 보면 연산량이 많을수록 로그함수처럼 Accuracy가 증가하는 것을 보고 이를 보고 반영한 부분이라고 볼 수 있다.
이렇게 AMC로 Pruning을 진행했을 때, Human Expert가 Pruning 한 것과 비교해보자. 아래 모델 섹션별 Density 히스토그램 그래프에서 Total을 보면, 동일 Accuracy가 나오도록 Pruning을 진행했을 때 AMC로 Pruning을 진행한 것(주황색)이 Human Expert Pruning 모델(파란색)보다 Density가 낮은 것을 확인할 수 있다. 즉, AMC로 Pruning 진행했을 때 더 많은 weight를 Pruning 더 가벼운 모델을 가지고도 Accuracy를 유지했다고 볼 수 있다.
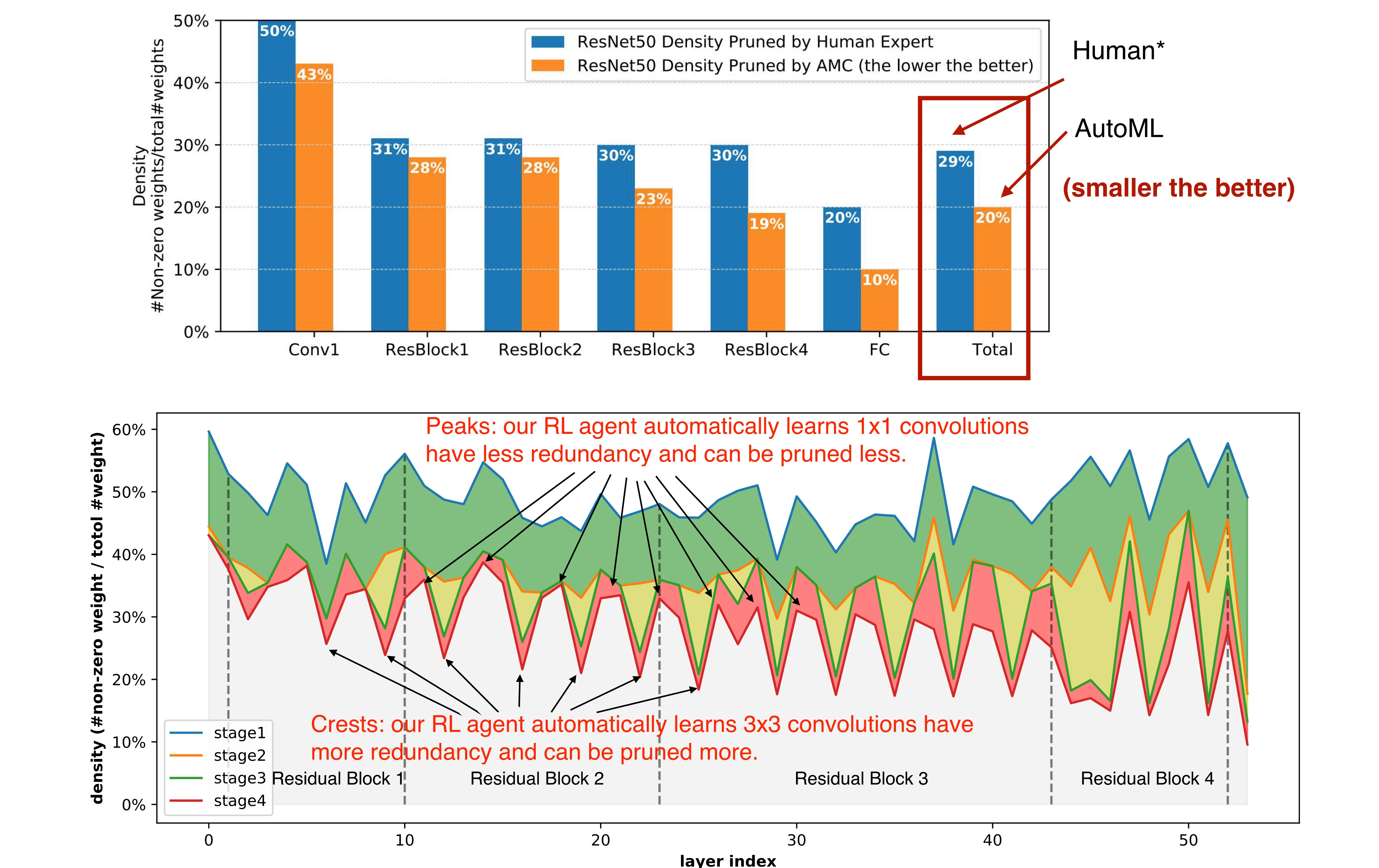
두번째 꺾은 선 그래프에서 AMC를 가지고 Pruning과 Fine-tuning을 번갈아 가며 여러 스텝으로 진행해가면서 관찰한 것을 조금 더 자세히 살펴보자. 각 Iteration(Pruning+Fine-tuning)을 stage1, 2, 3, 4로 나타내어 plot한 것을 보면, 1x1 conv보다 3x3 conv에서 Density가 더 낮은 것을 확인할 수 있다. 즉, 3x3 conv에서 1x1 conv보다 Pruning을 많이 한 것을 볼 수 있다. 이를 해석해보자면, AMC가 3x3 conv을 Pruning하면 9개의 weight를 pruning하고 이는 1x1 conv pruning해서 1개의 weight를 없애는 것보다 한번에 더 많은 weight 수를 줄일 수 있기 때문에 3x3 conv pruning을 적극 활용했을 것으로 볼 수 있다.
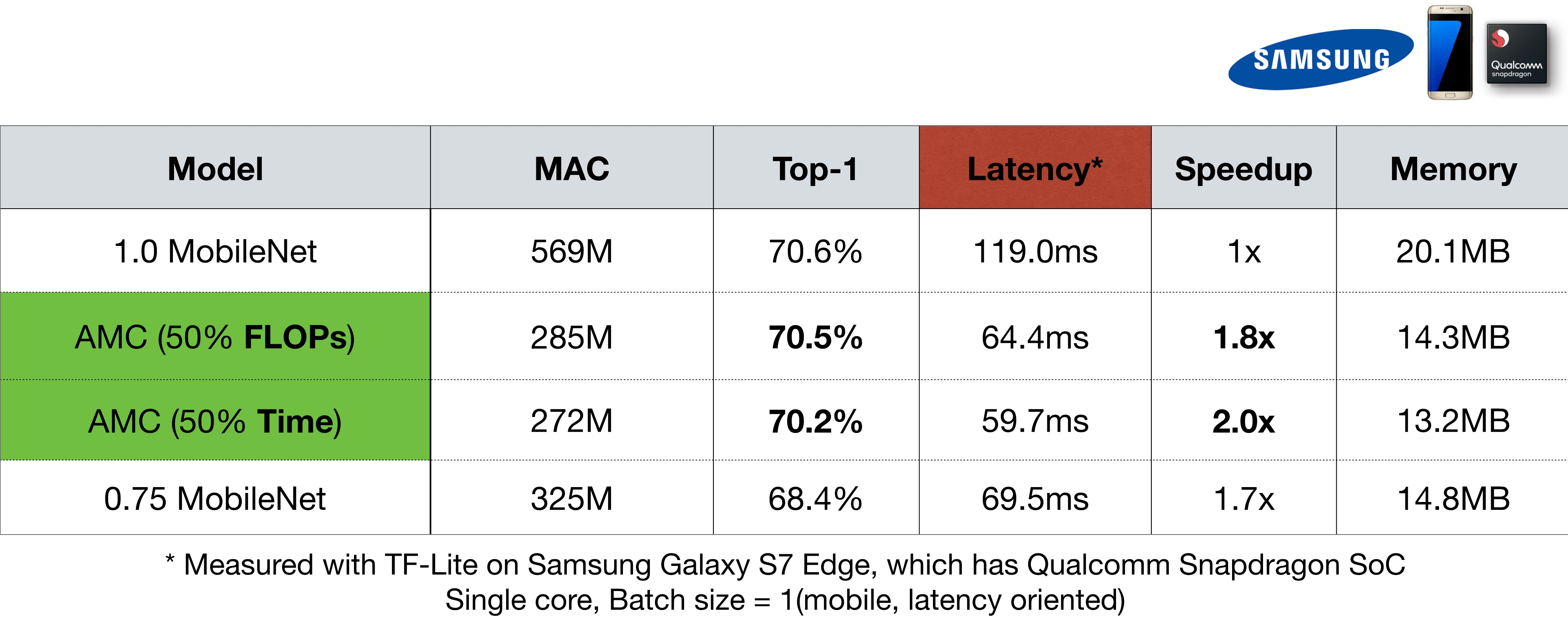
이 AMC 실험 결과표에서 보면, FLOP와 Time 각각 50%로 줄인 AMC 모델 둘다 Top-1 Accuracy가 기존의 1.0 MobileNet의 Accuracy보다 약 0.1~0.4% 정도만 줄고 Latency나 SpeedUp이 효율적으로 조정된 것을 확인할 수 있다.
0.75 MobileNet의 SpeedUp이 왜 1.7x 인가요?
결과표에서 0.75 MobileNet은 25%의 weight를 감소시킨 것이기 때문에 SpeedUp이 \(\frac{4}{3} \simeq 1.3\)x이어야 한다고 생각할 수 있다. 하지만 연산량은 quadratic하게 감소하게 되기 때문에 \(\frac{4}{3} \cdot \frac{4}{3} \simeq 1.7\)x로 SpeedUp이 된다.
1.3 NetAdapt
또 다른 Pruning Ratio를 정하는 기법으로 NetAdapt이 있다. Latency Constraint를 가지고 layer마다 pruning을 적용해본다. 예를 들어, 줄일 목표 latency 량을 lms로 정하면, 10ms → 9ms로 줄 때까지 layer의 pruning ratio를 높여가는 방법이다.
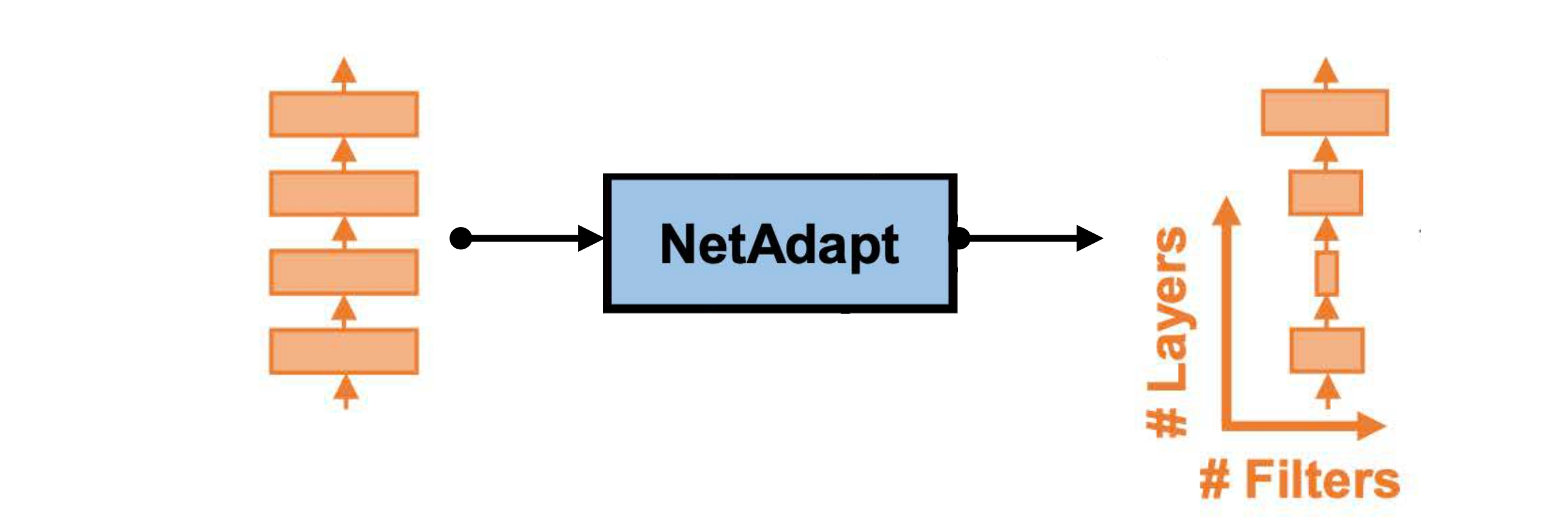
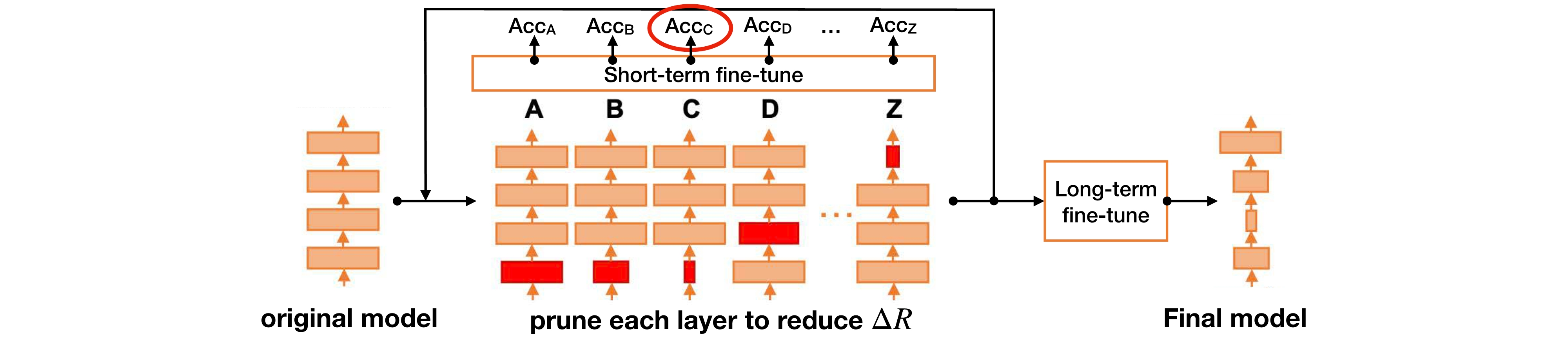
NetAdapt의 전체적인 과정은 아래와 같이 진행된다. 기존 모델에서 각 layer를 Latency Constraint에 도달하도록 Pruning하면서 Accuracy(\(Acc_A\)등)을 반복적으로 측정한다.
- 각 layer의 pruning ratio를 조절한다.
Short-termfine tuning을 진행한다.- Latency Constraint에 도달했는지 확인한다.
- Latency Constraint 도달하면 해당 layer의 최적의 Pruning ratio로 판단한다.
- 각 layer의 최적 Pruning ratio가 정해졌다면 마지막으로
Long-termfine tuning을 진행한다.
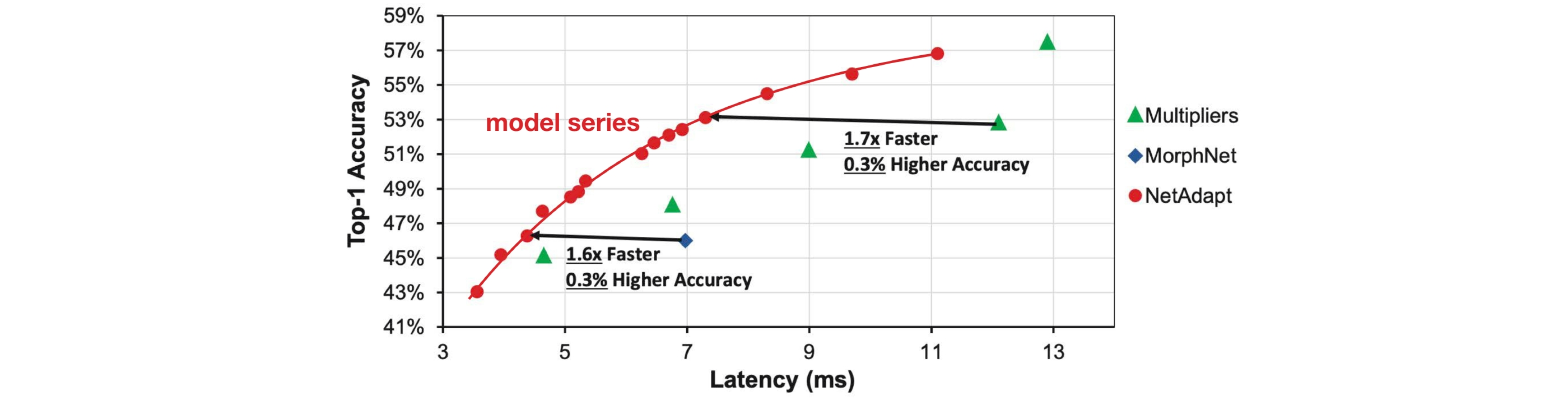
이와 같이 NetAdapt의 과정을 진행하면 아래와 같은 실험 결과를 볼 수 있다. Uniform하게 Pruning을 진행한 Multipilers보다 NetAdapt가 1.7x 더 빠르고 오히려 Accuracy는 약 0.3% 정도 높은 것을 알 수 있다.
2. Fine-tuning/Train
Prunned 모델의 퍼포먼스를 향상하기 위해서는 Pruning를 진행하고 나서 Fine-tuning 과정이 필요하다.
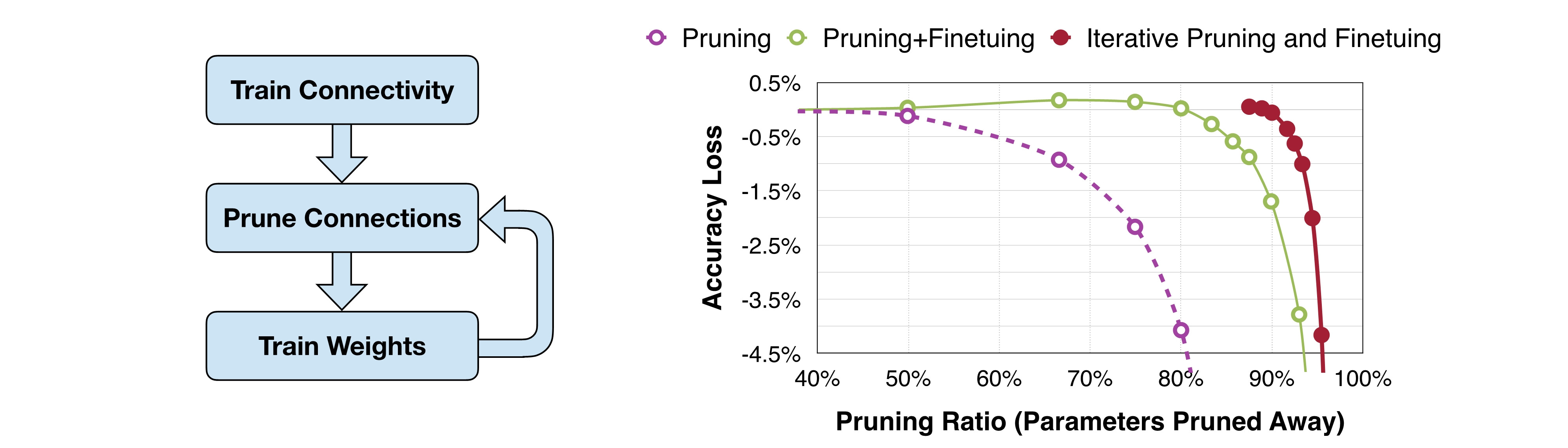
2.1 Iterative Pruning
보통 Pruned 모델의 Fine-tuning 과정에서는 기존에 학습했던 learning rate보다 작은 rate를 사용한다. 예를들어 기존의 모델을 학습할 때 사용한 learning rate의 \(1/100\) 또는 \(1/10\)을 사용한다. 또한 Pruning 과정과 Fine-tuning 과정은 1번만 진행하기보다 점차적으로 pruning ratio를 늘려가며 Pruning, Fine-tuning을 번갈아가며 여러번 진행하는게 더 좋다.
2.2 Regularization
TinyML의 목표는 가능한 많은 weight들을 0으로 만드는 것으로 생각할 수 있다. 그래야 모델을 가볍게 만들 수 있기 때문이다. 그래서 Regularization 기법을 이용해서 모델의 weight들을 0으로, 혹은 0과 가깝게 작은 값을 가지도록 만든다. 작은 값의 weight가 되도록 하는 이유는 0과 가까운 작은 값들은 다음 layer들로 넘어가면서 0이 될 가능성이 높아지기 때문이다. 기존의 딥러닝 모델들의 과적합(Overfitting)을 막기 위한 Regularization 기법들과 다르지 않으나 의도와 목적은 다른 것을 짚어볼 수 있다.
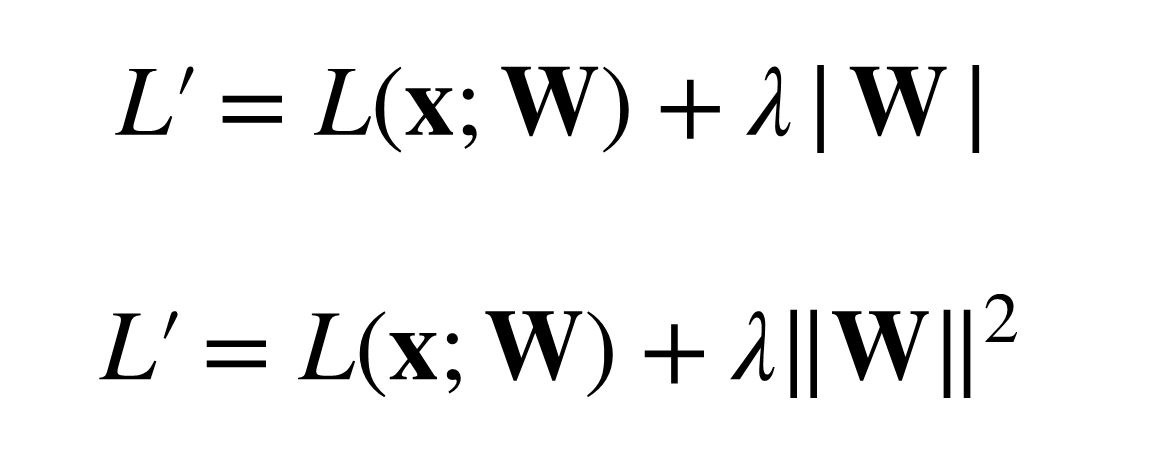
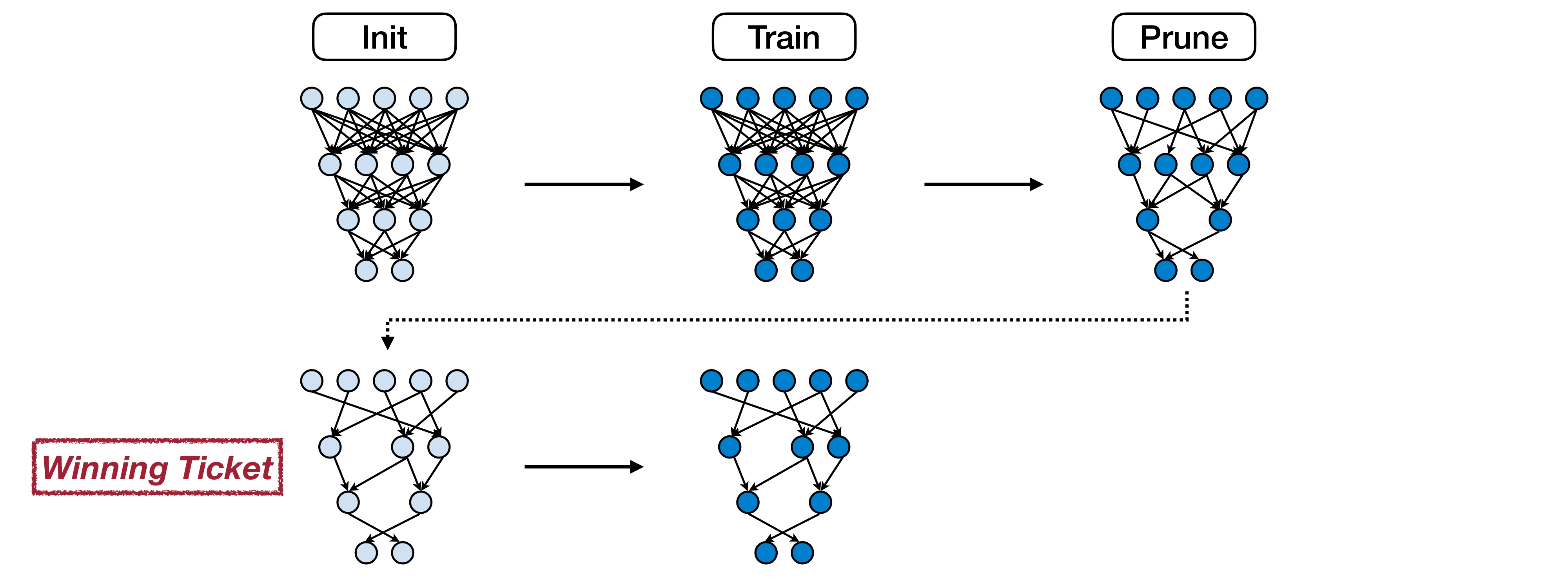
2.3 The Lottery Ticket Hypothesis
2019년 ICLR에서 발표된 논문에서 Jonathan Frankle과 Michael Carbin이 소개한 The Lottery Ticket Hypothesis(LTH)은 심층 신경망(DNN) 훈련에 대한 흥미로운 아이디어를 제안한다. 무작위로 초기화된 대규모 신경망 내에 더 작은 하위 네트워크(Winning Ticket)가 존재한다는 것을 말한다. 이 하위 네트워크는 처음부터 별도로 훈련할 때 원래 네트워크의 성능에 도달하거나 능가할 수 있다. 이 가설은 이러한 Winning Ticket이 학습하는 데 적합한 초기 가중치를 갖는다고 가정한다.
3. System Support for Sparsity
DNN을 가속화 시키는 방법은 크게 3가지, Sparse Weight, Sparse Activation, Weight Sharing이 있다. Sparse Weight, Sparse Activation은 Pruning이고 Weight Sharing은 Quantization의 방법이다.

- Sparse Weight: Weight를 Pruning하여 Computation은 Pruning Ratio에 대응하여 빨라진다. 하지만 Memory는 Pruning된 weight의 위치를 기억하기 위한 memory 용량이 필요하므로 Pruning Ratio에 비례하여 줄진 않는다.
- Sparse Activation: Weight를 Pruning하는 것과 다르게 Activation은 Test Input에 따라 dynamic 하므로 Weight를 Pruning하는 것보다 Computation이 덜 줄어든다.
- Weight Sharing: Quantization 방법으로 32-bit data를 4-bit data로 변경함으로써 8배의 memory 절약을 할 수 있다.
3.1 EIE
Efficient Inference Engine은 기계 학습 모델을 실시간으로 실행하기 위해 최적화된 소프트웨어 라이브러리나 프레임워크를 말한다. Processing Elements(PE)의 구조
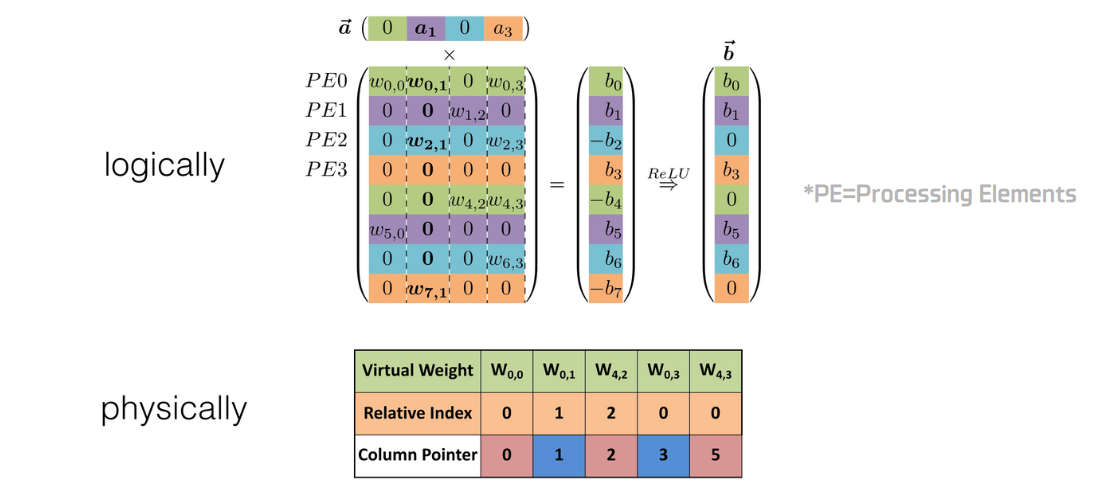
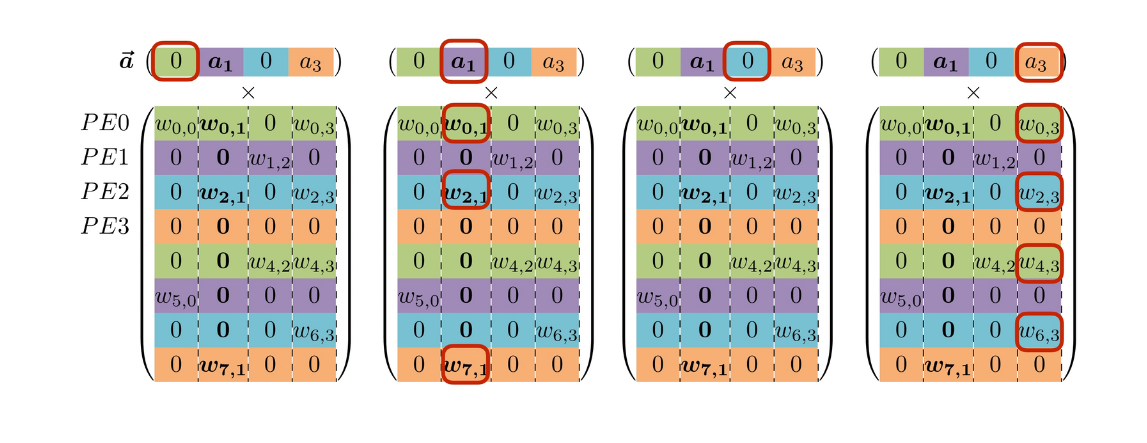
아래 그림에서 Input별(\(\vec{a}\)) 연산은 아래와 같이 Input이 0일 때는 skip되고 0이 아닐 때는 prunning 되지 않은 weight와 연산이 진행된다.
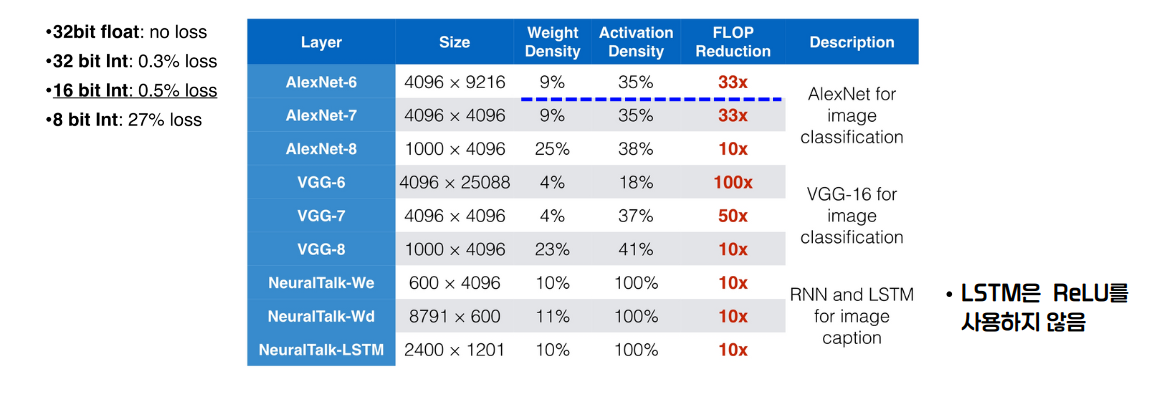
EIE 실험은 가장 loss가 적은 data 자료형인 16 bit Int형을 사용했다.(0.5% loss) AlexNet이나 VGG와 같이 ReLU Activation이 많이 사용되는 모델들은 경량화가 많이 된 반면, RNN와 LSTM이 사용된 NeuralTalk 모델들 같은 경우에는 ReLU를 사용하지 않아 경량화될 수 있는 부분이 없어 Activation Density가 100%인 것을 확인할 수 있다.
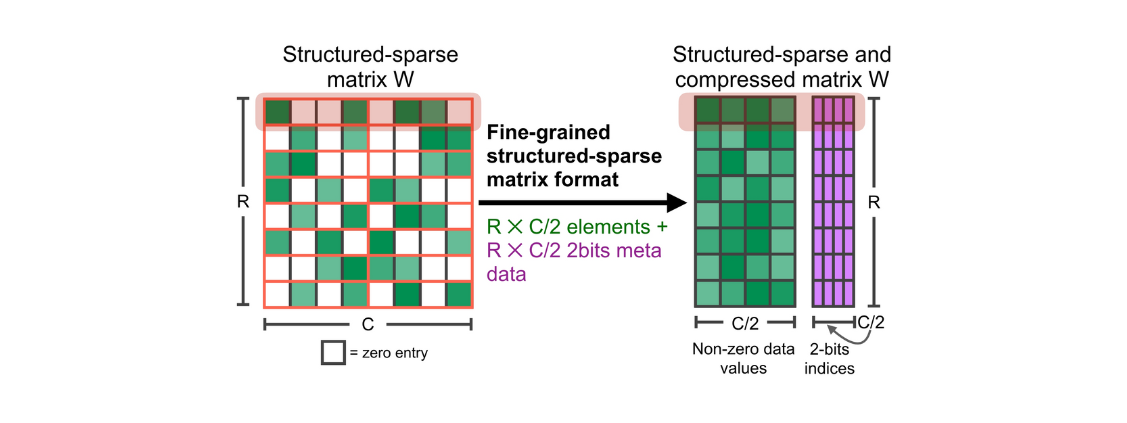
3.2 M:N Weight Sparsity
이 방법은 Nvidia 하드웨어의 지원이 필요한 방법으로 보통 2:4 Weight Sparsity를 사용한다. 왼쪽의 Sparse Matrix를 재배치해서 Non-zero data matrix와 인덱스를 저장하는 Index matrix를 따로 만들어서 저장한다.
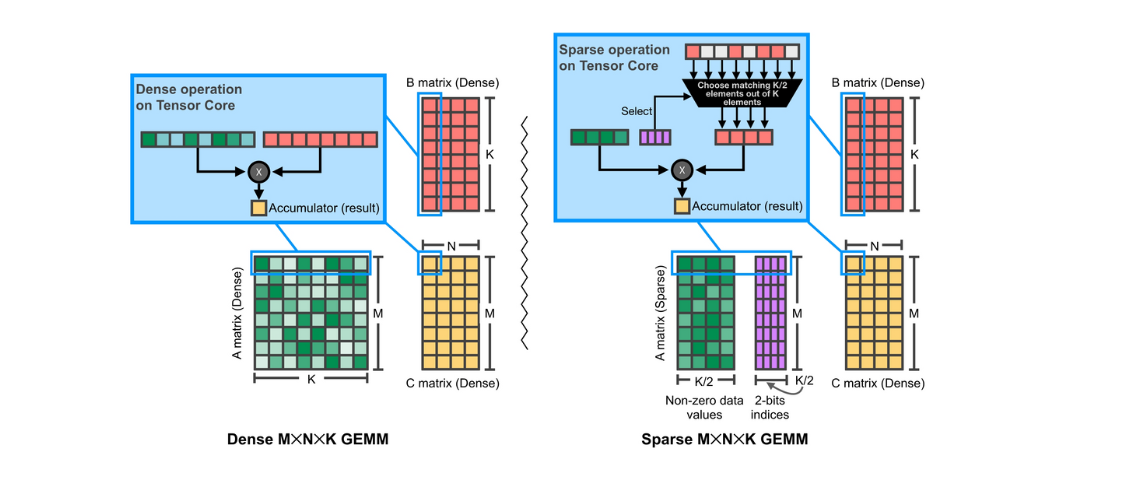
M:N Weight Sparsity 적용하지 않은 Dense GEMM과 적용한 Sparse GEMM을 계산할 때는 아래의 그림과 같은 과정으로 연산이 진행된다.
3.3 Sparse Convolution
Submanifold Sparse Convolutional Networks (SSCN)은 고차원 데이터에서 효율적인 계산을 가능하게 하는 신경망 아키텍처의 한 형태이다. 이 기술은 특히 3D 포인트 클라우드 또는 고해상도 이미지와 같이 대규모 및 고차원 데이터를 처리할 때 중요하다. SSCN의 핵심 아이디어는 데이터의 Sparcity을 활용하여 계산과 메모리 사용량을 크게 줄이는 것이다.

이러한 Sparse Convolution은 기본 Convolution과 비교했을 때 아래 그림과 같이 나타내볼 수 있다.
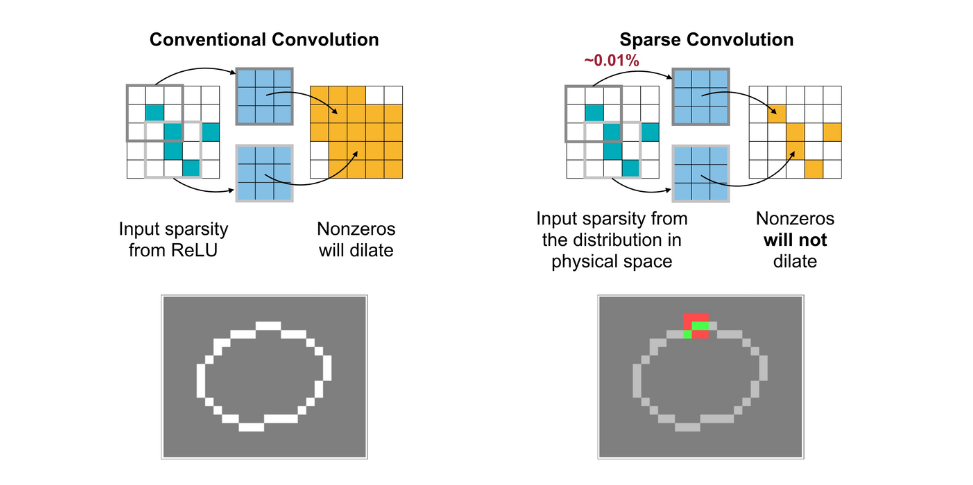
연산 과정을 비교해보기 위해 Input Point Cloud(\(P\)), Feature Map(\(W\)), Ouput Point Cloud(\(Q\))를 아래와 같이 있다고 하자. 기존의 Convolution과 Sparse Convolution을 비교해보면 연산량이 9:2로 매우 적은 연산만 필요한 것을 알 수 있다.
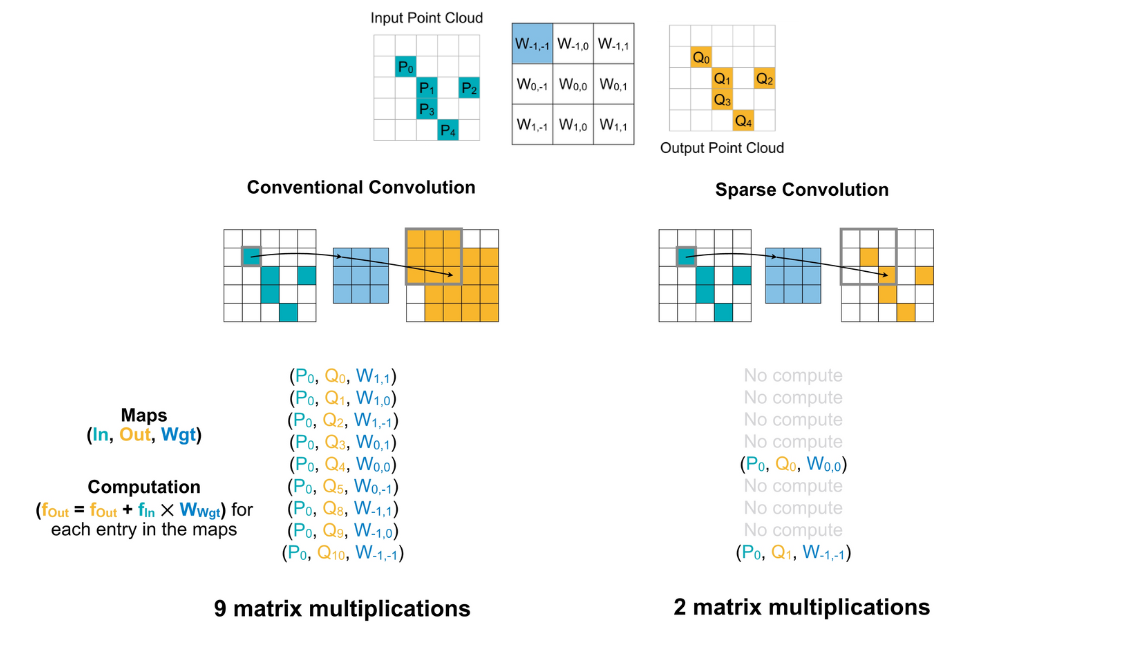
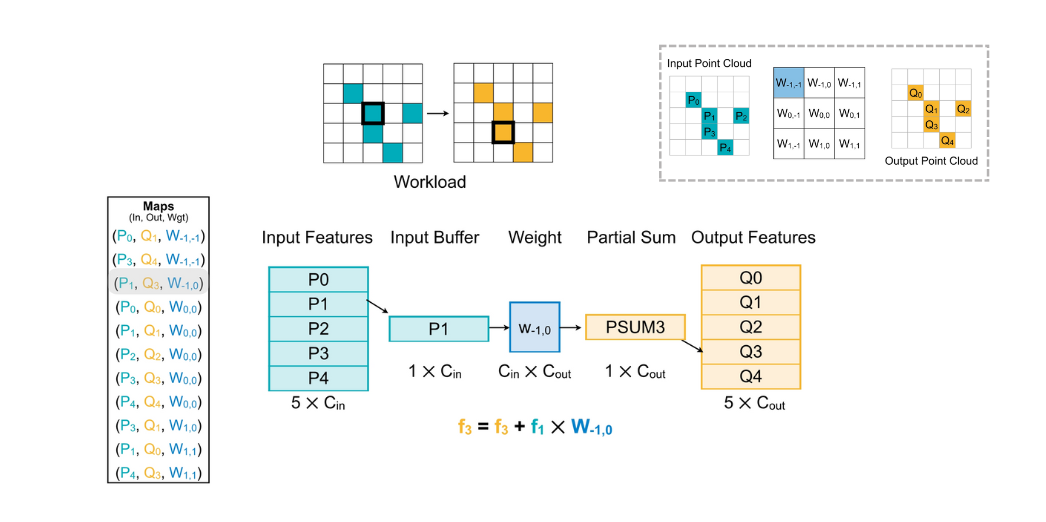
Feature Map(\(W\))을 기준으로 각 weight 마다 필요한 Input data의 크기가 다르다. 예를 들어 \(W_{-1, 0}\)은 \(P1\)과 만의 연산이 진행되므로 \(P1\)만 연산시 불러내게 된다.
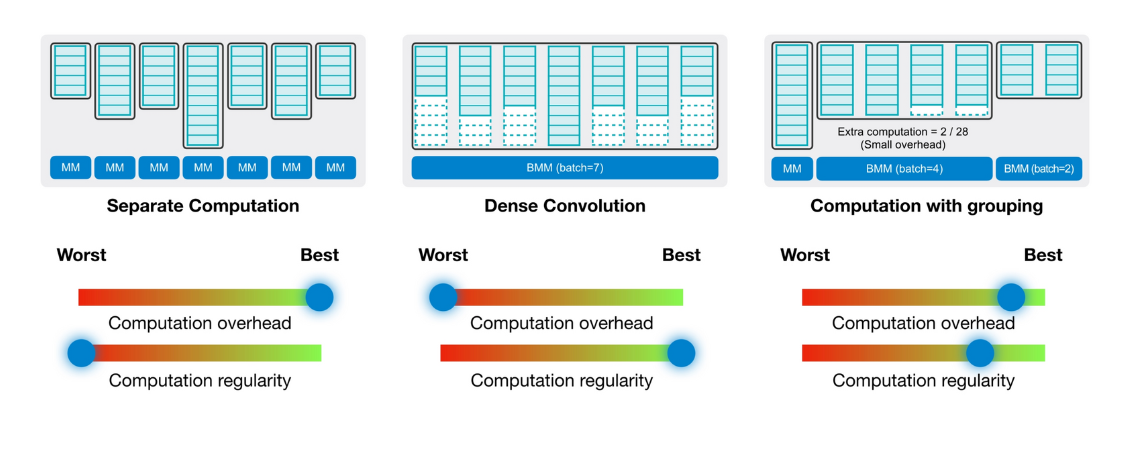
따라서 Feature Map의 \(W\)에 따라 필요한 Input data를 표현하고 따로 computation을 진행하면 아래와 같이 고르지 못한 연산량 분배가 진행되는데(왼쪽 그림) 이는 computation에 overhead는 없지만 regularity가 좋지 않다. 또는 가장 computation이 많은 것을 기준으로 Batch 단위로 계산하게 된다면(가운데 그림) 적은 computation weight에서의 비효율적인 계산 대기시간이 생기므로 overhead가 생긴다. 따라서 적절히 비슷한 연산량을 가지는 grouping을 진행한 뒤 batch로 묶으면 적절히 computation을 진행할 수 있다.(오른쪽 그림)
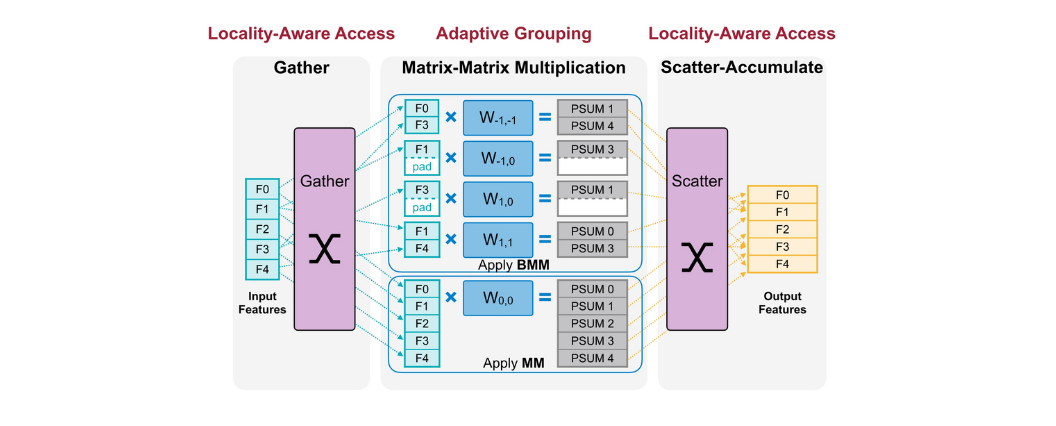
이런 Grouping을 적용한 후 Sparse Convolution을 진행하면 Adaptive Grouping이 적용되어 아래와 같이 진행된다.
여기까지가 2023년도 강의에서 마지막 Sparse Convolution에 대해 설명한 부분을 정리한 부분이다. 하지만 강의에서 설명이 많이 생략되어 있으므로 좀 더 자세한 내용은 Youtube 발표 영상이나 2022년도 강의를 참고하는 것을 권장한다.
4. Reference
- MIT-TinyML-lecture04-Pruning-2
- AMC: Automl for Model Compression and Acceleration on Mobile Devices, 2018
- Continuous control with deep reinforcement learning
- FLOPs란? 딥러닝 연산량에 대해서
- NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications
- The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
- The Lottery Ticket Hypothesis Finding Sparse, Trainable Neural Networks 논문 리뷰
- LLM Inference - HW/SW Optimizations
- Accelerating Sparse Deep Neural Networks
- Submanifold Sparse Convolutional Networks
- TorchSparse: Efficient Point Cloud Inference Engine
- TorchSparse++: Efficient Training and Inference Framework for Sparse Convolution on GPUs
- mit-han-lab/torchsparse
- MLSys’22 TorchSparse: Efficient Point Cloud Inference Engine